关于本书籍
本书籍归纳和总结我本人的一些经验。一些文章资料参考互联网相关内容。
关于我
一个混迹在魔都10多年的资深后端程序员,专注后端高性能,高并发编程。主要涉及编程语言有golang和rust。
联系我
- Github: https://github.com/widaT
- Gitee: https://gitee.com/wida
- mail: wida59@gmail.com
- 微信:

- Go语言学习群:如果过期可加我微信,拉你入群

- Discord:
后端程序员为什么选择go?
后端程序员为什么选择go?
- 语法简单,入门快
- 编译型语言,性能高,语言原生支持并发对后端程序员很有吸引力
- 开发效率高,对于写api的后端程序员来说,golang的开发效率非常接近python,php等脚本语言
- 社区活跃,大牛项目多,高质量的代码都可以任意阅读 (etcd,docker,k8s)
先看一个demo
package main
import (
"io"
"net/http"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "hello, world!\n")
}
func main() {
http.HandleFunc("/", helloHandler)
http.ListenAndServe(":8888", nil)
}
$ go run main.go
这个demo程序实现一个weh服务,浏览器(或者curl)访问 http://localhost:8888/ 会显hello, world
现在来用ab工具来做下基准测试,100个client请求1w次的结果(环境 deepin golang 1.12.1 no nginx)。
$ ab -n 10000 -c 100 http://localhost:8888/
结果
Concurrency Level: 100
Time taken for tests: 0.425 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 1310000 bytes
HTML transferred: 140000 bytes
Requests per second: 23556.40 [#/sec] (mean)
Time per request: 4.245 [ms] (mean)
Time per request: 0.042 [ms] (mean, across all concurrent requests)
Transfer rate: 3013.56 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 0.4 2 4
Processing: 1 2 0.6 2 6
Waiting: 0 2 0.6 2 5
Total: 2 4 0.5 4 8
Percentage of the requests served within a certain time (ms)
50% 4
66% 4
75% 4
80% 4
90% 5
95% 5
98% 6
99% 6
100% 8 (longest request)
现在用php7.2试一下同样的程序效果,比一下(环境 deepin linux nginx1.13.12 100 static php7.2-fpm)
$ ab -n 10000 -c 100 http://localhost/index.php
代码
index.php
<?php
echo "hello world";
结果
Concurrency Level: 100
Time taken for tests: 0.702 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 1490000 bytes
HTML transferred: 110000 bytes
Requests per second: 14237.51 [#/sec] (mean)
Time per request: 7.024 [ms] (mean)
Time per request: 0.070 [ms] (mean, across all concurrent requests)
Transfer rate: 2071.67 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1 0.6 1 4
Processing: 1 4 3.6 3 192
Waiting: 1 4 3.5 3 174
Total: 1 5 3.5 4 192
Percentage of the requests served within a certain time (ms)
50% 4
66% 5
75% 6
80% 6
90% 8
95% 9
98% 12
99% 21
100% 192 (longest reques)
对比结果golang在简单的hello world 程序下qps大概是php7.2的2倍。需要注意的是golang的web程序编译完之后就一个可执行文件,不依赖第三方库,这个可执行文件可以在任意linux系统上运行,不需要而外配置环境变量,这个和c和c++编译完的程序运行方式不太一样。c和c++即使是完全静态编译后,还需要看libc版本是不是和编译时的是否兼容,golang的这种特性,在容器化和微服务化的项目中非常占优。php的程序按照目前的主流架构,是需要nginx和php-fpm两个程序配合,同时把代码部署到站点目录。
改进demo程序 实现全局计数器
package main
import (
"fmt"
"io"
"net/http"
"sync/atomic"
)
var counter int32 = 0
func helloHandler(w http.ResponseWriter, req *http.Request) {
atomic.AddInt32(&counter, 1)
io.WriteString(w, "hello, world!")
}
func getCounter(w http.ResponseWriter, req *http.Request) {
atomic.AddInt32(&counter, 1)
io.WriteString(w, fmt.Sprintf("count : %d", atomic.LoadInt32(&counter)))
}
func main() {
http.HandleFunc("/", helloHandler)
http.HandleFunc("/count", getCounter)
http.ListenAndServe(":8888", nil)
}
两个接口 http://localhost:8888/count 和 http://localhost:8888/ 都会对全局counter 原子性加1,注意golang 的http Handle fution 是运行在golang goroutine(协程)里头,goroutine 是并发运行的,所以对全局的counter修改会有data race(数据竞争),需要加锁或者使用原子操作,这边使用golang的原子操作包实现
$ curl http://localhost:8888/count count : 1
$ curl http://localhost:8888/count hello, world //count : 2
$ curl http://localhost:8888/count count : 3
后续的课程章节会学习到golang的http server是如何运行的。
总结
本节课用一个简单的golang web demo实现了hello world程序,同时实现了一个简单的全局计数器。golang官方包支持http server,对于一些简单的api项目用官方包实现起来十分便捷。
go 环境搭建
golang 安装
linux、macos 安装golang
$ sudo tar -C /usr/local -xzf go$VERSION.$OS-$ARCH.tar.gz
选择适合你的安装的文件。 例如要在Linux上为64位x86安装Go版本1.12.1,则所需的文件称为go1.12.1.linux-amd64.tar.gz。
你可以在/etc/profile(用于系统范围的安装)或$HOME/.profile添加
export PATH=$PATH:/usr/local/go/bin
来将/usr/local/go/bin添加到PATH环境变量
注意:你下次登录计算机之前,对配置文件所做的更改可能不适用。可以使用source $HOME/.profile 来让环境变量立即生效。
windows 平台安装golang
Go项目为Windows用户提供了两个安装选项:其一是通过zip文件解压然后在配置环境变量安装,其二是通过MSI安装程序安装,它会自动配置你的环境变量。
使用MSI安装程序安装
打开MSI文件,然后按照提示安装Go工具。默认情况下,安装程序将Go分发放在c:\Go中。 安装程序应将c:\Go\bin目录放在PATH环境变量中。你可能需要重新启动任何打开的命令提示才能使更改生效。
使用Zip压缩包安装
下载zip文件并将其解压缩到你选择的目录中(我们建议使用c:\Go)。 将Go根目录的bin子目录(例如,c:\Go\bin)添加到PATH环境变量中。
在Windows下设置环境变量
在Windows下,你可以通过“系统”控制面板的“高级”选项卡上的“环境变量”按钮设置环境变量。某些版本的Windows通过“系统”控制面板内的“高级系统设置”选项提供此控制面板。
测试安装结果
创建 gotest 文件夹,创建test.go
package main
import "fmt"
func main() {
fmt.Printf("hello, world\n")
}
cd 到 gotest目录
$ go build -o test test.go
$ ./test
hello, world
如何你看到 "hello, world" 则说明的golang 安装成功了.
go 环境变量
执行
$ go env
主要关注GOPATH、GOBIN 这两个环境变量
GOPATH :安装的时候默认go path 是你的$HOME/go目录下,你可以通过配置你的GOPATH修改默认的go path。 go path下面你主要关注pkg目录,这个目录会保存你go项目的依赖包。 老版本的golang go build 和 go run 都需要在 go path 下才能运行,新版本(1.12以上) 可以在go path外执行。
GOBIN:go install编译后的可执行程序存放路径,一般会把这个路径也加入到系统换变量path里。GOBIN目录如果你没有指定,默认可能是空。为空时可执行文件放在GOPATH目录的bin文件夹中。
使用golang国内代理
由于墙的原因,有些golang的第三方库我们不能直接访问,我们需要设置一个代理。
linux平台 vim /etc/profile添加:
export GOPROXY=https://goproxy.cn,direct
总结
本小节我们介绍了如何安装golang,以及用golang跑了hello world。并且介绍了golang的环境变量,主要关注GOPATH,和GOBIN这两个环境变量。
集成开发工具
golang的开发ide主要有vscode和Goland,由于Goland是付费产品,本小节我们注重介绍vscodegolang环境搭建。
Vscode是微软基于Electron构建的开源编辑器, 是这几年非常流行而且异常强大的编辑器。
安装vscode
vscode官方下载地址:https://code.visualstudio.com/Download
安装golang插件
首先需要安装go插件
安装golang环境其他工具
按Ctrl+Shift+P快捷键,输入go install

然后选择Go:Install/Update Tools会出来如下弹窗:
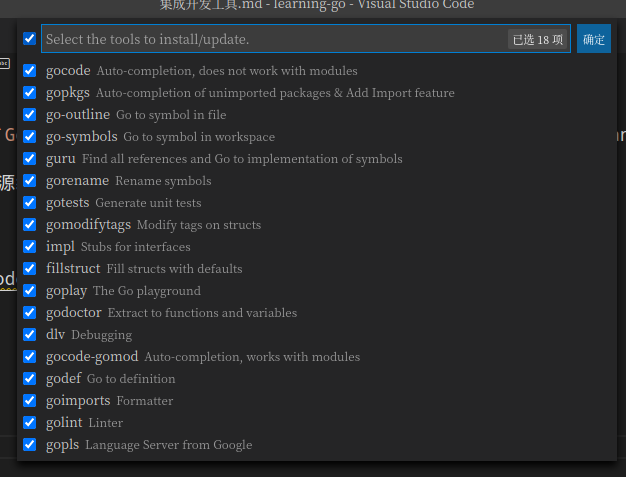
全选安装工具。
安装完成后
到此golang开发环境搭建算是完成了。初学者可以安装vscode插件Code Runer方便调试运行。
第一个go程序
go环境已经搭建好了,接下来我们写一下go程序的hello world
Hello World
go使用go mod 来管理依赖,所以我们先创建一个go语言项目。
$ mkdir helloworld && cd helloworld #创建目录
$ go mod init helloworld #go mod初始化项目,项目名为helloworld
$ touch main.go #创建代码文件
编辑 main.go
package main
import (
"fmt" //导入fmt package
)
func main() {
fmt.Println("hello world")
}
使用 go run 临时编译执行go程序
$ go run main.go
hello world
到此,我们的Go环境基本搭建好了,接下来我们学习过程中需要不断的写练习代码。
Go语言基础
go的25个语言关键字
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
这个25个关键字,不能自定义使用。变量和函数应避免和上面的25个重名。
预定的36个符号
内建常量
true false iota nil
内建类型
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
内建函数
make len cap new append copy close delete
complex real imag
panic recover
go语言命名规范
Go程序员应该使用驼峰命名,当名字由几个单词组成时使用大小写分隔,而不是用下划线分隔。例如“NewObject”或者“newObject”,而非“new_object”.
常量
go使用const定义常量,常量是编译期能确定的结果,在go语言存储在常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串类型。
const a = 1 //a会被自动推断为int型
const b = 1/2
const c="abc"
const length1 = len(c) //ok length=3 len常量结果为常量
const length2 = len(c[:]) //not ok len变量结果为变量
const c1, c2, c3 = "c", 2, "c2" //ok
//使用带()的写法
const (
Monday, Tuesday, Wednesday = 1, 2, 3
Thursday, Friday, Saturday = 4, 5, 6
)
//类似枚举的写法
const(
Monday=1
Tuesday=2
Wednesday=3
)
iota 简化常量写法
//使用iota
const (
Monday = iota + 1 //1
Tuesday //2
Wednesday //3
)
//go使用枚举的真正方式
type MyType int //定义新的类型
const (
Monday MyType = iota + 1 //1
Tuesday //3
Wednesday //3
)
变量
在go语言中使用关键字var声明变量。go的变量在声明后就会有默认的类型零值。
//声明不赋值
var a int //定义了a为int,a的初始值位0
var b bool //定义了b为布尔型,b的初始值为false
var str string //定义了str为布尔型,str的初始值为""(空字符串)
//声明且赋值
var a int=1
var b boo=true
var str string= "str"
//使用类型推断简写
var a =1
var b = true
var str ="str"
//使用var()简写
var(
a = 1
b = true
str ="str"
)
//使用:=简写
a :=1
b := true
str :="str"
a,b,c :=1,true,"str" //ok
//指针类型变量
a := 1
aPtr = &a //aPtr int指针类型
aFunc := func(a int) int { return a}
aFuncPtr := &aFunc //aFuncPtr函数指针类型
需要注意的是go语言中非全局变量,声明了是需要使用的,声明了没使用的变量在编译的时候会报错。
package main
import "fmt"
const s = "testt.org"
var a byte = 1 << len(s) / 128 //a是全局变量 定义没被使用是允许的
func main() {
c := 4 // c declared but not used
b := 9
fmt.Println(b)
}
基本类型
整型
有符号整型 int8、int16、int32和int64 分别对应8、16、32、64 bit大小的有符号整数。
这四种类型的取值范围
- int8(-128 -> 127)
- int16(-32768 -> 32767)
- int32(-2,147,483,648 -> 2,147,483,647)
- int64(-9,223,372,036,854,775,808 -> 9,223,372,036,854,775,807)
无符号整型 uint8,uint16,uint32,uint64分别对应8、16、32、64 bit大小的无符号整数。
- uint8(0 -> 255)
- uint16(0 -> 65,535)
- uint32(0 -> 4,294,967,295)
- uint64(0 -> 18,446,744,073,709,551,615)
在go语言中int是根据平台架构相关的类型,在32位平台int和int32相当,在64位平台int和int64相当。
go语言中还有byte和uintptr类型也是整型, byte是unit8的别名用来表示一个字节,uintptr用来存放指针的类型,和int类型一样跟平台架构相关。
浮点型
go语言中有两张浮点型float32和float64。float32精确到小数点后7 位,float64精确到小数点后15位。
二者的取值范围
- float32(+- 1e-45 -> +- 3.4 * 1e38)
- float64(+- 5 1e-324 -> 107 1e308)
布尔型
布尔型的值只能是 true 或者 false这两个go语言内置常量。
可以逻辑运算的类型进行逻辑运算会产生布尔型。
var a = 1
a == 5 // false
a == 1 // true
aStr := "aa"
aStr == "vvv" //false
aStr == "aa" // true
复数类型
go内置complex64和complex128来表示复数,内嵌函数real,imag可以分别获得相应的实数和虚数部分。
类型转换
在golang中不支持隐式类型转换
var a int64 = 30
var b int32
b = a //编译器报错
我们自己需要用类型转换表达式类转换类型
类型名(表达式)
var a int64 = 3
var b int32
b = int64(a) //ok
var sum int = 90
var count int = 50
var mean float32
mean = float32(sum)/float32(count) //ok
字符串
字符串的本质
go内嵌string类型来表示字符串。我们来看string的本质
type StringHeader struct {
Data uintptr
Len int
}
本质是string是个结构体,有连个字段Data是个指针指向一段字节系列(连续内存)开始的位置。Len则代表长度,内嵌函数len(s)可以获取这个长度值。
Data字段指向的是一段连续内存的起始文字,这一段内存的值是不允许改变的。
a:="aaa" // a{Data:&"aaa",Len:3} &"aaa"代表为“aaa”内存起始地址
b:=a // b{Data:&"aaa",Len:3}
c:=a[2:] // c{Data:&"aaa"+2,Len:3}
字符串拼接
go字符串拼接使用+
a:="hello" + " world"
b := a+"ccc"
字符串切片操作
字符串支持下标索引的方式索引到字符,s[i] i需要满足0<=i<len(s),小于0会引起编译错误,大于等于len(s)会引起运行时错误panic: index out of range。
s := "hello world"
fmt.Println(len(s)) //11
fmt.Println(s[2], s[7]) //108 111('l','o')
s[i]的本质是获取 Data指针指向内容第i个字节的值。由于Data指向的只是不允许改变的,所以试图改变它的值会引起编译错误
s[2] ='d' // compile error
字符串支持切片操作来产生新的字符串
s := "hello world"
fmt.Println(s[0:5]) //"hello"
fmt.Println(s[:5]) //"hello" 等同 s[0:5]
fmt.Println(s[5:]) //" world" 等同 s[5:11]
fmt.Println(s[:]) //"hello world" 等同 s[0:11]
rune
go语言中使用rune处理Unicode,go的源码文件使用的是UTF8编码。go语言使用unicode/utf8来处理utf8。
本质上rune是int32的别名。
import "unicode/utf8"
s := "Hello,世界"
fmt.Println(len(s)) // "12"
fmt.Println(utf8.RuneCountInString(s)) // "8"
需要主要字符串在用range变量的时候 会转换成[]rune
for _, v := range s {
fmt.Println(string(v))
}
结果是
H
e
l
l
o
,
世
界
数组和Slice(切片)
数组
数组是固定长度相同类型的集合。数组的长度必须是一个常量表达式(编译阶段就知道结果),数组元素的值可以由地址下标访问和修改的。
数组是比较特殊的类型,数组的长度是数组类型的一部分,像[3]int和[6]int二者是不同类型
var a [3]int
var b []string
var c = [5]int{1, 2, 15, 23, 16}
var d = [...]int{9, 6, 7, 5, 12} // `...`可以替代写具体长度,编译器可以帮你算
数组遍历
数组可以使用for和for range方式来遍历
var arr = [9]int{0, 1}
for i := 0; i < len(arr); i++ {
arr[i] = i * 2
}
for _, v := range arr {
fmt.Println(v)
}
for i, _ := range arr {
fmt.Println(arr[i])
}
数组在golang中实践使用的比较少,很多场景中我们都使用Slice来替代。
切片(slice)
切片是对数组一段连续内存的引用,在golang中Slice的底层结构为
type SliceHeader struct {
Data uintptr //指向该切片的索引的底层数组中的起始位置
Len int //切片长度
Cap int //切片总容量
}
内置函数len和cap可以分别获取切片的长度和大小。
切片的内存模型
var a=[5]int{1,2,3,4,5}
b:=a[0:3] // b SliceHeader{&a[0],3,5}
c:=a[3:5]// c SliceHeader{&a[3],2,2}
切片表达式
var a=[5]int{1,2,3,4,5}
b:=a[:3] //等同于 a[0:3]
c:=a[3:] //等同于 a[3:5]
d:=a[:] //等同于 a[0:5]
使用make 创建
a := make([]int, 8, 9) //创建[]int且切片 len为8 cap为9
aa := make([]int, 8) //参数cap可以省略 默认cap和len一样
切片的复制
golang内置函数copy来复制切片
copy的声明格式func copy(dist []T,src []T)int ,copy的返回值为拷贝的长度
src1 := []int{1, 2, 3}
src2 := []int{4, 5}
dest := make([]int, 5)
n := copy(dest, src1) //注意这边只拷贝了前三个元素
n = copy(dest[3:], src2) //拷贝从第四个位置上
切片追加
golang内置函数append来追加切片。
append声明格式func append(dest[]T, x ...T) []T
append方法将多个具有相同类型的元素追加到dest切片后面并且返回新的切片,追加的元素必须和dest切片的元素同类型。
如果dest的切片容量不够,append会分配新的内存来保证已有切片元素和新增元素的存储。因此返回的切片所指向的底层数组可能和dest所指向的底层数组不相同。
a := []int{1, 2, 3} //a len:2 cap:3
b = append(a, 4, 5, 6) //b: len:5 cap:5 b和a指向的数组已经不同
c := append(a,b...) // 使用...快速展开b
切片遍历
切片遍历和数组基本上没差别
var arr = make([]int,10)
for i := 0; i < len(arr); i++ {
arr[i] = i * 2
}
for _, v := range arr {
fmt.Println(v)
}
for i, _ := range arr {
fmt.Println(arr[i])
}
Map
map结果通常是现代语言中高频使用的结构。了解map的使用方法和map的底层解构是十分必要的,本小节将介绍map的使用, map的底层原来健在go runtime的章节介绍。
Map 变量声明
var m map[keytype]valuetype
map的key是有要求的,key必须是可比较类型,比如常见的 string,int类型。而数组,切片,和结构体不能作为key类型。
map的value可以是任何类型。
map的默认初始值为 nil
创建map和添加元素
golang中创建map需要使用make方法
格式如下
m := make(map[keytype]valuetype, cap)
cap参数可以省略。map的容量是根据实际需要自动伸缩。
内置函数len可以获取map的长度
map make之后就可以添加元素了
m:=make(map[string]int)
m["aa"]=1
m["bb"]=2
判断key是否存在
m:=make(map[string]int)
m["aa"]=1
m["bb"]=2
v, found := m["aa"] //found为true 为1
v, found := m["aaa"] //found为false 为0
//通常和if表达是一起,判断key是否存在
if vv,found:=m["bb"];found { //key存在
//code
}
删除map中的元素
map使用内置函数delete来删除元素。
delete(m,key)
m:=make(map[string]int)
m["aa"]=1
delete(m,"aa")
delete(m,"bb") // key不存在也不会报错
遍历map
golang 使用for-range遍历map
for k, v := range m {
//code
}
k,v分别代表key和这个key对于的值。
如果只想获取key可以
for k := range m {
fmt.Println(key)
}
如果只想获取value则:
for _, v := range m {
fmt.Println(v)
}
map的一些特性
- map中key是不排序的,所以你每一次对map进行
for-range打印的结果可能不同 - golang的map不是
线程安全的,在并发读写的时候会触发concurrent map read and map write的panic。解决的办法是自己加把锁。 - map在删除某个key的时候不是真正的删除,只是标记为空,空间还在,所以在for range删除map元素是安全的。
指针类型
go语言中也有指针,但是go语言中指针的不支持指针运算,例如 a = *p++ 在go中是不支持的。
指针变量的本质是指向存储某个类型值的内存地址。所有的指针类型大小都一样受系统平台影响,跟指向的值类型无关。
指针使用 变量名 *变量类型申明。 指针类型的0值为nil。
var p *int //p 为指向int类型的指针,目前值为nil
a := 1
p = &a //p指针存了a变量的内存地址,类似0xc0000140e0这样的一个内存地址。
*p = 2 //这里*的左右是让p指针指向的内存值改成2
fmt.Println(*p,a) //2,2 a的值也变成2
c:=3
p= &c //p保持了c的内存地址,到吃p和a的关系解除
go的指针虽然不能进行运算,但是指针带来了操作内存的便捷性。同时在一些需要拷贝的场景(比如函数传参),使用指针可以减少额外的内存开销和提供性能。涉及指针的问题,后续章节会有更多的例子。
运算
算数运算
整型和浮点型支持 +、-、* 和 /。
整型还支持%(取余数)。
逻辑运算
go 整型,浮点型,string 支持 ==、!=、<、<=、>、>=逻辑运算,逻辑运算的结果会产生bool类型。
//string 逻辑运算 使用的是按字节逐一对比的
"ab" >"c" //false
位运算
二元运算符:
按位与 &:
1 & 1 // 1
1 & 0 // 0
0 & 0 // 0
按位或 |:
1 | 1 // 1
1 | 0 // 1
0 | 0 // 0
按位异或 ^:
1 ^ 1 // 0
1 ^ 0 // 1
0 ^ 0 // 0
位清除 &^:
a &^ b表示把a中,ab都为1的位置为0
0110 &^ 1011 // 0100
1011 &^ 1101 // 0010
一元运算符
按位取反^:
对应位置 0变成1,1变成0。对于正的有符号数,取反会变负数,所以负的有符号数取反都等于1.
^1 // -2
^-3 // 2
位左移 <<: 左移时右侧位补0,移动一位相当于乘以2
1 << 10 // 等于 1k
1 << 20 // 等于 1m
1 << 30 // 等于 1g
位右移 >>: 右移时左侧位补0,移动一位相对于乘以2
39 >>2 // 9
512 >> 2 //128
运算符与优先级
由上至下代表优先级由高到低
优先级 运算符
8 ()(括号)
7 ^ !
6 * / % << >> & &^
5 + - | ^
4 == != < <= >= >
3 <-
2 &&
1 ||
流程控制
if-else
golang中 if-else有如下几种结构
if 条件 {
//代码
}
if 条件 {
//代码
} else {
//代码
}
if 条件1 {
//代码
} else if 条件2 {
//代码
}else {
//代码
}
switch
golang的switch条件控制比较强大,有如下几种方式
switch 变量 方式
switch 变量 {
case 值1:
//代码
case 值2:
//代码
default:
//代码
}
var1 :=0
switch var1 {
case 1:
fmt.Println(1)
case 0:
fmt.Println(0)
default:
fmt.Println("default")
}
switch 变量 {
case 值1,值2: //case 后可以支持多个值做测试,多个值使用`,`分割
//代码
case 值3:
//代码
default:
//代码
}
var1 :=99
switch var1 {
case 98,99,100:
fmt.Println("more than 97")
case 0:
fmt.Println(0)
default:
fmt.Println("other")
}
Go里面switch默认的情况下每个case最后都会break,匹配成功后不会自动向下执行其他case,而是跳出整个switch, 但是golang支持fallthrough强制执行下一个case的代码。
switch val {
case 0: fallthrough
case 1:
func1() //i == 0 时函数也会被执行
}
switch 不带变量方式,在case 分支使用条件判断语句
switch {
case 条件1:
//代码
case 条件2:
//代码
default:
//代码
}
i :=99
switch {
case i < 0:
fmt.Println("le 0")
case i == 0:
fmt.Println("eq 0")
case i > 0:
fmt.Println("lg 0")
}
for
在golang中for控制结构是最灵活的。在for循环体重break可以退出循环,continue可以忽略本次循环未执行的代码跳入下次循环。
正统的for结构
for 初始化语句; 条件语句; 修饰语句 {
}
for i := 0; i < 10; i++ {
if i==3 {
continue //不打印3
}
fmt.Println(i)
}
类似 while 结构
for 条件 {
}
i:=10
for i >= 0 {
i -= 1
fmt.Println(i)
}
无限循环
for{
//代码
}
i :=10
for{
i-=1
if i == 0 {
break //使用break退出无限循环
}
}
for-range 结构
在golang中 for range比仅仅可以遍历 数组,切片,map 还可以变量 带缓存的channel
arr :=[]int{1,3,3}
for i, v := range myMap {
fmt.Printf("index:%d value:%d \n", i, v)
}
myMap := map[string]int{
"a": 1,
"b": 2,
}
for k, v := range myMap {
fmt.Printf("key:%s value:%d \n", k, v)
}
channels := make(chan int, 10)
go func() {
for {
channels <- 1
time.Sleep(1e9)
}
}()
for v := range channels { //当channels的缓存队列为空会阻塞
fmt.Println(v)
}
select 结构
在golang中还有一个特殊的控制结构叫select,select需要和channel配置使用,我们在channel的小节再详解介绍。
函数
golang的函数有很多独特的创新。比如golang的函数支持多个返回值,而且支持返回值命名,golang的函数中支持defer。
go函数声明格式
func 函数名(参数列表) (返回值列表) {
//函数体
}
在参数列表中,多个相同类型可简写如下
func add1(a int,b int) int {
return a+b
}
//参数列表可简写
func add2(a,b int) int {
return a+b
}
golang支持函数有多个返回值。如果函数只有一个返回值可以简写成如下格式
func 函数名(参数列表) 返回值 {
//函数体
}
golang还支持命名的返回值。
func read(url string) (string,error) {
content, err := 函数类型的零值是nil。调用值为nil的函数值会引起pani
return string(content),nil
}
//只返回一个返回值
func add(a int,b int) int {
return a+b
}
//无返回值
func swap(a *int,b *int) {
temp := *a
*a = *b
*b = temp
}
//命名的返回值
func add(a int,b int)(c int) {
c = a+b
return
}
函数类型
在golang中定义的函数可以被看做一种值类型,可以赋值给函数类型变量。函数类型的默认初始值为nil。
func add(a int,b int) int {
return a+b
}
fn := add //fn的类型为 func(a,b int)
fmt.Println(f(1,2))
可变参数
golang支持可变参数,但是要求参数类型是一致的。其实golang的可变参数是一个slice。
可变参数在fmt包中非常常见。比如Printf定义为func Printf(format string, a ...interface{}) (n int, err error) 。
由于使用了interface{}接口类型,所以它可以接收任意类型参数。
func sum(arr ...int) int {
totalNum := 0
for _, v := range arr {
totalNum += v
}
return totalNum
}
defer
golang中defer关键字运行我们推迟到函数返回之前执行代码块或函数。defer通常被设计来关闭资源或者处理panic。一个函数中支持有多个defer,
多个defer的执行顺序为代码位置逆序。
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
return ReadAll(f)
}
匿名函数
golang还支持匿名函数,匿名函数经常在defer和go关键字后面看到。
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer func() { //匿名函数
f.Close()
//再做点其他事情
}()
return ReadAll(f)
}
go func(){ //开启一个go协程
//做点事情
}()
函数递归
golang的函数也支持递归,如下我们用递归的方式实现斐波那契数列。
func fibonacci(n int) (res int) {
if n <= 1 {
res = 1
} else {
res = fibonacci(n-1) + fibonacci(n-2)
}
return
}
结构体和方法
结构体是数组组织的一种形式,类似面向对象语言中的class。golang中使用结构体和结构体方法有面向对象的一些类似特性。
结构体定义
type 结构体名称 struct {
字段名1 类型1 `字段标签`
字段名2 类型2 `字段标签`
...
}
结构体字段名的大小写决定了这个结构体在包外是否可见。
type Stu struct{
Name string //包外可见
age int //包外不可见
}
结构体中的字段类型可以是任何类型,包括结构体本身,函数类型,接口类型。
type Inter interface{
FuncA(int)
}
type Ftype func(int)
type S struct {
fn Ftype //函数类型
inter Inter //接口类型
node *S //包含自己
Name string
}
结构体的标签可以通过结构体反射获取,在结构体序列化和反序列化时长会见到。
比如结构体需要使用json序列化和反序列化是可能需要如下定义:
type Stu struct{
Name string `json:"name"`
No string `json:"number"`
age int //age对外不见不参与序列化
}
结构体初始化
type Stu struct{
Name string
age int
}
var stuA = Stu{"wida",18} //不带字段名初始化,必须按照结构体定义的顺序赋值
var stuB = Stu{Name:"amy",age:18} //带字段名初始化
var stuC = Stu{Name:"jenny"} //带字段名初始化,不给age初始化, age是int初始化值为0
一般在时间开发过程中,我们都建议使用带字段名初始化,这样防止在增加结构体字段的时候引起报错。
结构体还可以使用golang内置函数new初始化。使用new初始化返回的结构体指针。
var stuAPtr = new(Stu)
stuAPtr.Name = "wida"
stuAPtr.age = 18
大多数情况下我们可以使用取地址符&来取代new函数。
var stuAPtr = &Stu{"wida",18} //这个等效也上面的new 初始化
结构体嵌套
golang中结构体是可以嵌套的,A结构体嵌套Base结构体可以隐式获取Base结构体的属性,实际上A结构体有个匿名字段为Base在名字冲突的时候可以使用这个字段解决冲突问题
type Base struct {
Name string
Age int
}
type A struct{
Base
Gender int
}
type B struct {
Base
Name string
}
var a A
a.Gender = 1
a.Age = 18 //等同于a.Base.Age
a.Name = "wida" //等同于a.Base.Name
var b B
b.Age = 18
b.Name = "wida" //注意这个时候 b.Name是b自带的 而非b.Base.Name
b.Base.Name = "amy"
结构体方法
类似面向对象语言中的类方法,golang中结构体也有他的方法,在golang中结构体的方法有两中接收器(receiver),一种就是结构体结构体对象还一中是结构体结构体对象指针,需要注意二者在使用上的区别。
type Stu struct {
Name string
Age int
}
func (s Stu)GetName() string {
return s.Name
}
func (s Stu)SetName(name string) {
return s.Name = name
}
var a Stu
a.SetName("aaa")
fmt.Println(a) //{ 0} 这边SetName没有把a的Name赋值为aaa
SetName正确的写法应该是
func (s *Stu)SetName(name string) {
return s.Name = name
}
a.SetName("aaa") //这边go会有一个隐式转换 a->*a
fmt.Println(a) //{aaa 0}
为什么结构体对象做接收器SetName方法不起作用? 在golang中参数都是拷贝传递的,事实上接收器其实是特色的一个参数,结构体对象接收器的方法会把接收器对象拷贝一份,对新对象赋值操作当然不能改变老的对象,而由于指针结构体接收器拷贝的是指针,实际上是指向同一个对象,所以修改就能生效。 在实际开发过程中我们一般都会使用结构体对象指针接收器,不仅仅可以规避赋值不生效的问题,而且还可以防止大的对象发生拷贝的过程。
有个情况需要特别注意,在golang中nil是可以作为接收器的。
func (s *Stu) SetName(name string) {
if s == nil {
return
}
s.Name = name
}
var aPtr *Stu //aPtr是指针 初值是nil
aPtr.SetName("ddd") //代码没有效果,但是不会报错
方法继承
类似结构体字段的继承,结构体A内嵌另一个结构体B时,属于B的方法也会别A继承。
type Base struct {}
func (b *Base)Say() {
fmt.Println("hi")
}
type A struct {
Base
}
var a A
a.Say()
package和可见性
go源码文件
go项目的源码文件有如下三种
.go为文件名的go代码文件,在实际项目中这个是最常见的。.s为结尾的go汇编代码文件,需要汇编加速的项目会用到,go内核源码比较多,实际项目中非常少见。.h .cpp .c为结尾的c/c++代码,需要和c/c++交互的项目有看到,在实际项目也不较少见。
一般go编译器在编译时会扫描相关目录下的这些go源文件进行编译.
如下情况下go源码文件会忽略编译
_test.go为结尾的文件,这些文件是go的单元测试代码,用于测试go程序,不参与编译。_$GOOS_$GOARCH.go$GOOS代码操作系统(windows,linux等),$GOARCH代表cpu架构平台(arm64,adm64等),go编译时会符合环境变量相关文件编译。- 编译过程中指定了条件编译参数
go build -tags tag.list,编译器会选择性忽略一些文件不参与编译,参考go build。
包
包(package)是go语言模块化的实现方式,每个go代码需要在第一行非注释的代码注明package。
go的package是基于目录的,同一个目录下的go代码只能用相同的package。
main package
go中main package是go可执行程序必须包含的一个package。该package下的main方法是go语言程序执行入口。
go可见性规则
golang中常量、变量、类型名称、函数名、结构字段名 以一个大写字母开头,这个对象就可以被外部包的代码所使用;标识符如果以小写字母开头,则对包外是不可见的,整个包的内部是可见。
//a目录下
package a
const COST="aa" //对外可见
var A :=0 //对外可见
var a :=0 //对外不可见
func F1() { //对外可见
}
func f1(){ //对外不可见
}
type Student struct{ //对外可见
Name string //对外可见
age int //对外不可见
}
type student struct {//对外不可见
}
//main package
package main
import "a"
func main(){
println(a.COST) //访问a package下的常量
a.A ==1 //访问a package下 A变量
a.a //编译报错
a.F1()
a.f1()//编译报错
var stu a.Student //访问 a package下的Student结构体
var stu1 a.student //student不可见 编译报错
stu.Name = "nam1" //ok
stu.age = 18 //不可见 编译报错
}
goroutine和channel
goroutine
golang原生支持并发,在golang中每一个并发单元叫goroutine。goroutine你可以理解为golang实现轻量级的用户态线程。go程序启动的时候
其主函数就开始在一个单独的goroutine中运行,这个goroutine我们叫main goroutine。
在golang中启动一个goroutine的成本很低,通常只需要在普通函数执行前加go关键字就可以。
func fn(){
fmt.Println("hello world")
}
fn()
go fn() //启用新的goroutine中执行 fn函数
channel
channel是golang中goroutine通讯的一直机制,每一个channel都带有类型,channel使用make来创建。
ch1 :=make(chan int) //创建不带缓冲区的channel
ch2 :=make(chan int,10)//创建带缓冲区的channel
channel是指针类型,它的初始值为nil,channel的操作主要有 发送,接受,和关闭。
ch <- x // 发送x
x := <-ch // 从channel中接收 然后赋值给x
<-ch // 接收后丢弃
close(x) //
不带缓存的channel,发送的时候会阻塞当前goroutine,知道channel的信息被其他goroutine消费。
带缓存的channel,当这个channel的缓存队列没有满是往channel写数据是不会阻塞的,当队列满是会阻塞这个goroutine。
channel读取的时候如果channel队列有值会读取,队列为空的时候会塞这个goroutine直到channel有值可以读取。
当一个channel被close后,基于该channel的发送操作都将导致panic,接收操作可以接受到已经channel队列里头数据,channel队列为空时产生一个零值的数据。
golang中的channel还可以带方向。
var out chan<- int //只发送,不能接收
var in <-chan int //只接收,不能发送 注意 对只接收的channel close会引起编译错误
select控制结构和channel
select是golang中的一个控制结构,和switch表达式有点相似,不同的是select的每个case分支必须是一个通信操作(发送或者接收)。
select随机选择可执行case分支。如果没有case分支可执行,它将阻塞,直到有case分支可执行。
带default分支的select在没有可执行case分支时会执行default。
ch :=make(chan int,1)
select {
case ch <- 1 :
//代码
case n:= <-ch :
//代码
default : //default 是可选的
//代码
}
select语句的特性:
- 每个
case分支都是通信操作 - 所有
case分支表达式都会被求值 - 如果任意某个
case分支不阻塞,它就执行,其他被忽略。 - 如果有多个
case分支都不阻塞,select会随机地选出一个执行。其他不会执行。 否则:- 如果有
default,则执行该语句。 - 如果没有
default,select将阻塞,直到某个case分支可以运行;
- 如果有
ch := make(chan int, 1) //这边需要使用1个缓冲区,这样子可以在一个goroutine内使用
for {
select {
case ch <- 1:
fmt.Println("send")
case n := <-ch:
fmt.Println(n)
default:
fmt.Println("dd")
}
time.Sleep(1e9)
}
本小节简介了goroutine和channel相关概念,具体的并发编程模型将在下个章节详细探讨。
接口(interface)
golang中接口(interface)是被非常精心设计的,利用接口golang可以实现很多类似面向对象的设计,而且比传统的面向对象更加方便。
接口是一组方法的定义的集合,接口中没有变量。
接口的格式:
type 接口名 interface {
M1(参数列表) (返回值列表) //方法1
M2(参数列表) (返回值列表) //方法2
...
}
某个类型全部实现接口中定义的方法,我们称作该类型实现了该接口,而不需要在代码中显示声明该类型实现某个接口。
type Sayer interface{
Say()
}
type Dog struct{}
type Cat struct{}
func (d *Dog) Say() {
fmt.Println("wang ~")
}
func (Cat *Cat) Say() {
fmt.Println("miao ~")
}
func Say(s Sayer) { //函数使用接口类型做参数
s.Say()
}
var sayer Sayer
dog:=new(Dog)
cat:=new(Cat)
sayer = dog //这样赋值给接口变量是ok的,Dog实现了Say方法
sayer.Say()
sayer = cat
sayer.Say()
Say(dog) //这样子传参也ok
Say(cat)
从上面的例子上看,golang的interface可以实现面向对象语言多态的特性,而且更加简洁,高效。
接口嵌套
golang的接口是可以嵌套的,一个接口可以嵌套一个或者多个其他接口。
type Reader interface{
Read()
}
type Writer interface {
Write()
}
type ReadWrite interface { //ReadWrite 嵌套了 Reader 和 Writer
Reader
Writer
}
空接口
在接口中,空接口有其独特的位置,空接口没有定义任何方法,那么在golang中任何类型都实现了这个接口。
interface{}
我们再看下fmt包中Println的定义:
//func Println(a ...interface{}) (n int, err error)
fmt.Println(1,"aa",true) //由于参数是 interface{} 所以可以传任意类型
类型断言
接口类型的变量支持类型断言,通过类型断言我们可以检测接口类型变量底层真实的类型。
类型断言表达式如下:
v,ok := varInterface.(T)
var i interface{}
a := 1
i = a
if temp, ok := i.(int); ok { //实际开发中我们经常会这样子 做类型转换
fmt.Println(temp)
}
dog:=new(Dog)
_,ok := dog.(Sayer) //我们还可以判某个类似是否实现了某个接口
我们可以使用switch case语句来更多规模的类型检测
比如fmt包中printArg的这一段代码
switch f := arg.(type) {
case bool:
p.fmtBool(f, verb)
case float32:
p.fmtFloat(float64(f), 32, verb)
case float64:
p.fmtFloat(f, 64, verb)
case complex64:
p.fmtComplex(complex128(f), 64, verb)
...
反射
反射提供了一种机制能够在运行时检测类型和变量,动态调用它们的方法,而不需要在编译时就知道这些变量的具体类型。golang中使用reflect包来实现反射。
反射虽然提供很多额外的能力,但是反射的总体性能比较低,在要求性能的场景应该尽量避免使用反射。
反射包中reflect.TypeOf能获取类型信息对于的类型是Type,reflect.ValueOf能获值信息对于的类型是Value。
func TypeOf(i interface{}) Type
func ValueOf(i interface{}) Value
使用TypeOf反射一个变量的时候,我们可以获取其类型的相关信息。
type Stu struct {
Name string `json:"name"`
age int
}
func (s Stu) Say() {
fmt.Println(s.Name)
}
s := Stu{"wida", 0}
t := reflect.TypeOf(s)
fmt.Println(t.Kind()) //类型为 struct
for i := 0; i < t.NumField(); i++ { //反射所有的字段
fmt.Println(t.Field(i)) //t.Field 返回 StructField 这里结构体标签的信息 Name字段的标签 `json:"name"`可以在这边获取
}
for i := 0; i < t.NumMethod(); i++ { //反射所有的方法
fmt.Println(t.Method(i))
}
使用ValueOf反射一个变量的是,我们可以获取s变量值的信息。
type Stu struct {
Name string `json:"name"`
age int
}
func (s Stu) Say() {
fmt.Println(s.Name)
}
s := Stu{"wida", 0}
t := reflect.ValueOf(s)
fmt.Println(t.Kind()) //类型为 struct
for i := 0; i < t.NumField(); i++ { //反射所有的字段
fmt.Println(t.Field(i)) //这边返回的是Value
}
for i := 0; i < t.NumMethod(); i++ { //反射所有的方法
fmt.Println(t.Method(i))
}
可以通过Value修改变量的值
x := 2
d := reflect.ValueOf(&x).Elem() // Elem返回Value的指针类型
d.SetInt(3)
fmt.Println(x) // "3"
错误处理
在golang中错误有专门的一个包errors来处理,golang定义了error的接口,还允许自定义错误类型。
type error interface {
Error() string
}
错误支持==和!=操作。
定义简单错误
errors包中提供New方法来生成error(底层类型是error.errorString)。
err1 := errors.New("error1")
err2 := errors.New("error2")
func makeErr(a int) error {
if a==1 {
return err1
}
if a==2 {
return err2
}
return nil
}
fmt.Println(err1 == makeErr(1))
fmt.Println(err1 == makeErr(2))
自定义错误
只有实现error接口,你就可以定义新的一种错误类型
type myError struct {
s string
code int
}
func (m *myError) Error() string {
return fmt.Sprintf("code:%d,msg:%s", m.code, m.s)
}
var err1 = &myError{"error1", 100}
var err2 = &myError{"error1", 100}
func makeErr(a int) error {
if a == 1 {
return err1
}
if a == 2 {
return err2
}
return nil
}
fmt.Println(makeErr(1)) //code:100,msg:error1
fmt.Println(err1 == makeErr(1)) //true
fmt.Println(err1 == makeErr(2)) //true
错误处理技巧
在go1.13之前,go的错误处理方式代码写起来相当繁琐。go1.13吸收了go社区一些优秀的错误处理方式(pkg/errors),彻底解决被人诟病的问题。本文主要介绍的错误处理方式是基于go1.13的。
go 1.13的error包 增加的errors.Unwrap,errors.As,errors.Is三个方法。
同时 fmt 包增加 fmt.Errorf("%w", err)的方式来wrap一个错误。
我们通过代码来了解它们的用法。
package main
import (
"fmt"
"errors"
)
type Err struct {
Code int
Msg string
}
func (e *Err) Error() string {
return fmt.Sprintf("code : %d ,msg:%s",e.Code,e.Msg)
}
var A_ERR = &Err{-1,"error"}
func a() error {
return A_ERR
}
func b() error {
err := a()
return fmt.Errorf("access denied: %w", err) //使用fmt.Errorf wrap 另一个错误
}
func main() {
err := b()
er := errors.Unwrap(err) //如果一个错误包含 Unwrap 方法则返回这个错误,如果没有则返回nil
fmt.Println(er ==A_ERR )
fmt.Println(errors.Is(err,A_ERR)) // 递归调用Unwrap判断是否包含 A_ERR
var e = &Err{}
fmt.Println( errors.As(err, &e))
if errors.As(err, &e) { // 递归调用Unwrap是否包含A_ERR,如果有这赋值给e
fmt.Printf("code : %d ,msg:%s",e.Code,e.Msg)
}
}
运行代码
$ go run main.go
true
true
true
code : -1 ,msg:error
错误为什么为要被wrap?
在一个函数A中错误发生的时候,我们会返回这个错误,函数B调用函数A拿到这个错,但是函数B不想做其他处理,它也返回错误,但是要打上自己的信息,说明这个错误经过了B函数,所以Wrap err就有了使用场景。
用了wrap后,错误是链状结构,我们用errors.Unwrap,逐级遍历err。还有我们有时候不一定会关心所有链条上的错误类型,我们只判断是否包含某种特点错误类型,所以 errors.Is和errors.As 方法就出现了。
带上函数调用栈信息
标准库的错误处理基本上能我们日常的开发需求,而且基本上能做到很优雅的错误处理。但是有时候我们还想带上更多信息,比如函数调用栈。我们使用第三方库pingcap errors来实现。
package main
import (
"fmt"
pkgerr "github.com/pingcap/errors"
)
type Err struct {
Code int
Msg string
}
func (e *Err) Error() string {
return fmt.Sprintf("code : %d ,msg:%s",e.Code,e.Msg)
}
var A_ERR = &Err{-1,"error"}
func stackfn1() error {
return pkgerr.WithStack(A_ERR)
}
func main() {
err := stackfn1()
fmt.Printf("%+v",err) //这边使用 “%+v”
}
```要介绍的错误处理方式是基于go1.13的。
$ go run main.go
code : -1 ,msg:error
main.stackfn1
/home/wida/gocode/goerrors-demo/main.go:18
main.main
/home/wida/gocode/goerrors-demo/main.go:22
runtime.main
/home/wida/go/src/runtime/proc.go:203
runtime.goexit
/home/wida/go/src/runtime/asm_amd64.s:1357
Process finished with exit code 0
有了函数调用栈信息,我们可以更好的定位错误。
panic和recover
有些错误编译期就能发现,编译的时候编译器就会报错,而有些运行时的错误编译器是没办法发现的。golang的运行时异常叫做panic。
在golang当切片访问越界,空指针引用等会引起panic,panic如果没有自己手动捕获的话,程序会中断运行并打印panic信息。
var a []int = []int{0, 1, 2}
fmt.Println(a[3]) //panic: runtime error: index out of range [3] with length 3
type A struct {
Name string
}
var a *A
fmt.Println(a.Name) //panic: runtime error: invalid memory address or nil pointer dereference
手动panic
当程序运行中出现一些异常我们需要程序中断的时候我们可以手动panic
var model = os.Getenv("MODEL") //获取环境变量 MODEL
if model == "" {
panic("no value for $MODEL") //MODEL 环境变量未设置程序中断
}
使用recover捕获panic
我们在defer修饰的函数里面使用recover可以捕获的panic。
func main() {
func() {
defer func() {
if err := recover(); err != nil { //recover 函数没有异常的是返回 nil
fmt.Printf("panic: %v ", err)
}
}()
func() {
panic("panic") //函数执行出现异常
}()
}()
fmt.Println("here")
}
执行结果是
anic: panic
here
panic的产生后会终止当前函数运行,然后去检测当前函数的defer是否有recover,没有的话会一直往上层冒泡直至最顶层;如果中间某个函数的defer有recover则这个向上冒泡过程到这个函数就会终止。
golang中goroutine没有父子关系,不能在一个goroutine中 recover另一个goroutine的 panic。
func main() {
func() {
defer func() {
if err := recover(); err != nil {
fmt.Printf("panic: %v ", err)
}
}()
go func() {
panic("panic")
}()
}()
time.Sleep(1e9)
fmt.Println("here")
}
执行结果是
panic: panic
goroutine 6 [running]:
main.main.func1.2()
/workspace/gocode/test/cmd/test.go:16 +0x39
created by main.main.func1
/workspace/gocode/test/cmd/test.go:15 +0x57
exit status 2
我们看到虽然recover 捕获了错误信息,但是程序还是退出了。
go标准库
strings包
字符串操作通常是一种高频操作,在golang中专门提供了strings包来做这种工作。
Compare 方法
``比较两个字符串的字典序,返回值0表示a==b,-1表示a < b,1表示a > b.通常我们应该运算符==,<,>来比较连个字符串,代码更简介,意思更明细,效率也更高。
func Compare(a, b string) int
strings.Compare("a", "b") //-1
strings.Compare("a", "a") //0
strings.Compare("b", "a") //1
Contains 方法
Contains方法用来判断字符串s中是否包含子串substr
func Contains(s, substr string) bool
strings.Contains("seafood", "foo") //true
HasPrefix和HasSuffix方法
HasPrefix和HasSuffix用来判断字符串中是否包含包含前缀和后缀
func HasPrefix(s, prefix string) bool
func HasSuffix(s, suffix string) bool
strings.HasPrefix("Gopher", "Go") //true
strings.HasSuffix("Amigo", "go") //true
Index 方法和 LastIndex方法
Index返回子串sep在字符串s中第一次出现的位置,如果找不到,则返回 -1。
LastIndex返回子串sep在字符串s中最后一次出现的位置,如果找不到,则返回 -1。
func Index(s, substr string) int
func LastIndex(s, substr string) int
strings.Index("chicken", "ken") //4
strings.Index("chicken", "dmr") //-1
strings.Index("go gopher", "go") //0
strings.LastIndex("go gopher", "go") //3
strings.LastIndex("go gopher", "rodent") //-1
Join方法
Join将a中的子串连接成一个单独的字符串,子串之间用sep拼接
func Join(elems []string, sep string) string
s := []string{"foo", "bar", "baz"}
fmt.Println(strings.Join(s, ", ")) //foo, bar, baz
Repeat方法
Repeat将count个字符串s连接成一个新的字符串。
func Repeat(s string, count int) string
strings.Repeat("na", 2)//nana
Replace和ReplaceAll方法
Replace和ReplaceAll方法为字符串替换方法,Replace返回s的副本,并将副本中的old字符串替换为new字符串,替换次数为n次,如果n为 -1则全部替换。
func Replace(s, old, new string, n int) string
func ReplaceAll(s, old, new string) string
strings.Replace("oink oink oink", "k", "ky", 2) //oinky oinky oink
strings.Replace("oink oink oink", "oink", "moo", -1) // moo moo moo
strings.ReplaceAll("oink oink oink", "oink", "moo") // moo moo moo 功能同上
Split 方法
Split方法以sep为分隔符,将s切分成多个子串,结果中不包含 sep 本身
func Split(s, sep string) []string
strings.Split("a,b,c", ",") //["a" "b" "c"]
strings.Split("a man a plan a canal panama", "a ") //["" "man " "plan " "canal panama"]
strings.Split(" xyz ", "") //[" " "x" "y" "z" " "]
strings.Split("", "Bernardo O'Higgins") //[""]
Trim、TrimSpace、TrimPrefix,TrimSuffix方法
Trim将删除s首尾连续的包含在cutset中的字符
TrimSpace将删除s首尾连续的的空白字符
TrimPrefix删除s头部的prefix字符串
TrimSuffix 删除s尾部的suffix字符串
func Trim(s, cutset string) string
func TrimSpace(s string) string
func TrimPrefix(s, prefix string) string
func TrimSuffix(s, suffix string) string
strings.Trim("¡¡¡Hello, Gophers!!!", "!¡") //Hello, Gophers
strings.TrimSpace(" \t\n Hello, Gophers \n\t\r\n")//Hello, Gophers
var s = "¡¡¡Hello, Gophers!!!"
strings.TrimPrefix(s, "¡¡¡Hello, ") //Gophers!!!
strings.TrimSuffix(s, ", Gophers!!!") //¡¡¡Hello
参考资料
bytes包
[]byte字节数组操作是string外的另外一种高频操作,在golang中也专门提供了bytess包来做这种工作。功能大多数和strings类似。
Compare和Equal方法
Compare方法安装字典顺序比较a和b,返回值1为a>b,0为a==b,-1为a<b。
Equal方法判断a和b的长度一致,并且a的b的byte值是一样的则为true,否则为false。
func Compare(a, b []byte) int
func Equal(a, b []byte) bool
bytes.Compare([]byte("a"), []byte("b")) //-1
bytes.Compare([]byte("a"), []byte("a")) //0
bytes.Compare([]byte("b"), []byte("a")) //-1
Contains 方法
Contains方法用来字节数组b中是否包含子字节数组subslice
func Contains(b, subslice []byte) bool
bytes.Contains([]byte("seafood"), []byte("foo")) //true
bytes.Contains([]byte("seafood"), []byte("bar")) //false
HasPrefix和HasSuffix方法
HasPrefix和HasSuffix用来判断字节数组中是否包含前缀和后缀
func HasPrefix(s, prefix []]byte)) bool
func HasSuffix(s, suffix []]byte)) bool
bytes.HasPrefix([]byte("Gopher"), []byte("Go")) //true
bytes.HasSuffix([]byte("Amigo"), []byte("go")) //true
Index 方法和 LastIndex方法
Index返回子字节数组sep在字节数组s中第一次出现的位置,如果找不到,则返回 -1。
LastIndex返回子字节数组sep在字节数组s中最后一次出现的位置,如果找不到,则返回 -1。
func Index(s, sep []byte) int
func LastIndex(s, sep []byte) int
bytes.Index([]byte("chicken"), []byte("ken")) //4
bytes.Index([]byte("chicken"), []byte("dmr")) //-1
bytes.Index([]byte("go gopher"), []byte("go")) //0
bytes.LastIndex([]byte("go gopher"), []byte("go")) //3
bytes.LastIndex([]byte("go gopher"), []byte("rodent")) //-1
Join方法
Join将a中的子串连接成一个单独的字符串,子串之间用sep拼接
func Join(s [][]byte, sep []byte) []byte
s := [][]byte{[]byte("foo"), []byte("bar"), []byte("baz")}
fmt.Printf("%s", bytes.Join(s, []byte(", "))) //foo, bar, baz
Repeat方法
Repeat将count个字节数组b连接成一个新的字节数组。
func Repeat(b []byte, count int) []byte
bytes.Repeat([]byte("na"), 2)//nana
Replace和ReplaceAll方法
Replace和ReplaceAll方法为字节数组替换方法,Replace返回s的副本,并将副本中的old字符串替换为new字节数组,替换次数为n次,如果n为 -1则全部替换。
func Replace(s, old, new []byte, n int) []byte
func ReplaceAll(s, old, new []byte) []byte
bytes.Replace([]byte("oink oink oink"), []byte("k"), []byte("ky"), 2) //oinky oinky oink
bytes.Replace([]byte("oink oink oink"), []byte("oink"), []byte("moo"), -1) // moo moo moo
bytes.ReplaceAll([]byte("oink oink oink"), []byte("oink"), []byte("moo")) // moo moo moo 功能同上
Split 方法
Split方法以sep为分隔符,将s切分成多个子字节数组,结果中不包含 sep 本身
func Split(s, sep []byte) [][]byte
bytes.Split([]byte("a,b,c"), []byte(",")) //["a" "b" "c"]
bytes.Split([]byte("a man a plan a canal panama"), []byte("a ")) //["" "man " "plan " "canal panama"]
bytes.Split([]byte(" xyz "), []byte("")) //[" " "x" "y" "z" " "]
bytes.Split([]byte(""), []byte("Bernardo O'Higgins")) //[""]
Trim、TrimSpace、TrimPrefix,TrimSuffix方法
Trim将删除s首尾连续的包含在cutset中的字符
TrimSpace将删除s首尾连续的的空白字符
TrimPrefix删除s头部的prefix字符串
TrimSuffix 删除s尾部的suffix字符串
func Trim(s []byte, cutset string) []byte
func TrimSpace(s []byte) []byte
func TrimPrefix(s, prefix []byte) []byte
func TrimSuffix(s, suffix []byte) []byte
bytes.Trim([]byte(" !!! Achtung! Achtung! !!! "), "! ") //Achtung! Achtung
bytes.TrimSpace([]byte(" \t\n Hello, Gophers \n\t\r\n"))//Hello, Gophers
var s = []byte("¡¡¡Hello, Gophers!!!")
bytes.TrimPrefix(s, []byte("¡¡¡Hello, ")) //Gophers!!!
bytes.TrimSuffix(s, []byte(", Gophers!!!")) //¡¡¡Hello
参考资料
fmt包——格式化输入输出
在之前章节中我们已经多次看到fmt这个包。fmt包实现了类似C语言printf和scanf的格式化I/O。
go的格式化原语来着c语言,但是比c语言更加简单。
通用格式:
%v 值的默认格式表示。当输出结构体时,扩展标志(%+v)会添加字段名
%#v Go语法表示值
%T Go语法表示值的类型
%% 百分号
布尔型:
%t true或false
数值型:
%b 二进制
%c 对应的unicode码点值
%d 十进制
%o 八进制
%O 八进制带`0o`开头
%q 单引号引起来的go语法字符字面值,必要时会采用安全的转义
%x 十进制小写
%X 十进制大写
%U Unicode格式:U+1234,等价于"U+%04X"
浮点数、复数的两个组分:
%b 无小数部分、二进制指数的科学计数法,如-123456p-78
%e 科学计数法小写e, e.g. -1.234456e+78
%E 科学计数法大写e, e.g. -1.234456E+78
%f 有小数部分但无指数部分, e.g. 123.456
%F 等价%f
%g 根据实际情况采用%e或%f格式(以获得更简洁、准确的输出)
%G 根据实际情况采用%E或%F格式(以获得更简洁、准确的输出)
字符串和[]byte
%s 直接输出字符串或者[]byte
%q 双引号括起来的go语法字符串字面值
%x 每个字节用两字符十六进制数表示(小写)
%X 每个字节用两字符十六进制数表示(大写)
指针:
%p 十六进制,并加上前导的0x
浮点数:
%f 默认宽度,默认精度
%9f 宽度9,默认精度
%.2f 默认宽度,精度2
%9.2f 宽度9,精度2
%9.f 宽度9,精度0
格式化规则除了使用格式化原语,%T和%p之外;
对实现了特定接口的操作数会采用特定的格式化方式按应用优先级如下:
- 如果操作数实现了
Formatter接口,会调用该接口的方法。Formatter提供了格式化的控制。 - 如果格式化原语
%v配合#使用(%#v),且操作数实现了GoStringer接口,会调用该接口。
如果操作数满足如下两条任一条,对于%s、%q、%v、%x、%X五个格式化原语,将考虑:
3. 如果操作数实现了error接口,Error方法会用来生成字符串,随后将按给出的flag(如果有)和格式化原语格式化。
4. 如果操作数具有String方法,这个方法将被用来生成字符串,然后将按给出的flag(如果有)和格式化原语格式化。
fmt包中常用的几个函数
格式化输出
func Printf(format string, a ...interface{}) (n int, err error)
func Println(a ...interface{}) (n int, err error)
格式化生产string
func Sprintf(format string, a ...interface{}) string
格式化生成error
func Errorf(format string, a ...interface{}) error
格式输入和扫描的几个函数通常在项目中比较少见。
文件读写
在golang的标准库中有三个包可以读写文件os,ioutil,bufio。
os是最基础文件操作功能,ioutil提供读写小文件的简便功能,bufio提供带缓存的区高性能读写功能。
使用io包读取写文件
f, err := os.OpenFile("a.txt", os.O_CREATE|os.O_RDWR|os.O_APPEND, 0755) //文件不存在会创建 写文件会追加在末尾
if err != nil {
log.Fatal(err)
}
f.Write([]byte("aaaa"))
f.WriteString("bbbb")
f.Close() //打开成功的文件句柄 不用的时候一定记得关闭
ff, err := os.OpenFile("a.txt", os.O_CREATE|os.O_RDWR|os.O_APPEND, 0755)
b := make([]byte, 1024)
n, err := ff.Read(b)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(b[:n])) //aaaabbbb
os.Remove("a.txt") //删除文件
f.Close()
使用ioutil包读写文件
ioutil包的ReadAll和ReadFile方法可以读取整个文件的内容到内存,对读取配置文件等小文件非常方便。
读文件
f, _ := os.Open("aa.txt")
b, _ := ioutil.ReadAll(f)
fmt.Println(string(b))
f.Close()
b, _ = ioutil.ReadFile("aa.txt")
fmt.Println(string(b))
对于大文件读取需要使用bufio包。
写文件
ioutil.WriteFile("aa.txt", []byte("aaaaa\nbbbbb\n"), 0666)
ioutil.WriteFile写文件会覆盖原先所有内容。
bufio读写文件
使用bufio按行读取文件
f, _ := os.Open("aa.txt")
defer f.Close()
buf := bufio.NewReader(f)
for {
line, _, err := buf.ReadLine()
if err != nil {
break
}
fmt.Println(string(line))
}
使用bufio写文件
f, _ := os.OpenFile("aa.txt", os.O_APPEND, 0755) //追加方式写文件
defer f.Close()
w := bufio.NewWriter(f)
w.Write([]byte("aaa\n"))
w.WriteString("bbb\n")
time
time包提供了时间的显示和测量用的函数。
获取当前时间
time中的Now方法会返回当前的时间(time.Time)。
now := time.Now()
fmt.Println(now) //2020-10-23 11:02:53.356985487 +0800 CST m=+0.000042418
fmt.Println(now.Unix()) //获取时间戳 1603422283
fmt.Println(now.UnixNano())//获取纳秒时间戳 1603422283132651138
fmt.Println(now.Year()) //年
fmt.Println(now.Month()) //月
fmt.Println(now.Day()) //日
fmt.Println(now.Hour()) //时
fmt.Println(now.Minute()) //分
fmt.Println(now.Second()) //秒
fmt.Println(now.Nanosecond()) //纳秒
格式化输出
使用time.Time的Format方法格式化时间.
golang的时间格式比较有特色。2006-01-02 15:04:05代表年-月-日 小时(24小时制)-分-秒。
fmt.Println(time.Now().Format("2006-01-02 15:04:05")) //2020-10-23 11:15:41
fmt.Println(time.Now().Format("2006-01-02 15:04:05.000")) //2020-10-23 11:15:41.439 带毫秒
fmt.Println(time.Now().Format("2006-01-02 15:04:05.000000")) //2020-10-23 11:15:41.439274 带微秒
fmt.Println(time.Now().Format("2006-01-02 15:04:05.000000000")) //2020-10-23 11:15:41.439277309 带纳秒
解析时间
时间戳转时间
fmt.Println(time.Unix(1603422283, 0).Format("2006-01-02 15:04:05"))
字符串转时间
t, err := time.Parse("2006-01-02 15:04:05", "2020-10-23 11:15:41")
fmt.Println(t)
使用time.Date构建时间
t := time.Date(2020, 10, 23, 11, 15, 41, 0, time.Local)
fmt.Println(t)
时间测量
很多时候我们需要比较两个时间,甚至需要测量时间距离。
测耗时
Time.Sub(t Time) 方法测量自己和参数中的时间距离
time.Slice(t Time)函数测量参数时间t到现在的距离
time.Until(t Time)函数测量现在时间到参数t的距离
start := time.Date(2000, 1, 1, 0, 0, 0, 0, time.UTC)
end := time.Date(2000, 1, 1, 12, 0, 0, 0, time.UTC)
difference := end.Sub(start)
fmt.Println(difference) //12h0m0s
fmt.Println(time.Since(start)) //182427h58m21.798590739s
fmt.Println(time.Until(end)) //-182415h58m21.798593974s
Sleep函数
Sleep函数会让当前的goroutine休眠
time.Sleep(d Duration) //Duration 是int64的别名代办纳秒值
time.Sleep(1*time.Second) //sleep 1s
time.Sleep(1e9) //sleep 1s
使用time.After来处理超时
func After(d Duration) <-chan Time
package main
import (
"fmt"
"time"
)
var c chan int
func handle(int) {}
func main() {
select {
case m := <-c:
handle(m)
case <-time.After(10 * time.Second):
fmt.Println("timed out")
}
}
定时器Time.Tick
使用Time.Tick会产生一个定时器.
func Tick(d Duration) <-chan Time
package main
import (
"fmt"
"time"
)
func statusUpdate() string { return "" }
func main() {
c := time.Tick(5 * time.Second) //每5s 生产时间 往channel 发送
for next := range c {
fmt.Printf("%v %s\n", next, statusUpdate())
}
}
flag包 —— 解析命令行参数
我们通过io包,知道golang使用os.Args来接收命令行参数,在简单的场景下os.Args基本够我们使用。
复杂的参数场下golang提供flag包来解析命令行参数。
参数格式
-flag //只支持布尔类型,有为true,无为默认值
-flag=x
-flag x // bool型不能用这个方式
参数中带-和--功能一致,例如cmd -a 3和cmd --a 3是一致的。
定义flag接收参数的两种方式
- 接收指针
例如 flag.String(), flag.Bool(), flag.Int()
func Int(name string, value int, usage string) *int
func Bool(name string, value bool, usage string) *bool
func String(name string, value string, usage string) *string
这类函数,name是参数名,value为默认值,usage为帮助信息-h的时候会打印,返回值为指针类型。
import "flag"
var nFlag = flag.Int("n", 1234, "help message for flag n")
fmt.Println(*nFlag) //指针类型用使用需要 *符号
- 参数绑定
例如flag.IntVar(),flag.StringVar(),flag.BoolVar()
func IntVar(p *int, name string, value int, usage string)
func BoolVar(p *bool, name string, value bool, usage string)
func StringVar(p *string, name string, value string, usage string)
这类函数,p为需要的绑定的指针,name是参数名,value为默认值,usage为帮助信息-h的时候会打印。
var flagvar int
flag.IntVar(&flagvar, "flagname", 1234, "help message for flagname")
fmt.Println(flagvar)
flag.Parse()
所以的参数能够解析一定要调用flag.Parse(),flag.Parse()调用后才开始做参数解析。
例子
package main
import (
"flag"
"fmt"
)
func main() {
var a int
var b bool
var c string
flag.IntVar(&a, "i", 0, "int flag value")
flag.BoolVar(&b, "b", false, "bool flag value")
flag.StringVar(&c, "s", "default", "string flag value")
flag.Parse()
fmt.Println("a:", a)
fmt.Println("b:", b)
fmt.Println("c:", c)
}
$ ./cmd -h #打印帮助信息
Usage of ./cmd:
-b bool flag value
-i int
int flag value
-s string
string flag value (default "default")
$ ./cmd -i 1 -b -s="acb"
a: 1
b: true
c: acb
参考资料
json包
现代的语言都会支持json这种轻量的序列化方式。在golang中使用encoding/json来支持json的各个操作。
序列化方法
json序列化方法是Marshal函数,函数签名是
func Marshal(v interface{}) ([]byte, error)
反序列化方法
json序列化方法是Unmarshal函数,函数签名是
func Unmarshal(data []byte, v interface{}) error
用于json的Struct Tag
json序列号和反序列化只针对可见字段,对于不可见字段这两个过程都会直接忽略。
使用omitempty来处理空值,使用-忽略字段。
package main
import (
"encoding/json"
"fmt"
)
func main() {
type Stu struct {
Name string `json:"name"`
Age int `json:"age"`
No string `json:"no,omitempty"`
Gender int `json:"-"`
group int //这个字段不参与序列化
}
stu := Stu{
Name: "wida",
Age: 35,
No: "8001",
Gender: 0,
group: 88,
}
b, _ := json.Marshal(&stu)
fmt.Println(string(b))
var stu1 Stu
json.Unmarshal(b, &stu1)
fmt.Printf("%+v", stu1)
}
$ go run main.go
{"name":"wida","age":35,"no":"8001"}
{Name:wida Age:35 No:8001 Gender:0 group:0}
定制序列化和反序列化方式
在encoding/json包中定义了Marshaler和Unmarshaler
type Marshaler interface {
MarshalJSON() ([]byte, error)
}
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
如果一个类型实现了这两个接口就有实现自定义的json序列化和反序列化。
看下官方文档的一个例子:
package main
import (
"encoding/json"
"fmt"
"log"
"strings"
)
type Animal int
const (
Unknown Animal = iota
Gopher
Zebra
)
func (a *Animal) UnmarshalJSON(b []byte) error {
var s string
if err := json.Unmarshal(b, &s); err != nil {
return err
}
switch strings.ToLower(s) {
default:
*a = Unknown
case "gopher":
*a = Gopher
case "zebra":
*a = Zebra
}
return nil
}
func (a Animal) MarshalJSON() ([]byte, error) {
var s string
switch a {
default:
s = "unknown"
case Gopher:
s = "gopher"
case Zebra:
s = "zebra"
}
return json.Marshal(s)
}
func main() {
blob := `["gopher","armadillo","zebra","unknown","gopher","bee","gopher","zebra"]`
var zoo []Animal
if err := json.Unmarshal([]byte(blob), &zoo); err != nil {
log.Fatal(err)
}
census := make(map[Animal]int)
for _, animal := range zoo {
census[animal] += 1
}
fmt.Printf("Zoo Census:\n* Gophers: %d\n* Zebras: %d\n* Unknown: %d\n",
census[Gopher], census[Zebra], census[Unknown])
}
log —— 官方的日志库
golang标准库提供了一个log包用来实现简单的程序日志记录功能。
log包的使用非常简单,函数名字和用法也和fmt包很相似,只是在它的输出默认带了时间。
三个基础函数
func Print(v ...interface{})
func Printf(format string, v ...interface{})
func Println(v ...interface{})
log.Print("print:", "这是Printf:产生的日志", "\n")
log.Println("Println:", "这是Println产生的日志")
log.Printf("Printf:%s\n", "这是Printf:产生的日志")
$ go run main.go
2020/10/23 10:01:35 print:这是Printf:产生的日志
2020/10/23 10:01:35 Println: 这是Println产生的日志
2020/10/23 10:01:35 Printf:这是Printf:产生的日志
打印日志后产生Panic
func Panic(v ...interface{}) //功能和`Print()`一样,只是后面加了`panic()`.
func Panicf(format string, v ...interface{}) //功能和`Printf()`一样,只是后面加了`panic()`.
func Panicln(v ...interface{}) //功能和` Println()`一样,只是后面加了`panic()`.
打印日志后产生后退出程序
func Fatal(v ...interface{}) //功能和`Print()`一样,只是后面加了`os.Exit(1)`.
func Fatalf(format string, v ...interface{}) //功能和`Printf()`一样,只是后面加了`os.Exit(1)`.
func Fatalln(v ...interface{}) //功能和` Println()`一样,只是后面加了`os.Exit(1)`.
修改日志输出格式
SetFlags可以改变日志输出的格式,主要改变的是日期时间格式和文件行号格式。
func SetFlags(flag int)
Ldate = 1 << iota //时间只包含日期: 2009/01/23
Ltime //时间只包含时分秒: 01:23:23
Lmicroseconds //时间包含时分秒毫秒: 01:23:23.123123.
Llongfile //日志产生的代码文件绝对路径和行号: /a/b/c/d.go:23
Lshortfile //日志产生的代码文件和行号: d.go:23.
LUTC //日期时间转为0时区的
LstdFlags = Ldate | Ltime //默认值
log.SetFlags(log.Ldate | log.Lshortfile)
log.Print("print:", "这是Printf:产生的日志", "\n")
log.Println("Println:", "这是Println产生的日志")
log.Printf("Printf:%s\n", "这是Printf:产生的日志")
$ go run main.go
2020/10/23 test.go:7: print:这是Printf:产生的日志
2020/10/23 test.go:8: Println: 这是Println产生的日志
2020/10/23 test.go:9: Printf:这是Printf:产生的日志
添加日志前缀
我们还可以给每一行日志加一个前缀。
func SetPrefix(prefix string)
log.SetPrefix("[DEBUG] ")
log.Print("print:", "这是Printf:产生的日志", "\n")
$ go run main.go
[DEBUG] 2020/10/23 test.go:10: print:这是Printf:产生的日志
输出到文件
默认情况下日志会输出到标准输出,我们可以使用SetOutput修改输出方式。
func SetOutput(w io.Writer)
f, _ := os.OpenFile("log.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
log.SetOutput(f)
log.Print("print:", "这是Printf:产生的日志", "\n")
log.Println("Println:", "这是Println产生的日志")
log.Printf("Printf:%s\n", "这是Printf:产生的日志")
这样子日志将被写到log.log文件中。
后记
这个log包的功能相对比较单一,缺少日志分级,日志文件切割,日志文件大小和个数控制等功能,通常在实际项目中我们会使用更加强大的第三方包来使用。
strconv
strconv包提供了字符串和其他golang基础类型的互相转换函数。
整数和字符串互换
i, err := strconv.Atoi("-42") // -42
s := strconv.Itoa(-42) //"-42"
布尔类型,浮点数,整数和字符串转换
b, err := strconv.ParseBool("true")
f, err := strconv.ParseFloat("3.1415", 64)
i, err := strconv.ParseInt("-42", 10, 64)
u, err := strconv.ParseUint("42", 10, 64)
s := strconv.FormatBool(true)
s := strconv.FormatFloat(3.1415, 'E', -1, 64)
s := strconv.FormatInt(-42, 16)
s := strconv.FormatUint(42, 16)
Quote 和 Unquote
strconv包中有对字符串加"的方法Quote,Unquote这是给字符串去".
fmt.Println(strconv.Quote(`"Hello 世界"`)) //"\"Hello\t世界\""
fmt.Println(strconv.QuoteRune('世')) // '世'
fmt.Println(strconv.QuoteRuneToASCII('世')) // '\u4e16'
fmt.Println(strconv.QuoteToASCII(`"Hello 世界"`)) //"\"Hello\t\u4e16\u754c\""
fmt.Println(strconv.Unquote(`"\"Hello\t世界\""`)) // "Hello 世界" <nil>
sort——golang排序操作
有时候我们需要对一些结果集进行排序,有序的数据集适合我们查找元素。
golang的sort包默认提供了对[]int、[]float64和[]string排序的支持。还有提供一个sort.Interface排序接口,函数sort.Sort将对实现sort.Interface的数据类型举行排序。
[]int排序
s := []int{5, 2, 6, 3, 1, 4}
sort.Ints(s)
fmt.Println(s) //[1 2 3 4 5 6]
[]float64排序
s := []float64{5.2, -1.3, 0.7, -3.8, 2.6}
sort.Float64s(s)
fmt.Println(s) //[-3.8 -1.3 0.7 2.6 5.2]
[]strings排序
s := []string{"Go", "Bravo", "Gopher", "Alpha", "Grin", "Delta"}
sort.Strings(s)
fmt.Println(s) //[Alpha Bravo Delta Go Gopher Grin]
Search在排序好的结果集查找元素
a := []int{1, 3, 6, 10, 15, 21, 28, 36, 45, 55}
x := 6
i := sort.Search(len(a), func(i int) bool { return a[i] >= x })
if i < len(a) && a[i] == x {
fmt.Printf("found %d at index %d in %v\n", x, i, a) //found 6 at index 2 in [1 3 6 10 15 21 28 36 45 55]
}
自建类型实现sort.Interface然后排序
type Float32Slice []float32
func (p Float32Slice) Len() int { return len(p) }
func (p Float32Slice) Less(i, j int) bool { return p[i] < p[j] }
func (p Float32Slice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
s := []float32{5.3, 9.2, 6.0, 3.8, 1.1, 4.5} // unsorted
sort.Sort(sort.Reverse(Float32Slice(s)))
fmt.Println(s) //[9.2 6 5.3 4.5 3.8 1.1]
Reverse可以实现逆序
s := []int{5, 2, 6, 3, 1, 4} // unsorted
sort.Sort(sort.Reverse(sort.IntSlice(s)))
fmt.Println(s) //[6 5 4 3 2 1]
sort.Reverse函数包含了reverse结构体他继承排序类型的sort.Interface,但是修改了 Less(i, j int) bool的方法。
func (r reverse) Less(i, j int) bool {
return r.Interface.Less(j, i)
}
go项目管理
现代语言都会有包管理器,集成单元测试功能。golang最早的包依赖管理基于gopath,最近几年慢慢淡化gopath,基于go mod。 基于go mod,golang慢慢完善自己的包管理器。
golang提供标准库testing,开发者可以非常方便的写出单元测试和基准测试代码。
go modules
go modules 介绍
go modules是go 1.11中的一个实验性选择加入功能。目前随着go 1.14 的发布,越来越多的项目已经采用go modules方式作为项目的包依赖管理。
设置 GO111MODULE
GO111MODULE 有三个值 off, on和auto,go.1.13以上的版本默认都是开启go modules的 。
- off:go tool chain 不会支持go module功能,寻找依赖包的方式将会沿用旧版本那种通过vendor目录或者GOPATH/src模式来查找。
- on:go tool chain 会使用go modules,而不会去GOPATH/src目录下查找,依赖包文件保持在$GOPATH/pkg下,允许同一个package多个版本并存,且多个项目可以共享缓存的module。
- auto:go tool chain将会根据当前目录来决定是否启用module功能。当前目录在$GOPATH/src之外且该目录包含go.mod文件或者当前文件在包含go.mod文件的目录下面则会开启 go modules。
go mod 命令介绍
go modules 在golang中使用go mod命令来实现。
$ go help mod
download download modules to local cache (下载依赖包到本地)
edit edit go.mod from tools or scripts (编辑go.mod)
graph print module requirement graph (列出模块依赖图)
init initialize new module in current directory (在当前目录下初始化go module)
tidy add missing and remove unused modules (下载缺失模块和移除不需要的模块)
vendor make vendored copy of dependencies (将依赖模块拷贝到vendor下)
verify verify dependencies have expected content (验证依赖模块)
why explain why packages or modules are needed (解释为什么需要依赖)
go mod 使用
创建目录
$ mkdir -p ~/gocode/hello
$ cd ~/gocode/hello/
初始化新module
$ go mod init github.com/youname/hello
go: creating new go.mod: module github.com/youname/hello
写代码
$ cat <<EOF > hello.go
package main
import (
"fmt"
"rsc.io/quote"
)
func main() {
fmt.Println(quote.Hello())
}
EOF
构建项目
$ go build
$ ./hello
你好,世界。
这个时候看下 go.mod 文件
$ cat go.mod
module github.com/you/hello
require rsc.io/quote v1.5.2
一旦项目使用go modules的方式解决包依赖,你日常的工作就是在你的go项目代码中添加improt语句,标准命令(go build 或者go test)将根据需要自动添加新的依赖包(更新go.mod并下载新的依赖)。 在需要时可以使用go get foo@v1.2.3,go get foo@master,go get foo@e3702bed2或直接编辑go.mod等命令选择更具体的依赖项版本。
以下还有些常用功能:
go list -m all - 查看将在构建中用于所有直接和间接依赖模块的版本信息
go list -u -m all - 查看所有直接和间接依赖模块的可用版本升级信息
go get -u -会升级到最新的次要版本或者修订版本(x.y.z, z是修订版本号, y是次要版本号)
go get -u=patch - 升级到最新的修订版本
go build ./... 或者go test ./... - 从模块根目录运行时构建或测试模块中的所有依赖模块
go.mod 文件介绍
go.mod 有module, require、replace和exclude 四个指令 module 指令声明其标识,该指令提供模块路径。模块中所有软件包的导入路径共享模块路径作为公共前缀。模块路径和从go.mod程序包目录的相对路径共同决定了程序包的导入路径。 require 指令指定的依赖模块 replace 指令可以替换依赖模块 exclude 指令可以忽略依赖项模块
国内goher使用go modules
由于墙的原因,国内开发者在使用go modules的时候会遇到很多依赖包下载不了的问题,下面提供几个解决方案
- 使用go proxy(推荐)
export GOPROXY="https://goproxy.io"
- 使用go mod replace 替换下载不了的包,例如golang.org下面的包
replace (
golang.org/x/crypto v0.0.0-20190313024323-a1f597ede03a => github.com/golang/crypto v0.0.0-20190313024323-a1f597ede03a
)
补充资料
模块版本定义规则
模块必须根据semver进行语义版本化,通常采用v(major).(minor).(patch)的形式,例如v0.1.0,v1.2.3或v1.5.0-rc.1。版本必需是v字母开头。 go mod 在拉取对应包版本的时候会找相应包的git tag(release tag和 pre release tag),如果对应包没有git tag 就会来取master 而对应的版本好会变成v0.0.0。go mod工具中的版本号格式为版本号 + 时间戳 + hash以下的版本都是合法的:
gopkg.in/tomb.v1 v1.0.0-20141024135613-dd632973f1e7
github.com/PuerkitoBio/goquery v1.4.1
gopkg.in/yaml.v2 <=v2.2.1
golang.org/x/net v0.0.0-20190125091013-d26f9f9a57f3
latest
总结
本小节介绍golang modules的使用,go modules本身有很多比较复杂的设计,你可以通过go modules官方英文文档做详细了解。go modules对golang 项目构建的基石,在实际项目中一定会经常接触到。
go test
go test是golang的轻量化单元测试工具,结合testing这个官方包,可以很方便为golang程序写单元测试和基准测试。
在之前go build命令介绍的时候说过,go build 编译包时,会忽略以“_test.go”结尾的文件。这些被忽略的_test.go文件正是go test的一部分。
在以_test.go为结尾的文件中,常见有两种类型的函数:
- 测试函数,以Test为函数名前缀的函数,用于测试程序是否按照正确的方式运行;使用go test命令执行测试函数并报告测试结果是PASS或FAIL。
- 基准测试(benchmark)函数,以Benchmark为函数名前缀的函数,它们用于衡量一些函数的性能;基准测试函数中一般会多次调用被测试的函数,然后收集平均执行时间。
无论是测试函数或者是基准测试函数都必须import testing
测试函数
测试函数的签名
func TestA(t *testing.T){
}
例如我们看下go的官方包 bytes.Compare 函数的测试
package test
import (
"bytes"
"testing"
)
var Compare = bytes.Compare
func TestCompareA(t *testing.T) {
var b = []byte("Hello Gophers!")
if Compare(b, b) != 0 {
t.Error("b != b")
}
if Compare(b, b[:1]) != 1 {
t.Error("b > b[:1] failed")
}
}
我们执行下 go test,这个命令会遍历当前目录下所有的测试函数.
$ go test
PASS
ok github.com/wida/gocode/test 0.001s
参数-v用于打印每个测试函数的名字和运行时间:
$ go test -v
=== RUN TestCompareA
--- PASS: TestCompareA (0.00s)
=== RUN TestCompareB
--- PASS: TestCompareB (0.00s)
PASS
ok github.com/wida/gocode/test 0.002s
参数-run 用于运行制定的测试函数,
$ go run -v -run "TestCompareA"
=== RUN TestCompareA
--- PASS: TestCompareA (0.00s)
PASS
ok github.com/wida/gocode/test 0.002s
run 后面的参数是正则匹配 -run "TestCompare" 会同时执行 TestCompareA 和 TestCompareB。
表驱动测试
在实际编写测试代码时,通常把要测试的输入值和期望的结果写在一起组成一个数据表(table),表(table)中的每条记录代表是一个含有输入值和期望值。还是看官方bytes.Compare的测试例子:
var compareTests = []struct {
a, b []byte
i int
}{
{[]byte(""), []byte(""), 0},
{[]byte("a"), []byte(""), 1},
{[]byte(""), []byte("a"), -1},
{[]byte("abc"), []byte("abc"), 0},
{[]byte("abd"), []byte("abc"), 1},
{[]byte("abc"), []byte("abd"), -1},
{[]byte("ab"), []byte("abc"), -1},
{[]byte("abc"), []byte("ab"), 1},
{[]byte("x"), []byte("ab"), 1},
{[]byte("ab"), []byte("x"), -1},
{[]byte("x"), []byte("a"), 1},
{[]byte("b"), []byte("x"), -1},
// test runtime·memeq's chunked implementation
{[]byte("abcdefgh"), []byte("abcdefgh"), 0},
{[]byte("abcdefghi"), []byte("abcdefghi"), 0},
{[]byte("abcdefghi"), []byte("abcdefghj"), -1},
{[]byte("abcdefghj"), []byte("abcdefghi"), 1},
// nil tests
{nil, nil, 0},
{[]byte(""), nil, 0},
{nil, []byte(""), 0},
{[]byte("a"), nil, 1},
{nil, []byte("a"), -1},
}
func TestCompareB(t *testing.T) {
for _, tt := range compareTests {
numShifts := 16
buffer := make([]byte, len(tt.b)+numShifts)
for offset := 0; offset <= numShifts; offset++ {
shiftedB := buffer[offset : len(tt.b)+offset]
copy(shiftedB, tt.b)
cmp := Compare(tt.a, shiftedB)
if cmp != tt.i {
t.Errorf(`Compare(%q, %q), offset %d = %v; want %v`, tt.a, tt.b, offset, cmp, tt.i)
}
}
}
}
$ go test -v -run "TestCompareB"
=== RUN TestCompareB
--- PASS: TestCompareB (0.00s)
PASS
ok github.com/wida/gocode/test 0.004s
基准测试函数
基准测试函数的函数签名如下
func BenchmarkTestB(b *testing.B) {
}
我们还是一官方的bytes.Compare 为例写一个基准测试
func BenchmarkComare(b *testing.B) {
for i := 0; i < b.N; i++ {
Compare([]byte("abcdefgh"), []byte("abcdefgh"))
}
}
基准测试的运行 需要加 -bench参数
$ go test -bench BenchmarkCompare
goos: linux
goarch: amd64
pkg: github.com/wida/gocode/test
BenchmarkCompare-4 30000000 35.4 ns/op
PASS
ok github.com/wida/gocode/test 1.111s
报告显示我们的测试程序跑了30000000次,每次平均耗时35.4纳秒。
使用 b.ResetTimer
有些时候我们的基础测试函数逻辑有点复杂或者在准备测试数据,如下
func BenchmarkComare(b *testing.B) {
//准备数据
...
b.ResetTimer()
for i := 0; i < b.N; i++ {
Compare([]byte("abcdefgh"), []byte("abcdefgh"))
}
}
我们可以使用 b.ResetTimer() 将准备数据的时间排除在总统计时间之外。
go 命令
go语言本身自带一个命令行工具,这些命令在项目开发中会反复的使用,我们发点时间先了解下。我们看下完整的go 命令:
$ go
Go is a tool for managing Go source code.
Usage:
go <command> [arguments]
The commands are:
bug start a bug report
build compile packages and dependencies
clean remove object files and cached files
doc show documentation for package or symbol
env print Go environment information
fix update packages to use new APIs
fmt gofmt (reformat) package sources
generate generate Go files by processing source
get download and install packages and dependencies
install compile and install packages and dependencies
list list packages or modules
mod module maintenance
run compile and run Go program
test test packages
tool run specified go tool
version print Go version
vet report likely mistakes in packages
在这些go命令中,有些命令相对功能简单,有些则相对复杂些,我们分几个小节介绍这些命令的使用场景。本小节我们先看 go build 和 go get。
go build
go build命令 编译我们指定的go源码文件,或者指定路径名的包,以及它们的依赖包。 如果我们在执行go build命令时没有任何参数,那么该命令将试图编译当前目录所对应的代码文件。
在编译main 包时,将以第一个参数文件或者路径,作为输出的可执行文件名,例如 第一个源文件('go build ed.go rx.go' 生产'ed'或'ed.exe') 或源代码目录('go build unix/sam'生成'sam'或'sam.exe')。
编译多个包或单个非main包时,go build 编译包但丢弃生成的对象,这种情况仅用作检查包是否可以顺利编译通过。
go build 编译包时,会忽略以“_test.go”结尾的文件。
我们平常在开发一些兼容操作系统底层api的项目时,我们可以根据相应的操作系统编写不同的兼容代码,例如我们在处理signal的项目,linux和Windows signal是有差异的,我们可以通过加操作系统后缀的方式来命名文件,例如sigal_linux.go sigal_windows.go,在go build的时候会更加当前的操作系统($GOOS 环境变量)来下选择编译文件,而忽略非该操作系统的文件。上面的例子如果在linux下 go build 会编译 sigal_linux.go 而忽略 sigal_windows.go,而windows系统下在反之。
go build 有好多的个参数,其中比较常用的是
- -o 指定输出的文件名,可以带上路径,例如 go build -o a/b/c。
- -race 开启编译的时候检测数据竞争。
- -gcflags 这个参数在编译优化和逃逸分析中经常会使用到。
go build -tags
上面我们介绍了go build 可以使用加操作系统后缀的文件名来选择性编译文件。还有一种方法来实现条件编译,那就是使用go build -tags tag.list
我创建一个项目buildtag-demo,目录架构为
.
├── go.mod
├── main.go
├── tag_d.go
└── tag_p.go
我们在main.go 里头的代码是
package main
func main() {
debug()
}
tag_d.go 代表debug场景下要编译的文件,文件内容是
// +build debug
package main
import "fmt"
func debug() {
fmt.Println("debug ")
}
tag_p.go 代表生产环境下要编译的文件,文件内容是
// +build !debug
package main
func debug() {
//fmt.Println("debug ")
}
我们编译和运行下项目
$ go build
$ ./buildtag-demo
//nothing 没有任何输出
$ go build -tags debug
$ ./buildtag-demo
debug
使用方式
+build注释需要在package语句之前,而且之后还需要一行空行。+build后面跟一些条件 只有当条件满足的时候才编译此文件。+build的规则不仅见约束.go结尾的文件,还可以约束go的所有源码文件。
+build条件语法:
- 只能是是数字、字母、_(下划线)
- 多个条件之间,空格表示OR;逗号表示AND;叹号(!)表示NOT
- 可以有多行
+build,它们之间的关系是AND。如:// +build linux darwin // +build 386 等价于 // +build (linux OR darwin) AND 386 - 加上
// +build ignore的原件文件可以不被编译。
go get
go get 在go modules出现之前一直作为go获取依赖包的工具,在go modules出现后,go get的功能和之前有了不一样的定位。现在go get主要的功能是获取解析并将依赖项添加到当前开发模块然后构建并安装它们。
参考 go modules 章节
go还提供了其它很多的工具,例如下面的这些工具
- go bug 给go官方提交go bug(执行命令后会在浏览器弹出go github issue提交页面)
- go clean 这个命令是用来移除当前源码包和关联源码包里面编译生成的文件.
- go doc 这个命令用来从包文件中提取顶级声明的首行注释以及每个对象的相关注释,并生成相关文档。
- go env 这个命令我们之前介绍过,是用来获取go的环境变量
- go fix 用于将你的go代码从旧的发行版迁移到最新的发行版,它主要负责简单的、重复的、枯燥无味的修改工作,如果像 API 等复杂的函数修改,工具则会给出文件名和代码行数的提示以便让开发人员快速定位并升级代码。
- go fmt 格式化go代码。
- go generate 这个命令用来生成go代码文件,平常工作中比较少接触到。
- go install 编译生产可执行文件,同时将可执行文件移到$GOBIN这个环境变量设置的目录下
- go list 查看当前项目的依赖模块(包),在go modules 小节会看到一些具体用法
- go mod go的包管理工具,go modules会单独介绍
- go run 编译和运行go程序
- go test go的单元测试框架,会在go test小节单独介绍
- go tool 这个命令聚合了很多go工具集,主要关注 go tool pprof 和 go tool cgo这两个命令,在go 性能调优和cgo的章节会讲到这两个命令。
- go version 查看go当前的版本
- go vet 用来分析当前目录的代码是否正确。
参考资料
并发和并行
并发不是并行
golang被成为原生支持并发的语言,那么什么是并发? go语言之父Rob Pike就专门回答过这个问题,并且和做了一个 并发不是并行的演讲。
并发(Concurrency)将相互独立的执行过程综合到一起的编程技术。
并行(Parallelism)同时执行(通常是相关的)计算任务的编程技术。
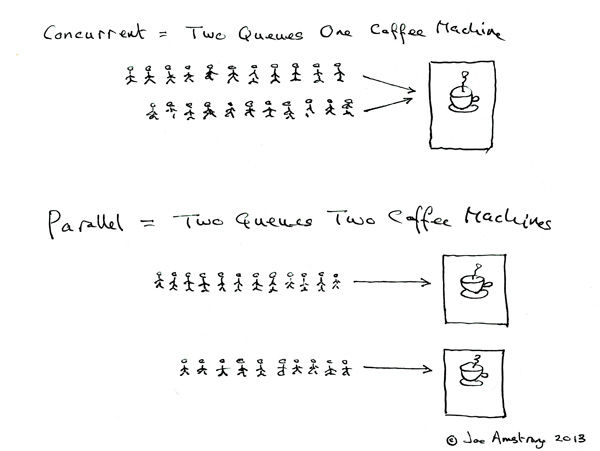
上图是Erlang 之父 Joe Armstrong来解释并发和并行。并发是两队伍交替使用咖啡机,并行是两个队伍两个咖啡机。
并发是指同时处理很多事情,主要关注的是流程合理优化组合,这一点很像我们小时候学的《统筹时间》关于如何优化任务顺序然后更有效率。
而并行是指同时能完成很多事情。
两者不同,但相关。
一个注重点是组合,一个注重点是执行。
并发提供了一种方式让我们能够设计一种方案将问题并行的解决。
CSP并发模型
传统的并发模型(例如Java,C ++和Python程序时通常使用)要求程序员使用共享内存在线程之间进行通信。通常共享数据结构用锁保护,线程将争夺这些锁以访问数据。 golang虽然也支持这种并发模型,但是go更鼓励使用CSP(Communicating Sequential Processe,CSP)并发模型。CSP描述两个独立的并发实体(goroutine)通过共享的通讯 channel(管道)进行通信的并发模型。CSP中channel是第一类对象,它不关注发送消息的实体,而关注与发送消息时使用的channel。
“Don’t communicate by sharing memory, share memory by communicating”——不要通过共享内存来通信,而应该通过通信来共享内存。
参考资料
原子操作
什么是原子操作
原子操作(atomic operation)是指不会被线程调度机制打断的一个或一组操作。原子操作是不可分割的,在执行完毕之前不会被任何其它任务或事件中断。和锁相比原子操作的优点是相对较快,并且不会有死锁问题,缺点是它仅仅能执行有限的一组操作,并且通常这些操作还不能以有效地合成更复杂的操作。
golang有专门的一个package sync/atomic 来实现原子操作的相关功能。
原子增减
golang 对一个数值类型进行原子性增减。
有如下几个api函数
func AddInt32(addr *int32, delta int32) (new int32)
func AddInt64(addr *int64, delta int64) (new int64)
func AddUint32(addr *uint32, delta uint32) (new uint32)
func AddUint64(addr *uint64, delta uint64) (new uint64)
func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
package main
import (
"fmt"
"sync/atomic"
"time"
)
func main(){
var a int32= 0
for i:=0;i<100;i++ {
go func() {
atomic.AddInt32(&a,1) //这边是+1,如果要减一 那就第二个参数就是 -1
}()
}
time.Sleep(1e9)
fmt.Println(a)
a = 0
for i:=0;i<100;i++ {
go func() {
a ++ //这边的操作非原子性 所以结果可能不是等于100,这边顺带说明 a++ 是不具有原子性的
}()
}
time.Sleep(1e9)
fmt.Println(a)
}
$ go run main.go
100
94
我们看下汇编
$ go build -gcflags -S 2>&1 | grep ".go:12" |grep -v "PCDATA"
0x0000 00000 (/home/wida/gocode/atomic-demo/main.go:12) MOVL $1, AX
0x0005 00005 (/home/wida/gocode/atomic-demo/main.go:12) MOVQ "".&a+8(SP), CX
0x000a 00010 (/home/wida/gocode/atomic-demo/main.go:12) LOCK
0x000b 00011 (/home/wida/gocode/atomic-demo/main.go:12) XADDL AX, (CX)
$ go build -gcflags -S 2>&1 | grep ".go:21" |grep -v "PCDATA"
0x0000 00000 (/home/wida/gocode/atomic-demo/main.go:21) MOVQ "".&a+8(SP), AX
0x0005 00005 (/home/wida/gocode/atomic-demo/main.go:21) INCL (AX)
原子操作在底层使用专用cup指令支持的,X86平台下LOCK和XADD,LOCK会锁总线是个指令前缀和其他指令配合实现原子操作,XADDL AX, (CX) 指令将 交换AX和CX指针指向的值,同时AX的值和CX指针指向的值相加,结果保存在CX指针指向的值。
比较并交换
原子性的比较addr指针指向的值和old是不是一样,一样的话就会发生交换,返回值是布尔型,会返回是否交换。 有如下几个api函数:
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)
func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)
func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)
package main
import (
"fmt"
"sync/atomic"
)
func main(){
var a int32=100
b := atomic.CompareAndSwapInt32(&a,100,101)
fmt.Println(b,a)
b = atomic.CompareAndSwapInt32(&a,100,101)
fmt.Println(b,a)
}
$ go run main.go
true 101
同样我们看下汇编底层的代码
$ go build -gcflags -S 2>&1 | grep ".go:8" |grep -v "PCDATA"
0x0052 00082 (/home/wida/gocode/atomic-demo/main.go:8) MOVL $100, AX
0x0057 00087 (/home/wida/gocode/atomic-demo/main.go:8) MOVL $101, DX
0x005c 00092 (/home/wida/gocode/atomic-demo/main.go:8) LOCK
0x005d 00093 (/home/wida/gocode/atomic-demo/main.go:8) CMPXCHGL DX, (CX) #如果(CX)值和AX值相等,这(CX)值变成DX的值,同时修改 zf值为1,否则zf为0
0x0060 00096 (/home/wida/gocode/atomic-demo/main.go:8) SETEQ AL
0x0063 00099 (/home/wida/gocode/atomic-demo/main.go:8) MOVB AL, "".b+71(SP)
载入和存储
原子性加载数据,api有如下几个
func LoadInt32(addr *int32) (val int32)
func LoadInt64(addr *int64) (val int64)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func LoadUint32(addr *uint32) (val uint32)
func LoadUint64(addr *uint64) (val uint64)
func LoadUintptr(addr *uintptr) (val uintptr)
原子性存储数据,api有如下几个
func StoreInt32(addr *int32, val int32)
func StoreInt64(addr *int64, val int64)
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
func StoreUint32(addr *uint32, val uint32)
func StoreUint64(addr *uint64, val uint64)
func StoreUintptr(addr *uintptr, val uintptr)
package main
import (
"fmt"
"sync/atomic"
"time"
)
func main(){
var a int32=100
if atomic.LoadInt32(&a) == 100 {
fmt.Println("that's 100")
}
b := atomic.LoadInt32(&a) + 10
fmt.Println(b)
for i:=0;i<100;i++ {
go func(i int) {
atomic.StoreInt32(&a,int32(i))
}(i)
}
time.Sleep(3e9)
fmt.Println(a)
}
$ go run main.go
that's 100
110
99
LoadInt32和StoreInt32 汇编代码中可以看到都没有使用LOCK锁总线,因为到汇编底层这两个操作都是一个汇编指令,所以本身就具有原子性。
交换
原子性替换addr指针的值为new值,返回值返回addr原先指向的值。
func SwapInt32(addr *int32, new int32) (old int32)
func SwapInt64(addr *int64, new int64) (old int64)
func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
func SwapUint32(addr *uint32, new uint32) (old uint32)
func SwapUint64(addr *uint64, new uint64) (old uint64)
func SwapUintptr(addr *uintptr, new uintptr) (old uintptr)
package main
import (
"fmt"
"sync/atomic"
)
func main(){
var a int32=100
old := atomic.SwapInt32(&a,101)
fmt.Println(old,a)
}
$ go run main.go
100 101
SwapInt32和CompareAndSwapInt32 在汇编底层指令上不一样,SwapInt32同样也是一条汇编指令,所以也没有用到LOCK。
新类型Value
我们看到上面的几个api都是数值类型的,那么非数值类似的原子操作怎么使用呢?atomic在Go语言在1.4中加入了新的类型Value,带有Load和Store接口。
type Value struct {
v interface{}
}
func (v *Value) Load() (x interface{})
func (v *Value) Store(x interface{})
package main
import (
"fmt"
"sync/atomic"
"time"
)
func loadConfig() map[string]string {
return make(map[string]string)
}
func main() {
var config atomic.Value
config.Store(loadConfig())
go func() {
for {
time.Sleep(1 * time.Second)
config.Store(loadConfig())
}
}()
for i := 0; i < 10; i++ {
time.Sleep(1 * time.Second)
c := config.Load()
fmt.Printf("%p \n", c) //打印 c的指针
}
}
$ go run main.go
0xc00008c000
0xc00008c000
0xc000076180
0xc00008c030
0xc00008c030
0xc0000761b0
0xc0000761e0
0xc0000761e0
0xc000076210
0xc00009a060
总结
本小节介绍了golang的原子操作,原子操作的使用在并发系统里头十分的重要,比锁快,没死锁问题对并发编程十分的友好。
goroutine同步
互斥锁(sync.Mutex)和读写锁(sync.RWMutex)
类似其他语言,golang也提供了互斥锁和读写锁的的同步原语。
我们先看下go中互斥锁(sync.Mutex)的使用。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
a := 0
for i:=0;i< 100;i++ {
go func() {
a += 1
}()
}
time.Sleep(1e9)
fmt.Println(a)
a = 0
mutex := sync.Mutex{}
for i:=0;i< 100;i++ {
go func() {
mutex.Lock()
defer mutex.Unlock()
a ++
}()
}
time.Sleep(1e9)
fmt.Println(a)
}
$ go run main.go
85
100
我们在看下读写锁(sync.RWMutex)。
读写锁:读的时候不会阻塞读,会阻塞写;写的时候会阻塞写和读,我们可以用这个特性实现线程安全的map。
import "sync"
type safeMap struct {
rwmut sync.RWMutex
Map map[string]int
}
func (sm *safeMap)Read(key string)(int,bool){
sm.rwmut.RLock()
defer sm.rwmut.RUnlock()
if v,found := sm.Map[key];!found {
return 0,false
}else {
return v,true
}
}
func (sm *safeMap)Set(key string,val int) {
sm.rwmut.Lock()
defer sm.rwmut.Unlock()
sm.Map[key] = val
}
WaitGroup
WaitGroup 常用在等goroutine结束。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
wg :=sync.WaitGroup{}
wg.Add(2) //这边说明有2个任务
go func() {
defer wg.Done() //代表任务1结束
time.Sleep(1e9)
fmt.Println("after 1 second")
}()
go func() {
defer wg.Done()//代表任务2结束
time.Sleep(2e9)
fmt.Println("after 2 second")
}()
wg.Wait() //等待所有任务结束
fmt.Println("the end")
}
after 1 second
after 2 second
the end
总结
本小节列举了goroutine使用传统的Mutex和WaitGroup做"线程"同步的例子,在go语言中,官方注重推荐使用channel做“线程”同步,下个小节我们着重介绍channel的使用。
条件变量-sync.Cond
什么是条件变量
与sync.Mutex不同,sync.Cond的作用是在对应的共享数据的状态发生变化时,通知一个或者所以因为共享数据而被阻塞的goroutine。sync.Cond总是与sync.Mutex(或者sync.RWMutex)组合使用。sync.Mutex为共享数据的访问提供互斥锁支持,而sync.Cond可以在共享数据的状态的变化向相关goroutine发出通知。
sync.Cond api
sync.Cond总共有3个方法,一个NewCond创建函数
func NewCond(l Locker) *Cond # 创建NewCond 参数需要是一个`Locker` 一般使用 `sync.Mutex`或者`sync.RWMutex`
func (c *Cond) Wait() #阻塞当前goroutine,通过`Signal`或者`Broadcast`唤醒
func (c *Cond) Signal() #唤醒一个被阻塞的goroutine,如果没有的话会忽略。
func (c *Cond) Broadcast() #唤醒一个所有阻塞的goroutine。
我们从sync.Cond提过的api可以看到,它有两种模式,单播和广播。
单播
package main
import (
"fmt"
"sync"
"time"
)
func main() {
cond := sync.NewCond(new(sync.Mutex))
condition := 0
// Consumer
go func() {
for {
cond.L.Lock()
for condition == 0 {
cond.Wait()
}
condition--
fmt.Printf("Consumer: %d\n", condition)
cond.Signal() //注意这边会有多次被忽略的情况
cond.L.Unlock()
}
}()
// Producer
for {
time.Sleep(time.Second)
cond.L.Lock()
for condition == 3 {
cond.Wait()
}
condition +=3
fmt.Printf("Producer: %d\n", condition)
cond.Signal()
cond.L.Unlock()
}
}
$ go run main.go
Producer: 3
Consumer: 2
Consumer: 1
Consumer: 0
Producer: 3
Consumer: 2
Consumer: 1
Consumer: 0
多播
package main
import (
"fmt"
)
var condition = false
func main() {
m := sync.Mutex{}
c := sync.NewCond(&m)
go func() {
c.L.Lock()
for condition == false {
fmt.Println("goroutine1 wait")
c.Wait()
}
fmt.Println("goroutine1 exit")
c.L.Unlock()
}()
go func() {
c.L.Lock()
for condition == false {
fmt.Println("goroutine2 wait")
c.Wait()
}
fmt.Println("goroutine2 exit")
c.L.Unlock()
}()
time.Sleep(2e9)
c.L.Lock()
condition = true
c.Broadcast()
c.L.Unlock()
time.Sleep(2e9)
}
$ go run main.go
goroutine1 wait
goroutine2 wait
broadcast
goroutine1 exit
goroutine2 exit
总结
本小节届时将条件变量的使用,介绍了单播和多播的使用方式。
使用channel做goroutine同步
channel和goroutine是golang CSP并发模型的承载体,是goroutine同步绝对主角。channel的使用场景远比Mutex和WaitGroup多得多。
实现和WaitGroup一样的功能
func main() {
ch := make(chan struct{}, 2)
go func() {
defer func() {
ch <- struct{}{}
}()
time.Sleep(1e9)
fmt.Println("after 1 second")
}()
go func() {
defer func() {
ch <- struct{}{}
}()
time.Sleep(2e9)
fmt.Println("after 2 second")
}()
i := 0
for _ = range ch {
i++
if i == 2 {
close(ch)
}
}
fmt.Println("the end")
}
生产消费模型
这是个常用的1对N的生产消费模型,常常用于消费redis队列。
package main
import (
"os"
"fmt"
"os/signal"
"syscall"
"sync"
)
var quit bool = false
const THREAD_NUM = 5
func main() {
sigs := make(chan os.Signal, 1)
//signal.Notify 注册这个给定的通道用于接收特定信号。
signal.Notify(sigs, syscall.SIGINT, syscall.SIGUSR1, syscall.SIGUSR2)
quitChan := make(chan bool)
rowkeyChan := make(chan string, THREAD_NUM)
go func() {
<-sigs //等待信号
quit = true
close(rowkeyChan)
}()
var wg sync.WaitGroup
for i := 0; i < THREAD_NUM;i++ {
wg.Add(1)
go func(n int) {
for {
rowkey,ok := <- rowkeyChan
if !ok {
break
}
//do something with rowkey
fmt.Println(rowkey)
}
wg.Done()
}(i)
}
go func() {
wg.Wait()
quitChan <- true
}()
for !quit {
//rowkey 可能来着redis的队列
rowkey := ""
rowkeyChan <- rowkey
}
<- quitChan
}
上面的代码稍微修改下很容易支持N:M的生产消费模型,这边就不再赘述。
赛道模型
在现实很多场景我们需要并发的做个任务,我们想知道他们的先后顺序,或者只想知道最快的那个。channel的特性很容易做到这个需求
package main
import (
"fmt"
"net/http"
)
func main() {
ch := make(chan string)
go func() {
http.Head("https://www.taobao.com")
ch <- "taobao"
}()
go func() {
http.Head("https://www.jd.com")
ch <- "jd"
}()
go func() {
http.Head("https://www.vip.com")
ch <- "vip"
}()
//只想知道最快的
dm := <- ch
fmt.Println(dm)
/* 知道它们的排名
for dm:= range ch {
fmt.Println(dm)
}
*/
}
如何控制并发数
虽然golang新开一个goroutine占用的资源很小,但是无谓的goroutine开销对golang的调度性能很有影响,同时也会浪费cpu的资源。那么golang中如何控制并发数。
方式1——使用带缓冲的channel
package main
import (
"fmt"
"time"
)
type Task struct {
Id int
}
func work(task *Task,limit chan struct{}) {
time.Sleep(1e9)
fmt.Println(task.Id)
<- limit
}
func main() {
ch := make(chan *Task,10)
limit := make(chan struct{},3)
go func() {
for i:=0;i<10;i++ {
ch <- &Task{i}
}
close(ch)
}()
for {
task ,ok :=<- ch
if ok {
limit <- struct{}{}
go work(task,limit)
}
}
}
方式2——使用master-worker模型,worker数量固定
package main
import (
"fmt"
"time"
)
const WorkerNum = 3
type Task struct {
Id int
}
func work(ch chan *Task) {
for {//worker中循环消费任务
task,ok :=<- ch
if ok {
time.Sleep(1e9)
fmt.Println(task.Id)
}
}
}
func main() {
ch := make(chan *Task,3)
exit := make(chan struct{})
go func() {
for i:=0;i<10;i++ {
ch <- &Task{i}
}
close(ch)
}()
for i:=0;i<WorkerNum;i++{ //控制worker数量
go work(ch)
}
<- exit
}
控制goroutine优雅退出
除了我们需要控制goroutine的数量之外,我们还需要控制goroutine的生命周期同样以防止不不要的资源和性能消耗。那么接下来我们介绍下控制goroutine生命周期的办法。
方法1——goroutine超时控制
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan struct{})
task := func() {
time.Sleep(3e9)
ch <- struct{}{}
}
go task()
select {
case <-ch: //在3s内正常完成
fmt.Println("task finish")
case <-time.After(3*time.Second): //超过3秒
fmt.Println("timeout")
}
}
$ go run main.go
timeout
我们使用了 slecet 和 time.After 来控制goroutine超时。
方法2——使用context.Context
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx ,cancel:= context.WithCancel(context.Background()) //使用带cancel函数的context
task := func(ctx context.Context) {
for {
select {
case <-ctx.Done(): //cancel函数已经被执行了
default:
time.Sleep(1e9)
fmt.Println("hello")
}
}
}
go task(ctx)
time.Sleep(3e9) //等待3s
cancel() //让goroutine退出
}
$ go run main.go
hello
hello
当然我们还可以使用 context.WithTimeout的方式
package main
import (
"context"
"fmt"
"time"
)
func main() {
exit := make(chan struct{})
ctx,_ := context.WithTimeout(context.Background(),3*time.Second) //使用带超时的context
task := func(ctx context.Context) {
HE:
for {
select {
case <-ctx.Done(): //cancel函数已经被执行了
break HE //退出for循环
default:
time.Sleep(1e9)
fmt.Println("hello")
}
}
exit<- struct{}{}
}
go task(ctx)
<-exit
}
$ go run main.go
hello
hello
hello
这样的用法和上面的用法的区别是可以不需要手动去调用cancel函数。
总结
本小节我们介绍了使用channel同步goroutine的方法,介绍了channel的常见使用场景,已经如果控制goroutine的几种方法。这些方法在很是实际开发中都会用到。
sync.Once
sync.Once提供一种机制来保证某个函数只执行一次,常常用于初始化对象。 只有一个api:
func (o *Once) Do(f func())
我们来写个demo
package main
import (
"fmt"
"sync"
"time"
)
func main() {
once := sync.Once{}
a :=1
i:=0
for i <10{
go func() {
once.Do(func() {
a++
})
}()
i++
}
time.Sleep(1e9)
fmt.Println(a)
}
$ go run main.go
2
上面的例子中,Once.Do 被执行了十次,他包裹的函数却只被执行了一次。
我们来看下sync.Once的源码:
type Once struct {
done uint32 //状态值
m Mutex //互斥锁
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 { //等于0的时候代表没被执行过
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock() //确保只有一个goroutine能到锁
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1) //原子操作改变状态
f()
}
}
从源码上看,他是利用sync.Mutex和原子操作来实现的。
并发安全map —— sync.Map
go原生的map不是线程安全的,在并发读写的时候会触发concurrent map read and map write的panic。
map应该是属于go语言非常高频使用的数据结构。早期go标准库并没有提供线程安全的map,开发者只能自己实现,后面go吸取社区需求提供了线程安全的map——sync.Map。
sync.Map 提供5个如下api:
func (m *Map) Delete(key interface{}) //删除这个key的value
func (m *Map) Load(key interface{}) (value interface{}, ok bool) //加载这个key的value
func (m *Map) LoadOrStore(key, value interface{}) (actual interface{}, loaded bool) //原子操作加载,如果没有则存储
func (m *Map) Range(f func(key, value interface{}) bool) //遍历kv
func (m *Map) Store(key, value interface{}) //存储
使用sync.Map
package main
import (
"fmt"
"sync"
)
func main() {
sMap := sync.Map{}
sMap.Store("a","b")
ret,_:= sMap.Load("a")
fmt.Printf("ret1 %t \n",ret.(string) == "b" )
ret,loaded :=sMap.LoadOrStore("a","c")
fmt.Printf("ret2 %t loaded:%t \n",ret.(string) == "b",loaded )
ret,loaded =sMap.LoadOrStore("d","c")
fmt.Printf("loaded %t \n",loaded)
sMap.Store("e","f")
sMap.Delete("e")
sMap.Range(func(key, value interface{}) bool {
fmt.Printf("k:%s v:%s \n", key.(string),value.(string))
return true
})
}
$ go run main.go
ret1 true
ret2 true loaded:true
loaded false
k:a v:b
k:d v:c
sync.Map底层实现
sync.Map的结构体
type Map struct {
mu Mutex //互斥锁保护dirty
read atomic.Value //存读的数据,只读并发安全,存储的数据类型为readOnly
dirty map[interface{}]*entry //包含最新写入的数据,等misses到阈值会上升为read
misses int //计数器,当读read的时候miss了就加+
}
type readOnly struct {
m map[interface{}]*entry
amended bool //dirty的数据和这里的m中的数据有差异的时候true
}
从结构体上看Map有一定指针数据冗余,但是因为是指针数据,所以冗余的数据量不大。
Load的源码:
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
read, _ := m.read.Load().(readOnly) //读只读的数据
e, ok := read.m[key]
if !ok && read.amended { //如果没有读到且read的数据和drity数据不一致的时候
m.mu.Lock()
read, _ = m.read.Load().(readOnly) //加锁后二次确认
e, ok = read.m[key]
if !ok && read.amended { //如果没有读到且 read的数据和drity数据不一致的时候
e, ok = m.dirty[key]
m.missLocked() //misses +1,如果 misses 大于等于 m.dirty 则发送 read的值指向ditry
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
Store的源码:
func (m *Map) Store(key, value interface{}) {
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) { //如果在read中找到则尝试更新,tryStore中判断key是否已经被标识删除,如果已经被上传则更新不成功
return
}
m.mu.Lock()
read, _ = m.read.Load().(readOnly) //同上二次确认
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {// 如果entry被标记expunge,则表明dirty没有key,可添加入dirty,并更新entry。
m.dirty[key] = e
}
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok { //如果dirty存在该key
e.storeLocked(&value)
} else { //key不存在
if !read.amended { //read 和 dirty 一致
// 将read中未删除的数据加入到dirty中
m.dirtyLocked()
// amended标记为read与dirty不一致,因为即将加入新数据。
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
Delete的源码:
// Delete deletes the value for a key.
func (m *Map) Delete(key interface{}) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended { //在read中没有找到且 read和dirty不一致
m.mu.Lock()
read, _ = m.read.Load().(readOnly) //加锁二次确认
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key) //从dirty中删除
}
m.mu.Unlock()
}
if ok { //如果key在read中存在
e.delete() //将指针置为nil,标记删除
}
}
优缺点
优点: 通过read和dirty冗余的方式实现读写分离,减少锁频率来提高性能。
缺点:大量写的时候会导致read读不到数据而进一步加锁读取dirty,同时多次miss的情况下dirty也会频繁升级为read影响性能。
因此sync.Map的使用场景应该是读多,写少。
总结
本小节介绍了sync.Map的使用,通过源码的方式了解sync.Map的底层实现,同时介绍了它的优缺点,以及使用场景。
sync.Pool(临时对象池)
什么是sync.Pool
golang是带GC(垃圾回收)的语言,如果高频率的生成对象,然后有废弃这样子会给gc带来很大的负担,而且在go的内存申请上也会出现比较大的抖动。那么有什么办法减少gc负担,重用这些对象,然后又能让go的内存平缓些呢?答案是使用sync.Pool。
sync.Pool是golang用来存储临时对象的,这些对象通常是高频率生成销毁(这边还需要注意下,我们所说的对象是堆内存上的,而不是在栈内存上)。
使用sync.Pool
sync.Pool 有两个对外API
func (p *Pool) Get() interface{}
func (p *Pool) Put(x interface{})
另外sync.Pool对象初始化的时候需要指定属性New是一个 func() interface{}函数类型,用来在没有可复用对象时重新生成对象。
其实sync.Pool的使用非常频繁,不管事go标准库还是第三方库都非常多的使用。
在标准库fmt就使用到sync.Pool,我们追踪下fmt.Printf的源码:
func Printf(format string, a ...interface{}) (n int, err error) {
return Fprintf(os.Stdout, format, a...)
}
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
p.free()zongj
return
}
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) }, //指定生成对象函数
}
func newPrinter() *pp {
p := ppFree.Get().(*pp) //从pool中获取可复用对象,如果没有对象池会重新生成一个,注意这边拿到对象后会reset对象
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) free() {
if cap(p.buf) > 64<<10 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p) //用完后重新放到pool中
}
从上面的案例中大概可以看出sync.Pool是如何使用的。接下来我们写一个demo程序,看下另外一个sync.Pool的高频使用场景
package main
import (
"io"
"log"
"net"
"sync"
)
func main() {
bufpool := sync.Pool{}
bufpool.New = func() interface{} {
return make([]byte, 32768)
}
Pipe := func(c1, c2 io.ReadWriteCloser) {
b := bufpool.Get().([]byte)
b2 := bufpool.Get().([]byte)
defer func() {
bufpool.Put(b)
bufpool.Put(b2)
c1.Close()
c2.Close()
}()
go io.CopyBuffer(c1, c2, b)
io.CopyBuffer(c2, c1, b2)
}
l,err := net.Listen("tcp",":9999")
if err !=nil {
log.Fatal(err)
}
for {
conn,err := l.Accept()
if err !=nil {
log.Fatal(err)
}
client ,err:= net.Dial("tcp","127.0.0.1:80")
if err !=nil {
log.Fatal(err)
}
go Pipe(conn,client)
}
}
这是个的代理程序,任何连到本机9999端口的tcp链接都会转发到本地的80端口。我们使用io.CopyBuffer实现数据双工互相拷贝。
io.CopyBuffer会频繁使用到缓存[]byte对象,我们用sync.Pool重复使用[]byte.
运行一下程序
$ go run main.go
$ curl http://localhost:9999
总结
本小节介绍了sync.Pool的使用方式。sync.Pool能减轻go GC的负担,同时减少内存的分配,是保障go程序内存分配平缓的重要手段。
Semaphore(信号量)
什么是Semaphore(信号量,信号标)
Semaphore是一种同步对象,用来存0到指定值的计数值。信号量如果计数值可以是任意整数则称为计数信号量(一般信号量),如果值只能是0和1则叫二进制信号量,也就是我们常见的互斥锁(Mutex)。
计数信号量具备两种操作动作,称为V与P。V操作会增加信号量计数器的数值,P操作会减少它。go标准库没有实现信号量,但是拓展同步库里头实现了(golang.org/x/sync/semaphore)计数信号量叫做 Weighted——加权信号量。
我们先看下Weighted结构体
type Weighted struct {
size int64
cur int64
mu sync.Mutex
waiters list.List
}
Weighted有四个对外api
func NewWeighted(n int64) *Weighted
func (s *Weighted) Acquire(ctx context.Context, n int64) error
func (s *Weighted) Release(n int64)
func (s *Weighted) TryAcquire(n int64) bool
运作方式:
初始化,给与它一个整数值。 运行P(Acquire),信号标S(size)的值将被减少。企图进入临界区段的goroutine,需要先运行P(Acquire)。当信号标S(size)减为负值时,goroutine会被阻塞,不能继续;当信号标S(size)不为负值时,goroutine可以获准进入临界区段。 运行V(Release),信号标S(size)的值会被增加。结束离开临界区段的goroutine,将会运行V(Release)。当信号标S(size)不为负值时,先前被挡住的其他goroutine,将可获准进入临界区段。
TryAcquire的作用和Acquire类似,但是TryAcquire不会阻塞,发现进不去临界区段就会返回false。
使用Semaphore
我们在channel做goroutine同步的时候介绍了用channel控制goroutine数量并发数量的例子。信号量非常适合做类似的事情。
我们写一个控制goroutine并发数为机器cpu核数的程序程序。
package main
import (
"context"
"fmt"
"log"
"runtime"
"time"
"golang.org/x/sync/semaphore"
)
func main() {
ctx := context.TODO()
var (
maxWorkers = runtime.GOMAXPROCS(0)
sem = semaphore.NewWeighted(int64(maxWorkers))
out = make([]int, 8)
)
fmt.Println(maxWorkers)
for i := range out {
//fmt.Println(sem.TryAcquire(1))
if err := sem.Acquire(ctx, 1); err != nil {
log.Printf("Failed to acquire semaphore: %v", err)
break
}
go func(i int) {
fmt.Printf("goroutine %d \n",i)
defer sem.Release(1)
time.Sleep(1e9)
}(i)
}
if err := sem.Acquire(ctx, int64(maxWorkers)); err != nil { //这边会等到size为初始值再返回,这总方式可以实现类似`sycn.WaitGroup`的功能
log.Printf("Failed to acquire semaphore: %v", err)
}
}
$ go run main.go
4
goroutine 3
goroutine 0
goroutine 1
goroutine 2
goroutine 4 #时间间隔1s后打印
goroutine 5
goroutine 6
goroutine 7
Weighted的Release方法会按照FIFO(队列)的顺序唤醒阻塞goroutine。在实际开发中控制并最大并发数的同时还需要防止超长时间的goroutine,所以sem.Acquire带了context参数。
总结
本小节介绍了信号量的运行方式,以及介绍了go semaphore(golang.org/x/sync/semaphore)的使用。
singleflight
什么是singleflight
singleflight是go拓展同步库中实现的一种针对重复的函数调用抑制机制,也就是说一组相同的操作(函数),只有一个函数能被执行,执行后的结果返回给其他同组的函数。singleflight应该算是一种并发模型,非常适合当redis某个key缓存失效时,这个时候一堆请求去数据库来取数据然后更新redis缓存,如果我们使用singlefilght并发模型的话,那就是redis key失效的时候,一堆去数据库的请求只有一个能成功,它将更新该redis key的value值,同时把value值给其他相同请求。
singlefilght中的Group结构体
type Group struct {
mu sync.Mutex // 互斥锁保护 m
m map[string]*call // 存形同key的 函数
}
singleflight有三个对外api
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
func (g *Group) Forget(key string)
Group.Do和Group.DoChan功能类似,Do是同步返回,DoChan返回一个chan实现异步返回。
Group.Forget方法可以通知 singleflight 在map删除某个key,接下来对该key的调用就会直接执行方法而不是等待前面的函数返回。
使用singleflight
package main
import (
"fmt"
"github.com/go-redis/redis"
"golang.org/x/sync/singleflight"
"sync"
"sync/atomic"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379"})
var g singleflight.Group
var callTimes int32 =0
fakeGetData := func() int32 {//模拟去数据库取数据,记录被调用次数
callTimes = atomic.AddInt32(&callTimes,1)
return callTimes
}
wg := sync.WaitGroup{}
for i:=0;i<10;i++ { //模拟10并发
wg.Add(1)
go func() {
defer wg.Done()
ret,err,_:= g.Do("wida", func() (i interface{}, e error) {
num := fakeGetData()
client.Set("wida",num,0)
return num,nil
})
fmt.Println(ret,err)
}()
}
wg.Wait()
fmt.Printf("callTimes %d \n",callTimes)
ret,_:=client.Get("wida").Int()
fmt.Printf("redis value %d \n",ret)
}
运行结果
$ go run main.go
1 <nil>
1 <nil>
1 <nil>
1 <nil>
1 <nil>
1 <nil>
1 <nil>
1 <nil>
1 <nil>
1 <nil>
callTimes 1
redis value 1
我们看到10个并发请求,fakeGetData只被调用了一次,reids的值也被设置为1,10个请求拿到了相同的结果。
如果要使用DoChan的方式只需要稍微修改下
go func() {
defer wg.Done()
retChan:= g.DoChan("wida", func() (i interface{}, e error) {
num := fakeGetData()
client.Set("wida",num,0)
return num,nil
})
ret := <- retChan
fmt.Println(ret)
}()
总结
本小节介绍了go拓展同步库中singleflight(golang.org/x/sync/singleflight),以及介绍了singleflight使用方式和适合的场景。
errgroup
什么是errrgroup
在开发并发程序时,错误的收集和传播往往比较繁琐,有时候当一个错误发声时,我们需要停止所有相关任务,有时候却不是。sync.ErrGroup刚好可以解决我们上述的痛点,它提供错误传播,以及利用context的方式来决定是否要停止相关任务。
errrgroup.Group结构体
type Group struct {
cancel func()
wg sync.WaitGroup
errOnce sync.Once
err error
}
``
三个对外api
```go
unc WithContext(ctx context.Context) (*Group, context.Context)
func (g *Group) Go(f func() error)
func (g *Group) Wait() error
使用errrgroup
只返回错误
package main
import (
"fmt"
"golang.org/x/sync/errgroup"
"net/http"
)
func main() {
var g errgroup.Group
var urls = []string{
"http://www.golang.org/",
"http://www.111111111111111111111111.com/", //这个地址不存在
"http://www.google.com/",
"http://www.somestupidname.com/",
}
for _, url := range urls {
url := url
g.Go(func() error {
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
return err
})
}
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
}else {
fmt.Println(err)
}
}
$ go run main.go
www.111111111111111111111111.com:80: unknown error host unreachable
使用 errgroup.WithContext
package main
import (
"context"
"fmt"
"golang.org/x/sync/errgroup"
"net/http"
"time"
)
func main() {
ctx ,_:=context.WithTimeout(context.Background(),3*time.Second)
var g ,_= errgroup.WithContext(ctx)
var urls = []string{
"http://www.golang.org/",
"http://www.111111111111111111111111.com/",
"http://www.google.com/",
"http://www.somestupidname.com/",
}
for _, url := range urls {
url := url
g.Go(func() error {
ch := make(chan error)
go func() {
time.Sleep(4e9)
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
ch <- err
}()
select {
case err:= <-ch :
return err
case <-ctx.Done():
return ctx.Err()
}
})
}
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
}else {
fmt.Println(err)
}
}
$ go run main.go
context deadline exceeded
go web服务
在绪论中我们简单使用go写了个一个web服务,本文将展开介绍go如何写web服务。我们再看看之前的代码。
package main
import (
"io"
"net/http"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "hello, world!\n")
}
func main() {
http.HandleFunc("/", helloHandler)
http.ListenAndServe(":8888", nil)
}
看起来代码没几行,结构也很清晰, helloHandler的函数,它有两个参数http.ResponseWriter和*http.Request。
http.ResponseWriter实际上是一个interface
type ResponseWriter interface {
Header() Header //返回Header map (type Header map[string][]string),用于设置和获取相关的http header信息
Write([]byte) (int, error) //返回给client body的内容
WriteHeader(statusCode int) //返回给client 的http code码
}
http.Request包含这次http请求的request信息 入http method,url,body等。
http.HandleFunc("/", helloHandler)的作用是注册了 path为/处理函数为 helloHandler的路由(这边使用了默认的http路由DefaultServeMux,感兴趣的同学可以阅读下源码)。
http.ListenAndServe 有两个参数第一个参数是本地地址(ip+port),第二个参数为nil就是使用默认的路由器 DefaultServeMux。它的作用是创建tcp服务,监听(ip+port),并且创建一个goroutine 请处理每一个http请求。
接下来我们通过自己实现http路由来加深下go web服务运行方式的了解。
自己实现http路由
package main
import (
"net/http"
)
type MyServer struct {
router map[string]http.HandlerFunc
}
func (s *MyServer)ServeHTTP(rw http.ResponseWriter, r *http.Request) {
if fn,found := s.router[r.URL.Path] ;found {
fn(rw,r)
return
}
rw.WriteHeader(404)
rw.Write([]byte("page not found"))
}
func (s *MyServer)Add(path string,fn http.HandlerFunc) {
s.router[path] = fn
}
func NewServer() *MyServer {
return &MyServer{
router: make(map[string]http.HandlerFunc),
}
}
func main() {
s := NewServer()
s.Add("/", func(writer http.ResponseWriter, request *http.Request) {
writer.WriteHeader(200)
writer.Write([]byte("hello world"))
})
http.ListenAndServe(":8888", s)
}
运行一下
$ go run main.go
$ curl http://localhost:8888
hello world
我们写了一堆关于结构体 MyServer 的代码,真正把 MyServer 和http服务绑定的只有 http.ListenAndServe(":8888", s) 这一行代码。
说明http.ListenAndServe才是我们了解go web服务的关键。
我们看下http.ListenAndServe的函数定义
func ListenAndServe(addr string, handler Handler)
- 第一个参数我们上文介绍过,
- 第二个参数是一个interface
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
它定义了`ServeHTTP(ResponseWriter, *Request)`的方法。我们的`MyServer`刚好实现了这个方法
func (s *MyServer)ServeHTTP(rw http.ResponseWriter, r *http.Request) {
if fn,found := s.router[r.URL.Path] ;found { //从 map查找对应的 paht=》http.HandlerFunc 映射
fn(rw,r) //真正处理请求,返回消息给client的地方
return
}
rw.WriteHeader(404) //给client发 404
rw.Write([]byte("page not found"))
}
到此我们知道MyServer的 ServeHTTP方法是连接go http server底层和我们写的代码的一个桥梁。我们所需要的每次http请求信息都在http.Request中,然后可以通过 http.ResponseWriter给客户端回写消息。
我们甚至不用关心底层做了什么,我们只需要专注于处理client的每个http请求。
接下来我们再改进下代码,定义我们自己的HandlerFunc和Context,HandlerFunc能让我们少写点代码,Context的封装则可以定制写我们框架专属的特性,例如SayHello方法,代码如下:
package main
import (
"net/http"
)
type HandlerFunc func(*Context)
type MyServer struct {
router map[string]map[string]HandlerFunc
}
type Context struct {
Rw http.ResponseWriter
R *http.Request
}
func (ctx *Context)SayHello() {
ctx.Rw.WriteHeader(200)
ctx.Rw.Write([]byte("hello world"))
}
func (s *MyServer)ServeHTTP(rw http.ResponseWriter, r *http.Request) {
if _,found := s.router[r.Method] ;found {
if fn,found :=s.router[r.Method][r.URL.Path];found {
fn(&Context{Rw:rw,R:r})
return
}
}
rw.WriteHeader(404)
rw.Write([]byte("page not found"))
}
func (s *MyServer)Get(path string,fn HandlerFunc) {
if s.router["GET"] == nil {
s.router["GET"] = make(map[string]HandlerFunc)
}
s.router["GET"][path] = fn
}
func (s *MyServer)Post(path string,fn HandlerFunc) {
if s.router["POST"] == nil {
s.router["POST"] = make(map[string]HandlerFunc)
}
s.router["POST"][path] = fn
}
func NewServer() *MyServer {
return &MyServer{
router: make(map[string]map[string]HandlerFunc),
}
}
func main() {
s := NewServer()
s.Get("/get", func(ctx *Context) {
ctx.SayHello()
})
s.Post("/post", func(ctx *Context) {
ctx.SayHello()
})
http.ListenAndServe(":8888", s)
}
运行一下
$ go run main.go
$ curl http://localhost:8888/get
hello world
$ curl -d "" http://localhost:8888/post
hello world
如果有同学了解过go web框架的话,相信已经感觉到上面的代码和常见框架运用代码已经很像了。
是的,其实go比较流行的web框架比如gin,beego都是利用类似的原理写的,只是他们对Context的封装更加丰富,路由使用了树状结构,还有更多的middleware。
那么接下来我们看下httprouter 和 middleware
http路由(httprouter)
目前大多数流行框架的路由都采用压缩前缀树(compact prefix tree 或者Radix tree),通常每个method都是一颗前缀树。这个部分我们不展开讲,很多主流框架采用方式都比较类似,可以参考httprouter项目,做下深入研究。其实对于一些简单场景(例如没有 path 参数,接口很少的场景)根本不需要用树状结构,直接用map可以实现,而且效率更高。
中间件(middleware)
先看一段代码
package main
import (
"log"
"net/http"
"time"
)
type HandlerFunc func(*Context)
type MyServer struct {
router map[string]map[string]HandlerFunc
}
type Context struct {
Rw http.ResponseWriter
R *http.Request
}
func timeMiddleware(next HandlerFunc) HandlerFunc {
return HandlerFunc(func(ctx *Context) {
start := time.Now()
next(ctx)
elapsed := time.Since(start)
log.Println("time elapsed",elapsed)
})
}
func (ctx *Context)SayHello() {
ctx.Rw.WriteHeader(200)
ctx.Rw.Write([]byte("hello world"))
}
func (s *MyServer)ServeHTTP(rw http.ResponseWriter, r *http.Request) {
if _,found := s.router[r.Method] ;found {
if fn,found :=s.router[r.Method][r.URL.Path];found {
fn(&Context{Rw:rw,R:r})
return
}
}
rw.WriteHeader(404)
rw.Write([]byte("page not found"))
}
func (s *MyServer)Get(path string,fn HandlerFunc) {
if s.router["GET"] == nil {
s.router["GET"] = make(map[string]HandlerFunc)
}
s.router["GET"][path] = fn
}
func NewServer() *MyServer {
return &MyServer{
router: make(map[string]map[string]HandlerFunc),
}
}
func main() {
s := NewServer()
s.Get("/get", timeMiddleware(func(ctx *Context) {
ctx.SayHello()
}))
http.ListenAndServe(":8888", s)
}
$ go run main.go
2019/10/18 10:46:51 time elapsed 2.257µs #调用后会出现
$ curl -curl http://localhost:8888/get
hello world
上面的代码 我们定义了timeMiddleware函数,
func timeMiddleware(next HandlerFunc) HandlerFunc {
return HandlerFunc(func(ctx *Context) {
start := time.Now()
next(ctx)
elapsed := time.Since(start)
log.Println("time elapsed",elapsed)
})
}
用来包裹一个我们的 /get handler 函数。
s.Get("/get", timeMiddleware(func(ctx *Context) {
ctx.SayHello()
}))
```
`timeMiddleware`函数的作用是计算`handlerFunc`的耗时, 类似`timeMiddleware`这种函数我们称作中间件。
从上面的代码可以看出,中间件可以不止一层,我们稍微改下代码,使用两层timeMiddleware。
```golang
s.Get("/get", timeMiddleware(timeMiddleware(func(ctx *Context) {
ctx.SayHello()
})))
运行一下
$ go run main.go
2019/10/18 11:14:52 time elapsed 2.037µs #调用后会出现
2019/10/18 11:14:52 time elapsed 70.15µs
$ curl -curl http://localhost:8888/get
hello world
到这边我们大概了解了中间件的工作原理。我们再对代码做下封装,我们定义了type MiddleWare func(HandlerFunc)HandlerFunc,同时使用MyServer.Use函数添加中间件,修改了MyServer.Get
package main
import (
"log"
"net/http"
"time"
)
type HandlerFunc func(*Context)
type MiddleWare func(HandlerFunc)HandlerFunc
type MyServer struct {
router map[string]map[string]HandlerFunc
chain []MiddleWare
}
type Context struct {
Rw http.ResponseWriter
R *http.Request
}
func timeMiddleware(next HandlerFunc) HandlerFunc {
return HandlerFunc(func(ctx *Context) {
start := time.Now()
next(ctx)
elapsed := time.Since(start)
log.Println("time elapsed",elapsed)
})
}
func (ctx *Context)SayHello() {
ctx.Rw.WriteHeader(200)
ctx.Rw.Write([]byte("hello world"))
}
func (s *MyServer)ServeHTTP(rw http.ResponseWriter, r *http.Request) {
if _,found := s.router[r.Method] ;found {
if fn,found :=s.router[r.Method][r.URL.Path];found {
fn(&Context{Rw:rw,R:r})
return
}
}
rw.WriteHeader(404)
rw.Write([]byte("page not found"))
}
func (s *MyServer)Use(middleware ...MiddleWare) {
for _,m:= range middleware {
s.chain = append(s.chain,m)
}
}
func (s *MyServer)Get(path string,fn HandlerFunc) {
if s.router["GET"] == nil {
s.router["GET"] = make(map[string]HandlerFunc)
}
handler := fn
for i := len(s.chain) - 1; i >= 0; i-- {
handler = s.chain[i](handler)
}
s.router["GET"][path] = handler
}
func NewServer() *MyServer {
return &MyServer{
router: make(map[string]map[string]HandlerFunc),
}
}
func main() {
s := NewServer()
s.Use(timeMiddleware,timeMiddleware)
s.Get("/get", func(ctx *Context) {
ctx.SayHello()
})
http.ListenAndServe(":8888", s)
}
再次运行一下
$ go run main.go
2019/10/18 11:31:32 time elapsed 1.162µs #调用后会出现
2019/10/18 11:31:32 time elapsed 11.941µs
$ curl -curl http://localhost:8888/get
hello world
ok,代码运行正常。
中间件的思路非常适合做压缩,用户鉴权,access日志,流量控制,安全校验等功能。
注意本文介绍的中间件实现方式和gin的实现方式有点差别,但是核心思路是一样的,个人觉得gin的实现方式有点繁琐,有兴趣的同学可以去研究下gin中间件实现方式。
总结
本文简要的介绍了go web服务的相关编写方式,同时简要介绍了 httprouter 和 middleware 这两个go web框架核心的组件,希望这些篇幅对大家后续web框架有更深入的理解。
参考资料
http参数获取和Go http client
获取http参数
使用 http.Request的 FormValue方法获取post(x-www-form-urlencoded)和get参数。
var addr = ":8999"
func main() {
http.HandleFunc("/", func(write http.ResponseWriter, r* http.Request){
fmt.Printf("method:%s,a:%s,c:%s",r.Method,r.FormValue("a"),r.FormValue("c"))
})
http.ListenAndServe(addr,nil)
}
运行
$ go run main.go
method:GET,a:b,c:d //调用后展示
method:POST,a:b,c:d
$ curl "http://localhost:8999/?a=b&c=d"
$ curl -d "a=b&c=d" http://localhost:8999
获取post multipart/form-data参数
获取form-data参数我们只需要在上面的代码中加入r.ParseForm()方法。
var addr = ":8999"
func main() {
http.HandleFunc("/", func(write http.ResponseWriter, r* http.Request){
r.ParseForm() //新加的
fmt.Printf("method:%s,a:%s,c:%s",r.Method,r.FormValue("a"),r.FormValue("c"))
})
http.ListenAndServe(addr,nil)
}
运行
$ go run main.go
method:POST,a:b,c:d //调用后展示
$ curl "http://localhost:8999" -F a=b -F c=d
获取上传文件
获取上传文件有专门 http.Request的 FormFile方法获取文件
var addr = ":8999"
func main() {
http.HandleFunc("/", func(write http.ResponseWriter, r* http.Request){
file, header, err :=r.FormFile("uploadfile") //对应参数名
if err != nil {
panic(err)
}
defer file.Close()
nameParts := strings.Split(header.Filename, ".")
ext := nameParts[1]
savedPath := nameParts[0] + "_up."+ext
f, err := os.OpenFile(savedPath, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
panic(err)
}
defer f.Close()
_, err = io.Copy(f, file)
if err != nil {
panic(err)
}
fmt.Printf("method:%s,a:%s,c:%s ,file:%s",r.Method,r.FormValue("a"),r.FormValue("c"),header.Filename)
})
}
$ echo "test" > 1.txt
$ go run main.go
method:POST,a:b,c:d,file:1.txt //调用后展示
$ curl "http://localhost:8999" -F a=b -F c=d -F uploadfile=@1.txt
http client
http client是一个十分高频使用的组件,特别是近几年基于http协议restful api的盛行,很多语言或者第三库都在设计和打造好用,而且稳定的http client,比如java的apache httpclient,android的okhttp,c语言的libcurl等。
go 的http client
go标准库实现一个叫http.DefaultClient的http client。 本文主要介绍我们比较常用场景下如何使用http.DefaultClient。
我们先实现一个go的web服务。
var addr = ":8999"
func main() {
http.HandleFunc("/", func(write http.ResponseWriter, r* http.Request){
r.ParseForm()
fmt.Printf("method:%s,a:%s,c:%s",r.Method,r.FormValue("a"),r.FormValue("c"))
})
http.HandleFunc("/json", func(write http.ResponseWriter, r* http.Request){
b,_:= ioutil.ReadAll(r.Body)
fmt.Println(string(b))
})
http.HandleFunc("/file", func(write http.ResponseWriter, r* http.Request){
file, header, err :=r.FormFile("uploadfile")
if err != nil {
panic(err)
}
defer file.Close()
nameParts := strings.Split(header.Filename, ".")
ext := nameParts[1]
savedPath := nameParts[0] + "_up."+ext
f, err := os.OpenFile(savedPath, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
panic(err)
}
defer f.Close()
_, err = io.Copy(f, file)
if err != nil {
panic(err)
}
})
http.ListenAndServe(addr,nil)
}
Get
go的http client get请求相对简单,我们看下代码
func get() {
resp,err := http.Get("http://localhost"+addr+"/?a=b&c=d")
if err !=nil {
log.Fatal(err)
}
defer resp.Body.Close() //这边需要把body close
body,err := ioutil.ReadAll(resp.Body)
if err !=nil {
return
}
fmt.Println(string(body))
}
需要注意的是 http.DefaultClient 实现了连接池,resp.Body.Close() 代表这次请求已经处理完了,连接会重新放到池子里。
Post
x-www-form-urlencoded
func post() {
resp,err := http.Post("http://localhost"+addr, "application/x-www-form-urlencoded",
strings.NewReader("a=b&c=d"))
if err !=nil {
return
}
defer resp.Body.Close()
body,err := ioutil.ReadAll(resp.Body)
if err !=nil {
return
}
fmt.Println(string(body))
}
form-data
func postform() {
resp,err := http.PostForm("http://localhost"+addr, url.Values{"a": {"b"}, "c": {"d"}})
if err !=nil {
return
}
defer resp.Body.Close()
body,err := ioutil.ReadAll(resp.Body)
if err !=nil {
return
}
fmt.Println(string(body))
}
body
func postjson() {
jsonStr :=[]byte(`{{"a":"b"},{"c":"d"}}`)
req, err := http.NewRequest("POST", "http://localhost"+addr+"/json", bytes.NewBuffer(jsonStr))
req.Header.Set("Content-Type", "application/json")
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return
}
defer resp.Body.Close()
body,err := ioutil.ReadAll(resp.Body)
if err !=nil {
return
}
fmt.Println(string(body))
}
文件上传
func fileupload() {
buf := new(bytes.Buffer)
writer := multipart.NewWriter(buf)
formFile, err := writer.CreateFormFile("uploadfile", "test.txt") //第一个字段名,第二个是参数名
if err != nil {
log.Fatalf("Create form file failed: %s\n", err)
}
srcFile, err := os.Open("test.txt")
if err != nil {
log.Fatalf("%Open source file failed: s\n", err)
}
defer srcFile.Close()
_, err = io.Copy(formFile, srcFile)
if err != nil {
log.Fatalf("Write to form file falied: %s\n", err)
}
writer.Close()
resp,err := http.Post("http://localhost"+addr+"/file", writer.FormDataContentType(), buf)
if err !=nil {
return
}
defer resp.Body.Close()
body,err := ioutil.ReadAll(resp.Body)
if err !=nil {
return
}
fmt.Println(string(body))
}
go第三方http client
标准库的http client功能基本上能满足我们的日常开发需求,当然还有第三方package 可能封装得可能更优雅。下面提供三个比较高人气的go的第三方http client实现。
http请求参数校验
在web服务开发的过程中,我们经常需要对用户传递的参数进行验证。验证的代码很容易写得冗长,而且比较丑陋。本文我们介绍一个第三放库validator专门解决这个问题。
验证单一变量
import (
"fmt"
"gopkg.in/go-playground/validator.v9"
)
func validateVariable() {
myEmail := "someone.gmail.com"
errs := validate.Var(myEmail, "required,email")
if errs != nil {
fmt.Println(errs)
return
}
//这边验证通过 写逻辑代码
}
var validate *validator.Validate
func main() {
validate = validator.New()
validateVariable()
}
运行一下
$ go run main.go
Key: '' Error:Field validation for '' failed on the 'email' tag
验证结构体
package main
import (
"fmt"
"gopkg.in/go-playground/validator.v9"
)
type User struct {
Name string `validate:"required"`
Age uint8 `validate:"gte=0,lte=150"` //大于等于0 小于等于150
Email string `validate:"required,email"`
}
var validate *validator.Validate
func main() {
validate = validator.New()
validateStruct()
}
func validateStruct() {
user := &User{
Name: "wida",
Age: 165,
Email: "someone.gmail.com",
}
err := validate.Struct(user)
fmt.Println(err)
if err != nil {
if _, ok := err.(*validator.InvalidValidationError); ok {
fmt.Println(err)
return
}
for _, err := range err.(validator.ValidationErrors) { //变量所有参数错误
fmt.Println(err.Namespace())
fmt.Println(err.Field())
fmt.Println(err.StructNamespace())
fmt.Println(err.StructField())
fmt.Println(err.Tag())
fmt.Println(err.ActualTag())
fmt.Println(err.Kind())
fmt.Println(err.Type())
fmt.Println(err.Value())
fmt.Println(err.Param())
fmt.Println()
}
return
}
}
运行一下
$ go run main.go
Key: 'User.Age' Error:Field validation for 'Age' failed on the 'lte' tag
Key: 'User.Email' Error:Field validation for 'Email' failed on the 'email' tag
User.Age
Age
User.Age
Age
lte
lte
uint8
uint8
165
150
User.Email
Email
User.Email
Email
email
email
string
string
someone.gmail.com
运行的结果显示,age和email验证通不过。
web服务框架
一般情况下,如果只是很少的api,或者功能需求非常简单,我们通常不建议使用web框架。但是如果api众多,功能复杂,那么选用合适的一个web框架,对项目的帮助是非常大的。
golang的生态中有好多个非常流行的web服务框架:
这些框架的核心功能都大同小异,会有自己定义的router,自己定义的各种web组件或者中间件。
一般我们选定一款web框架后会研究它的实现,方便自己在实现项目运用中排查问题。
go使用mysql
go的mysql驱动相对比较统一,基本都用go-sql-driver。这个驱动也实现了数据库连接池。但是没有实现orm。
目前go的mysql orm实现则比较多 gorm、xorm、beego-orm。orm使用起来比较灵活,但是在大型项目中,由于orm屏蔽底层细节的原因通常不建议使用。本文主要介绍go-sql-driver不介绍rom。
创建一个测试table
CREATE TABLE `tb_test` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`uid` int(11) NOT NULL,
`img` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `uid` (`uid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
连接mysql
导入 github.com/go-sql-driver/mysql包
"database/sql"
_ "github.com/go-sql-driver/mysql"
注意这边使用 _用来执行这个包的init()函数,来注册mysql驱动,sql.Register("mysql", &MySQLDriver{})
连接mysql,注意连接池的主要三个配置ConnMaxLifetime,MaxOpenConns,MaxIdleConns
var db *sql.DB
func init() {
var err error
db, err = sql.Open("mysql", "user:password@tcp(localhost:3306)/test")
if err != nil {
panic(err.Error())
}
db.SetConnMaxLifetime(10*time.Minute)
db.SetMaxIdleConns(2)
db.SetMaxOpenConns(10)
}
注意由于连接池的存在,一般只有确认不再使用msyql了才会调用db.Close()。
curd操作
添加
func add() {
stmtIns, err := db.Prepare("INSERT INTO tb_test VALUES(?,?,?)") // ? = placeholder
if err != nil {
panic(err.Error())
}
defer stmtIns.Close()
for i := 0; i < 25; i++ {
_, err = stmtIns.Exec(i+1, i * i,fmt.Sprintf("http://abc.com/%d.jpg",i))
if err != nil {
panic(err.Error())
}
}
}
获取
func query() {
//findone
stmtOut, err := db.Prepare("SELECT uid FROM tb_test WHERE id = ?")
if err != nil {
panic(err.Error())
}
defer stmtOut.Close()
var squareNum int
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second) //查询超时时间
defer cancel()
err = stmtOut.QueryRowContext(ctx,13).Scan(&squareNum)
if err != nil {
panic(err.Error())
}
fmt.Printf("The square number of 13 is: %d \n", squareNum)
err = stmtOut.QueryRow(5).Scan(&squareNum) //不带超时
if err != nil {
panic(err.Error())
}
fmt.Printf("The square number of 5 is: %d \n", squareNum)
//findmany
stmtOut, err = db.Prepare("SELECT * FROM tb_test")
if err != nil {
panic(err.Error())
}
defer stmtOut.Close()
type Entry struct{
Id int32
Uid int
Img string}
var entrys []Entry
ctx, cancel = context.WithTimeout(context.Background(), 5*time.Second) //查询超时时间,对耗时的查询使用超时处理对程序的健壮性有很大帮助
defer cancel()
rows ,err := stmtOut.QueryContext(ctx)
if err!=nil {
println(err)
}
defer rows.Close()
for rows.Next() {
entry := Entry{}
rows.Scan(&entry.Id,&entry.Uid,&entry.Img) //这边需要和数据库的字段顺序保持一致,另外一种方法是select中指定字段,这边scan的顺序和指定的字段顺序一致
entrys = append(entrys,entry)
}
fmt.Println(entrys)
}
更新
func update() {
stm,_ := db.Prepare("update tb_test set uid=? where id=? ")
ret ,err := stm.Exec(999,1)
if err !=nil {
panic(err)
}
fmt.Println(ret.RowsAffected()) //影响条数
stm.Close()
}
删除
func delete() {
stm,_ := db.Prepare("DELETE from tb_test where id=? ")
ret ,err := stm.Exec(25)
if err !=nil {
panic(err)
}
fmt.Println(ret.RowsAffected()) //影响条数
stm.Close()
}
事务
func transaction() {
tx ,_:=db.Begin()
stmt,err := tx.Prepare("SELECT uid FROM tb_test WHERE id = ?")
if err !=nil {
tx.Rollback()
return
}
var uid int32
stmt.QueryRow(1).Scan(&uid)
ret,err := tx.Exec("UPDATE tb_test set img='http://abc.com/3.jpg' where id=?",1)
if err !=nil {
tx.Rollback()
return
}
fmt.Println(ret.RowsAffected())
tx.Commit()
}
参考资料
go使用mongodb
mongodb的go语言驱动比较流行是mongo-go-driver和mgo,前者是mongodb官方出的go驱动,mgo之前一直是个人在维护的,后来作者由于个原因已经放弃维护,后面出现mgo的分支还在继续维护不过更新频率还是比较低。本文主要介绍mongo-go-driver这个mongodb官方维护的版本,目前mongo-go-driver的版本已经是1.1.2已经可以用在生产环境。
mongodb client
目前大多数golang数据库驱动client 都会用连接池的方式来运行。 mongo-go-driver也不例外。
连接MongoDB代码如下:
client, err := mongo.Connect(context.Background(), options.Client().ApplyURI("mongodb://localhost:27017"))
if err != nil {
log.Fatal(err)
}
err = client.Ping(context.TODO(), nil)
if err != nil {
log.Fatal(err)
}
fmt.Println("Connected to MongoDB!")
运行下main.go程序
# go run main.go
Connected to MongoDB!
这边需要注意下,采用连接池后一般很少自己close client而是继续放在链接池中举行供其他请求使用。 如果你确定已经不需要使用Client,可以使用如下代码收到关闭。
err = client.Disconnect(nil)
if err != nil {
log.Fatal(err)
}
fmt.Println("Connection to MongoDB closed.")
获取集合handle
collection = client.Database("testing").Collection("students")
为collection创建索引
indexView := collection.Indexes()
ret,err :=indexView.CreateOne(context.Background(), mongo.IndexModel{
Keys: bsonx.Doc{{"name", bsonx.Int32(-1)}},
Options: options.Index().SetName("testname").SetUnique(true), //这边设置了唯一限定,不设定默认不是唯一的
})
fmt.Println(ret,err)
CURD操作
添加
func add() {
wida := Student{"wida", 32, "8001"}
amy := Student{"amy", 25, "8002"}
sunny := Student{"sunny", 35, "8003"}
ret, err := collection.InsertOne(nil, wida)
if err != nil {
log.Fatal(err)
}
fmt.Println("写入一个文档", ret.InsertedID)
student := []interface{}{amy, sunny}
ret2, err := collection.InsertMany(nil, student)
if err != nil {
log.Fatal(err)
}
fmt.Println("写入多个文档 ", ret2.InsertedIDs)
}
查询
func find() {
var result Student
err := collection.FindOne(nil, bson.D{{"name", "amy"}, {"age", 25}}).Decode(&result)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%+v\n", result)
findOptions := options.Find()
findOptions.SetLimit(3)
var results []*Student
cur, err := collection.Find(context.TODO(), bson.D{{}}, findOptions)
if err != nil {
log.Fatal(err)
}
for cur.Next(context.TODO()) {
var elem Student
err := cur.Decode(&elem)
if err != nil {
log.Fatal(err)
}
results = append(results, &elem)
}
if err := cur.Err(); err != nil {
log.Fatal(err)
}
cur.Close(nil)
for _,r := range results {
fmt.Printf("%+v\n", r)
}
}
更新
filter := bson.D{{"no", "8001"}}
update := bson.D{
{"$set", bson.D{
{"age", 33},
{"name", "wida2"},
}},
}
ret, err := collection.UpdateOne(nil, filter, update)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Matched %v documents and updated %v documents.\n", ret.MatchedCount, ret.ModifiedCount)
}
删除
func del() {
deleteResult, err := collection.DeleteMany(context.TODO(), bson.D{{}}) // 这边删除全部文档
if err != nil {
log.Fatal(err)
}
fmt.Printf("Deleted %v documents\n", deleteResult.DeletedCount)
}
参考文档
go使用redis
go语言比较常用的两个redis包redis和goredis。前者封装的比较优雅,功能也比较全。后者像是个工具集合,redis command需要重新封装下才好用在项目中,流行度也很广。本文主要介绍前者redis的使用。
redis连接池
创建redis client的代码如下,
client = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
这段代码实际上初始化了一个redis连接池而不是单一的redis链接。NewClient的源码如下
func NewClient(opt *Options) *Client {
opt.init()
c := Client{
baseClient: baseClient{
opt: opt,
connPool: newConnPool(opt),
},
}
c.baseClient.init()
c.init()
return &c
}
我们了解下redis.Options结构体中比较关键的几个配置
type Options struct {
Network string //tcp 或者unix
Addr string // redis 地址 host:port.
Dialer func() (net.Conn, error) //创建新的redis连接
OnConnect func(*Conn) error //链接创建后的钩子函数
Password string //redis password 默认为空
DB int //redis db 默认为0
PoolSize int //链接池最大活跃数 默认runtime.NumCPU * 10
MinIdleConns int //最新空闲链接数 默认是0,空闲连接的用处是加快第一次请求(少了握手过程)
IdleTimeout time.Duration //最大空闲时间,需要配置成比redis服务端配置的时间段,默认是5分钟
}
再看下 opt.init() 做了什么事情
func (opt *Options) init() {
if opt.Network == "" {
opt.Network = "tcp"
}
if opt.Addr == "" {
opt.Addr = "localhost:6379"
}
if opt.Dialer == nil {
opt.Dialer = func() (net.Conn, error) {
netDialer := &net.Dialer{
Timeout: opt.DialTimeout,
KeepAlive: 5 * time.Minute,
}
if opt.TLSConfig == nil {
return netDialer.Dial(opt.Network, opt.Addr)
} else {
return tls.DialWithDialer(netDialer, opt.Network, opt.Addr, opt.TLSConfig)
}
}
}
if opt.PoolSize == 0 {
opt.PoolSize = 10 * runtime.NumCPU()
}
...
if opt.IdleTimeout == 0 {
opt.IdleTimeout = 5 * time.Minute
}
...
}
从上面的代码可以看出来opt.init()实际上初始化了默认配置。一般来说这样子的默认配置能满足大部分项目的需求。
qick start
var client *redis.Client
func init() {
client = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
}
func ping() {
pong, err := client.Ping().Result()
fmt.Println(pong, err)
}
func main() {
ping()
}
# go run main.go
PONG <nil>
kv操作
func keyv() {
err := client.Set("key", "value", 0).Err()
if err != nil {
panic(err)
}
val, err := client.Get("key").Result()
if err != nil {
panic(err)
}
fmt.Println("key", val)
val2, err := client.Get("key2").Result()
if err == redis.Nil {
fmt.Println("key2 does not exist")
} else if err != nil {
panic(err)
} else {
fmt.Println("key2", val2)
}
}
list操作
func list() {
client.LPush("wida","ddddd")
ret,_ := client.LPop("wida").Result()
fmt.Println(ret)
_,err := client.LPop("wida").Result()
if err == redis.Nil {
fmt.Println("empty list")
}
}
set操作
func set() {
client.SAdd("set","wida")
client.SAdd("set","wida1")
client.SAdd("set","wida2")
ret,_:= client.SMembers("set").Result()
fmt.Println(ret)
}
sortset 操作
func sortset() {
client.ZAdd("page_rank", redis.Z{10 ,"google.com"})
client.ZAdd("page_rank", redis.Z{9 ,"baidu.com"},redis.Z{8 ,"bing.com"})
ret,_:=client.ZRangeWithScores("page_rank",0,-1).Result()
fmt.Println(ret)
}
hashset 操作
func hash() {
client.HSet("hset","wida",1)
ret ,_:=client.HGet("hset","wida").Result()
fmt.Println(ret)
ret ,err:=client.HGet("hset","wida3").Result()
if err == redis.Nil {
fmt.Println("key not found")
}
client.HSet("hset","wida2",2)
r ,_:=client.HGetAll("hset").Result()
fmt.Println(r)
}
pipeline
func pipeline() {
pipe := client.Pipeline()
pipe.HSet("hset2","wida",1)
pipe.HSet("hset2","wida2",2)
ret := pipe.HGetAll("hset2")
fmt.Println(pipe.Exec())
fmt.Println(ret.Result())
}
go使用es
elasticsearch有官方的golang驱动go-elasticsearch这个项目比较新,
另外一个常用的是 elastic,这两个驱动文档和demo都比较少。es的查询语法也相对复杂,很多查询方式去翻翻它们的test文件才能发现方式。本小节使用elastic做演示,注意不同elasticsearch版本对于不同的client版本,例如elasticsearch 5.5.3对应的client版本为gopkg.in/olivere/elastic.v5。如果这个对应关系错误,很可能程序会出错,这个在https://github.com/olivere/elastic的readme文档也有介绍。
本小节的demo主要基于 elasticsearch 5.5.3,client为gopkg.in/olivere/elastic.v5。
go链接es
var client *elastic.Client
func init() {
var err error
client, err = elastic.NewClient(elastic.SetURL("http://localhost:9200"))
if err != nil {
log.Fatal(err)
}
}
CURD
测试数据结构体
type Item struct {
Id int64 `json:"id"`
Appid string `json:"appid"`
AppBAutoId string `json:"app_b_auto_id"`
}
添加
func add() {
//add one
item := Item{Id:int64(21),Appid:fmt.Sprintf("app_%d",21),AppBAutoId:fmt.Sprintf("app_%d",21+200)}
put, err := client.Index().
Index("es_test").
Type("test").
Id("1"). //这个id也可以指定,不指定的话 es自动生成一个
BodyJson(item).
Do(context.Background())
if err != nil {
// Handle error
panic(err)
}
fmt.Println(put)
//add many
bulkRequest := client.Bulk()
for i:=0;i<20;i++ {
item := Item{Id:int64(i),Appid:fmt.Sprintf("app_%d",i),AppBAutoId:fmt.Sprintf("app_%d",i+200)}
bulkRequest.Add(elastic.NewBulkIndexRequest().Index("es_test").Type("test").Doc(item))
}
bulkRequest.Do(context.TODO())
}
查找
func find() {
//find one
get1, err := client.Get().
Index("es_test").
Type("test").
Id("1").
Do(context.Background())
if err != nil {
// Handle error
panic(err)
}
if get1.Found {
fmt.Printf("Got document %s in version %d from index %s, type %s\n", get1.Id, get1.Version, get1.Index, get1.Type)
}
var ttyp Item
json.Unmarshal(*get1.Source,&ttyp)
fmt.Println("item",ttyp)
//find many
searchResult, err := client.Search().
Index("es_test"). Sort("id", true).
Type("test").From(0).Size(100).
Do(context.TODO())
if err != nil {
panic(err)
}
if searchResult.Hits.TotalHits >0 {
var ttyp Item
for _, item := range searchResult.Each(reflect.TypeOf(ttyp)) {
t := item.(Item)
fmt.Println("item ",t)
}
}
}
更新
func update() {
fmt.Println(client.Update().Index("es_test").Type("test").Id("1").
Doc(map[string]interface{}{"appid": "app_23"}).Do(context.TODO()))
}
删除
func delete() {
fmt.Println(client.Delete().Index("es_test").Type("test").Id("1").Do(context.TODO()))
}
统计查询
func agg() {
//获取最大的id
searchResult, err := client.Search().
Index("es_test").Type("test").
Aggregation("max_id", elastic.NewMaxAggregation().Field("id")).Size(0).Do(context.TODO())
if err != nil {
panic(err)
}
var a map[string]float32
if searchResult != nil {
if v, found := searchResult.Aggregations["max_id"]; found {
json.Unmarshal([]byte(*v), &a)
fmt.Println(a)
}
}
//统计id相同的文档数
searchResult, err = client.Search().
Index("es_test").Type("test").
Aggregation("count", elastic.NewTermsAggregation().Field("id")).Size(0).Do(context.TODO())
if err != nil {
panic(err)
}
if searchResult != nil {
if v, found := searchResult.Aggregations["count"]; found {
var ar elastic.AggregationBucketKeyItems
err := json.Unmarshal(*v, &ar)
if err != nil {
fmt.Printf("Unmarshal failed: %v\n", err)
return
}
for _, item := range ar.Buckets {
fmt.Printf("id :%v: count :%v\n", item.Key, item.DocCount)
}
}
}
}
参考资料
为什么需要内嵌数据库
go的生态中有好多内嵌的k/v数据库,为什么我们需要内嵌数据库?
- 更高的效率:内嵌数据库因为和程序共享一个程序地址空间减少IPC开销,所以比独立数据库具有更高的性能
- 更简洁的部署方案:因为内嵌了,所以就不需要额外部署单独的数据库,减少程序依赖.
- 做单机存储引擎:一些优秀的内嵌数据库可以作为单机存储引擎,然后通过分布式一致性协议和分片策略可以集群成大型分布式数据库.例如etcd中使用boltDB,dgraph使用的badger.
说道内嵌型kv数据库,不得不提的就rocksdb了.这些年基于rocksdb单机存储引擎之上开发的分布式数据库数不胜数.例如tidb,cockroachdb等等.rocksdb是Facebook基于leveldb加强的kv存储引擎,用c++编写的,go需要通过cgo可以内嵌rocksdb,可以参考gorocksdb。但是go一般不用rocksdb作为内嵌kv数据库,首先rocksdb安装非常繁琐,二cgo的性能一直被诟病,而且容易造成内存泄露。
本小节依次介绍blotdb,goleveldb,badger三款表典型的内嵌数据库.
BoltDB
我们现在说的bolt一般都会说是etcd维护的bolt版本,老的bolt作者已经不再维护。bolt提供轻量级的kv数据库,内部是一个B+树结构体,支持完整的ACID事务。 bolt是基于内存映射(mmap)的数据库,通常情况使用的内存会比较大,bolt适合kv数量不是特别大的场景。
创建数据库
package main
import (
"log"
bolt "go.etcd.io/bbolt"
)
func main() {
// 打开my.db 如果文件不存在则会创建
db, err := bolt.Open("my.db", 0600, nil)
if err != nil {
log.Fatal(err)
}
defer db.Close()
}
事务
bolt支持只读事务和读写事务, 在同一个时间只能有一个读写事务,但是可以有多个只读事务。
只读事务使用 db.View
err := db.View(func(tx *bolt.Tx) error {
...
return nil
})
读写事务使用 db.Update
err := db.Update(func(tx *bolt.Tx) error {
...
return nil
})
Buckets(桶)
Bolt在内部用Buckets来组织相关的kv键值对,在同一个Bucket里头key值是不允许重复的,bolt中一个文件代表一个database,那么bucket就相当于一个table。
操作Bucket
db.Update(func(tx *bolt.Tx) error {
b, err := tx.CreateBucket([]byte("MyBucket")) //创建bucket,通常会使用 CreateBucketIfNotExists
if err != nil {
return fmt.Errorf("create bucket: %s", err)
}
err := b.Put([]byte("answer"), []byte("42")) //写入kv
v := b.Get([]byte("answer")) //获取value
fmt.Printf("%s",v)
return nil
})
key的遍历
在kv数据库中我们需要对key进行精心设计,无论在取值或者遍历的时候都需要快速的定位key的位置。在bolt中key是基于B树有序的。 一般有如下三种场景遍历key,遍历,范围遍历,前缀遍历
遍历桶中所有key
db.View(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte("MyBucket"))
c := b.Cursor()
for k, v := c.First(); k != nil; k, v = c.Next() {
fmt.Printf("key=%s, value=%s\n", k, v)
}
return nil
})
或者使用 ForEach 遍历所有桶下面所有key
db.View(func(tx *bolt.Tx) error {
// Assume bucket exists and has keys
b := tx.Bucket([]byte("MyBucket"))
b.ForEach(func(k, v []byte) error {
fmt.Printf("key=%s, value=%s\n", k, v)
return nil
})
return nil
})
key范围遍历
db.View(func(tx *bolt.Tx) error {
c := tx.Bucket([]byte("Events")).Cursor()
min := []byte("1990-01-01T00:00:00Z")
max := []byte("2000-01-01T00:00:00Z")
for k, v := c.Seek(min); k != nil && bytes.Compare(k, max) <= 0; k, v = c.Next() {
fmt.Printf("%s: %s\n", k, v)
}
return nil
})
key前缀遍历
db.View(func(tx *bolt.Tx) error {
c := tx.Bucket([]byte("MyBucket")).Cursor()
prefix := []byte("1234")
for k, v := c.Seek(prefix); k != nil && bytes.HasPrefix(k, prefix); k, v = c.Next() {
fmt.Printf("key=%s, value=%s\n", k, v)
}
return nil
})
Badger
badger 同样是基于LSM tree,但是不同于levevdb他的key/value在存储的时候是分离的,特别时候value比较大的场景.
badger使用
创建db
package main
import (
"log"
badger "github.com/dgraph-io/badger/v2"
)
func main() {
db, err := badger.Open(badger.DefaultOptions("/tmp/badger"))
if err != nil {
log.Fatal(err)
}
defer db.Close()
}
增删改
//写数据
err := db.Update(func(txn *badger.Txn) error {
err := txn.Set([]byte("answer"), []byte("42"))
return err
})
//读数据
err := db.View(func(txn *badger.Txn) error {
item, err := txn.Get([]byte("answer"))
//handle(err)
var valNot []byte
var valCopy []byte
//因为key-value是分类 bager获取value的方式比较独特
err := item.Value(func(val []byte) error {
fmt.Printf("The answer is: %s\n", val)
// 拷贝val 或者解析val是可以
valCopy = append([]byte{}, val...)
valNot = val //不要这么干
return nil
})
//handle(err)
// 不要这么干,这样会经常导致bug
fmt.Printf("NEVER do this. %s\n", valNot)
// You must copy it to use it outside item.Value(...).
fmt.Printf("The answer is: %s\n", valCopy)
// 或者你也可以这么干
valCopy, err = item.ValueCopy(nil)
//handle(err)
fmt.Printf("The answer is: %s\n", valCopy)
return nil
})
//删除数据
err := db.Update(func(txn *badger.Txn) error {
err := txn.Delete([]byte("answer"))
return err
})
事务
入上面的示例代码,badger的使用有只读事务和可写事务分别用
//只读事务
err := db.View(func(txn *badger.Txn) error {
return nil
})
//可写事务
err := db.Update(func(txn *badger.Txn) error {
return nil
})
一般情况下db.View和db.Update大多情况已经满足大多数场景.但是默写情况下你可能需要自己管理事务的开启和关闭.badger提供了DB.NewTransaction(),Txn.Commit(),Txn.Discard()三个方法来手动管理事务.
// 开启可写事务
txn := db.NewTransaction(true)
//别忘了用txn.Discard()清理事务
defer txn.Discard()
err := txn.Set([]byte("answer"), []byte("42"))
if err != nil {
return err
}
// 提交事务或者出来事务
if err := txn.Commit(); err != nil {
return err
}
还需要注意的是在badger事务大小是受限制的,我们在处理事务的是需要出来事务的error,特别需要关注badger.ErrTxnTooBig,我需要分批处理下,处理方式入下代码。
updates := make(map[string]string)
txn := db.NewTransaction(true)
for k,v := range updates {
if err := txn.Set([]byte(k),[]byte(v)); err == badger.ErrTxnTooBig {
_ = txn.Commit()
txn = db.NewTransaction(true)
_ = txn.Set([]byte(k),[]byte(v))
}
}
_ = txn.Commit()
遍历
只遍历key
err := db.View(func(txn *badger.Txn) error {
opts := badger.DefaultIteratorOptions
opts.PrefetchValues = false
it := txn.NewIterator(opts)
defer it.Close()
for it.Rewind(); it.Valid(); it.Next() {
item := it.Item()
k := item.Key()
fmt.Printf("key=%s\n", k)
}
return nil
})
遍历key-value
err := db.View(func(txn *badger.Txn) error {
opts := badger.DefaultIteratorOptions
opts.PrefetchSize = 10
it := txn.NewIterator(opts)
defer it.Close()
for it.Rewind(); it.Valid(); it.Next() {
item := it.Item()
k := item.Key()
err := item.Value(func(v []byte) error {
fmt.Printf("key=%s, value=%s\n", k, v)
return nil
})
if err != nil {
return err
}
}
return nil
})
前缀遍历
err := db.View(func(txn *badger.Txn) error {
it := txn.NewIterator(badger.DefaultIteratorOptions)
defer it.Close()
prefix := []byte("1234")
for it.Seek(prefix); it.ValidForPrefix(prefix); it.Next() {
item := it.Item()
k := item.Key()
err := item.Value(func(v []byte) error {
fmt.Printf("key=%s, value=%s\n", k, v)
return nil
})
if err != nil {
return err
}
}
return nil
})
value文件清理
由于badger的key和value是分开存储的,key存储在LSM-TREE中,而value则独立于LSM-TREE之外,LSM-TREE的压缩过程,不会涉及value的合并。另外badger的事务基于MVCC的所以value是存在很多个版本的。总的来说手动清理value文件是必须的。
badger提供db.RunValueLogGC来清理value文件。
通常我们需要单独启用一个goroutine来执行。
例子如下:
ticker := time.NewTicker(5 * time.Minute)
defer ticker.Stop()
for range ticker.C {
again:
err := db.RunValueLogGC(0.7)
if err == nil {
goto again
}
}
Leveldb
LevelDB是Google开源的由C++编写的基于LSM-Tree的KV数据库,有超高的随机写,顺序读/写性能,但是随机读的性能很一般,LevelDB一般应用在查询少写多的场景。
LSM-Tree
LSM Tree(Log-Structured Merge-Tree),是为了解决在内存不足,磁盘随机IO太慢下的写入性能问题。在LSM中增删改操作都是新增记录,新的记录会最早被索引到,这样才的操作会造成数据重复,后续的合并操作会消除这样的冗余。LSM通过这样的方式把随机IO变成顺序IO,大大提高写入性能。
了解LSM-Tree细节可以查看LSM树原理探究。
goleveldb使用
创建db
db, err := leveldb.OpenFile("path/to/db", nil)
defer db.Close()
增删改
data, err := db.Get([]byte("key"), nil)
...
err = db.Put([]byte("key"), []byte("value"), nil)
...
err = db.Delete([]byte("key"), nil)
迭代器
遍历所有
iter := db.NewIterator(nil, nil)
for iter.Next() {
key := iter.Key()
value := iter.Value()
...
}
iter.Release()
err = iter.Error()
设置起始点遍历
iter := db.NewIterator(nil, nil)
for ok := iter.Seek(key); ok; ok = iter.Next() {
// Use key/value.
...
}
iter.Release()
err = iter.Error()
范围遍历
iter := db.NewIterator(&util.Range{Start: []byte("foo"), Limit: []byte("xoo")}, nil)
for iter.Next() {
// Use key/value.
...
}
iter.Release()
err = iter.Error()
...
前缀遍历
iter := db.NewIterator(util.BytesPrefix([]byte("foo-")), nil)
for iter.Next() {
// Use key/value.
...
}
iter.Release()
err = iter.Error()
批量操作
batch := new(leveldb.Batch)
batch.Put([]byte("foo"), []byte("value"))
batch.Put([]byte("bar"), []byte("another value"))
batch.Delete([]byte("baz"))
err = db.Write(batch, nil)
使用布隆过滤器
布隆过滤器使用极少空间代价(bitmap)来判断一个值是否在这个集合里,它使用多个hash函数对key计算然后映射到bitmap上的位置,如果这个位置的值为1,则代表这个值可能存在(注意是可能存在),如果这个位置值为0,代表这个key一定不存在这个集合里。如果哈希函数够多,我们判断是否存在的可信度就越高。当然某些情况下判断出来值存在的误判,在实际应用场景中我们无非耗费点资源去实际的kv数据库里头查下看否能拿到value。布隆过滤器能快速的知道key不存这样子可以减少大量的好资源操作。
o := &opt.Options{
Filter: filter.NewBloomFilter(10),
}
db, err := leveldb.OpenFile("path/to/db", o)
...
defer db.Close()
...
Socket(套接字)编程
什么是Socket
Socket 是对 TCP/IP 协议族的一种封装,是应用层与TCP/IP协议族通信的中间软件抽象层。 Socket 还可以认为是一种网络间不同计算机上的进程通信的一种方法,利用三元组(ip地址,协议,端口)就可以唯一标识网络中的进程,网络中的进程通信可以利用这个标志与其它进程进行交互。 Socket 起源于 Unix ,Unix/Linux 基本哲学之一就是“一切皆文件”,都可以用“打开(open) –> 读写(write/read) –> 关闭(close)”模式来进行操作。因此 Socket 也被处理为一种特殊的文件。
Socket常见类型
Datagram sockets
无连接Socket,使用用户数据报协议(UDP)。在Datagram sockets上发送或接收的每个数据包都经过单独寻址和路由。数据报Socket无法保证顺序和可靠性,因此从一台机器或进程发送到另一台机器或进程的多个数据包可能以任何顺序到达或根本不到达。
Stream sockets
面向连接的Socket,使用传输控制协议(TCP),流控制传输协议(SCTP)或数据报拥塞控制协议(DCCP)。Stream sockets提供无记录边界的有序且唯一的数据流,并具有定义明确的机制来创建和销毁连接以及检测错误。Stream sockets可靠地按顺序传输数据。在Internet上,Stream sockets通常在TCP之上实现,以便应用程序可以使用TCP/IP协议在任何网络上运行。
C/S模式中的Sockets
提供应用程序服务的计算机进程称为服务器,并在启动时创建处于侦听状态的Socket。这些Socket正在等待来自客户端程序的连接。
通过为每个客户端创建子进程并在子进程与客户端之间建立TCP连接,TCP服务器可以同时为多个客户端提供服务。为每个连接创建唯一的专用Socket。当与远程Socket建立Socket到Socket的虚拟连接或虚拟电路(也称为TCP 会话)时,它们处于建立状态,从而提供双工字节流。
服务器可以使用相同的本地端口号和本地IP地址创建多个同时建立的TCPSocket,每个Socket都映射到其自己的服务器子进程,为客户端进程服务。由于远程Socket地址(客户端IP地址和/或端口号)不同,因此操作系统将它们视为不同的Socket。即因为它们具有不同的Socket对元组。
UDP Socket无法处于已建立状态,因为UDP是无连接的。因此netstat不会显示UDP Socket的状态。UDP服务器不会为每个并发服务的客户端创建新的子进程,但是同一进程将通过同一Socket顺序处理来自所有远程客户端的传入数据包。这意味着UDP Socket不是由远程地址标识的,而是仅由本地地址标识的,尽管每个消息都具有关联的远程地址。
总结
本小节简要的介绍了Sockets的一些概念,介绍了Socket常见的两种类型。Socket编程技术涵盖的面和知识体现相当广泛,同样它的运用更是广泛,好不夸张的说互联网的技术都是基于Socket的。
参考资料
go tcp、udp服务
golang标准库中的网络库非常之强大,那些在其他语言处理起来非常繁琐的socket代码,在golang中变得有点呆萌,而且却非常的高效。这是因为如此目前大行其道的云服务首先golang,很多区块链都是使用golang,分布式运用和容器编排软件通用使用golang。
Tcp服务
我们先写一个tcp C/S通讯模型的demo:
package main
import (
"fmt"
"log"
"net"
"sync"
"time"
)
func main() {
addr :=":8088"
wg := sync.WaitGroup{}
server := func (){
wg.Add(1)
defer wg.Done()
l,err := net.Listen("tcp",addr)
if err !=nil {
log.Fatal(err)
}
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
handle := func(conn net.Conn) {
buff := make([]byte,1024)
n,_:=conn.Read(buff)
fmt.Println(string(buff[:n]))
conn.Write([]byte("nice to meet you too"))
}
go handle(conn)
}
}
client := func(id string) {
wg.Add(1)
defer wg.Done()
conn ,err:= net.Dial("tcp",addr)
if err !=nil {
log.Fatal(err)
}
conn.Write([]byte("nice to meet you"))
buff := make([]byte,1024)
n,_:=conn.Read(buff)
fmt.Println(id + " recv:" + string(buff[:n]))
}
go server() //启动服务端
time.Sleep(1e9) //这边停1s等服务端启动
go client("client1") //启动客服端1
go client("client2") //启动客服端2
wg.Wait()
}
$ go run main.go
nice to meet you
nice to meet you
client2 recv:nice to meet you too
client1 recv:nice to meet you to
我们用了51行代码,没有使用第三方库实现了tcp server和2个client的通讯。
Udp服务
package main
import (
"fmt"
"log"
"net"
"sync"
"time"
)
func main() {
addr :=":8088"
wg := sync.WaitGroup{}
server := func (){
wg.Add(1)
defer wg.Done()
uAddr, err := net.ResolveUDPAddr("udp", addr)
if err != nil {
log.Fatal(err)
}
l,err := net.ListenUDP("udp",uAddr)
if err !=nil {
log.Fatal(err)
}
for {
data := make([]byte,1024)
n,rAddr,err :=l.ReadFrom(data)
if err !=nil {
log.Fatal(err)
}
fmt.Println(string(data[:n]))
l.WriteTo([]byte("nice to meet you too"),rAddr)
}
}
client := func(id string) {
wg.Add(1)
defer wg.Done()
conn ,err:= net.Dial("udp",addr) //和tcp client代码相比,这边仅仅改了network类型
if err !=nil {
log.Fatal(err)
}
conn.Write([]byte("nice to meet you"))
buff := make([]byte,1024)
n,_:=conn.Read(buff)
fmt.Println(id + " recv:" + string(buff[:n]))
}
go server() //启动服务端
time.Sleep(1e9) //这边停1s等服务端启动
go client("client1") //启动客服端1
go client("client2") //启动客服端2
wg.Wait()
}
$ go run main.go
nice to meet you
nice to meet you
client2 recv:nice to meet you too
client1 recv:nice to meet you to
在Server端代码稍微和tcp的方式有点不一样,client端仅仅把net.Dial("tcp",addr) 改成net.Dial("udp",addr)同样非常简单。
运用层协议
网络协议是为计算机网络中进行数据交换而建立的规则、标准或约定的集合。通俗的说就是,双方约定的一种都能懂的数据格式。
应用层协议(application layer protocol)定义了运行在不同端系统上的应用程序进程如何相互传递报文。很多运用层协议是基于tcp的,因为可靠性对运用来说非常重要。我们常见的http,smtp(简单邮件传送协议),ftp都是基于tcp。比较少数的像dns(Domain Name System)是基于udp。
根据协议的序列化方式还可以分成 二进制协议和文本协议。
文本协议:一般是由一串ACSII字符组成,常见的文本协议有http1.0,redis通讯协议(RESP)。
二进制协议:有字节流数据组成,通常包括消息头(header)和消息体(body),消息头的长度固定,并且定义了消息体的长度。
解析文本协议解析
我们写一个解析redis 协议的demo
package main
import (
"bytes"
"errors"
"io"
"log"
"net"
"strconv"
"strings"
)
var kvMap = make(map[string]string,10)
func parseCmd(buf []byte)([]string, error){ //解析redis command 协议
var cmd []string
if buf[0] == '*' {
for i:=1;i<len(buf);i++ {
if buf[i] == '\n' && buf[i-1] =='\r'{
count,_ := strconv.Atoi(string(buf[1:i-1]))
for j:=0;j<count;j++ {
i++
if buf[i] != '$' {
return nil,errors.New("error")
}
i++
si:=i
for ;i<len(buf);i++ {
if buf[i] == '\n' && buf[i-1] =='\r' {
size,_ := strconv.Atoi(string(buf[si:i-1]))
cmd = append(cmd,string(buf[i+1:i+size+1]))
i = i+size+2
break
}
}
}
}
}
}
return cmd,nil
}
func respString(msg string) []byte { //返回redis string
b := bytes.Buffer{}
b.Write( []byte{'+'})
b.Write( []byte(msg))
b.Write([]byte{'\r','\n'})
return b.Bytes()
}
func respError(msg string) []byte{ //返回redis 错误信息
b := bytes.Buffer{}
b.Write( []byte{'-'})
b.Write( []byte(msg))
b.Write([]byte{'\r', '\n'})
return b.Bytes()
}
func respNull() []byte{ //返回redis Null
return []byte{'$', '-', '1', '\r', '\n'}
}
func setKv(writer io.Writer,key,val string) {
kvMap[key] = val
resp := respString("OK")
writer.Write(resp)
}
func getV(writer io.Writer,key string) {
if v ,found := kvMap[key];found {
resp := respString(v)
writer.Write(resp)
}else {
writer.Write(respNull())
}
}
func main() {
addr := ":8088"
l, err := net.Listen("tcp", addr)
if err != nil {
log.Fatal(err)
}
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
handle := func(conn net.Conn) {
defer conn.Close()
buf := make([]byte,1024)
n,_:=conn.Read(buf)
cmd,err := parseCmd(buf[:n])
if err !=nil {
conn.Write(respError("COMMAND not supported"))
return
}
switch strings.ToUpper(cmd[0]) {
case "SET":
setKv(conn,cmd[1],cmd[2])
case "GET":
getV(conn,cmd[1])
default:
conn.Write(respError("COMMAND not supported"))
}
}
go handle(conn)
}
}
$ go run main.go &
$ redis-cli -p 8088 ## 我们直接使用redis的cli
127.0.0.1:8088> set wida abx
OK
127.0.0.1:8088> get wida
abx
127.0.0.1:8088> llen wida
(error) COMMAND not supported
127.0.0.1:8088> get amy
(nil)
127.0.0.1:8088>
这边只是简单实现了redis get和set的功能,有兴趣的同学可以拓展下实现redis的其他功能,这样子对你了解redis的底层原理有更深的认识。
解析二进制协议
我们先定义一下消息格式
/**
请求参数:
+-----+-------+------+----------+----------+----------+
| CMD | ARGS | L1 | STR1 | Ln | STRn |
+-----+-------+------+----------+----------+----------+
| 1 | 1 | 1 | Variable | 2 | Variable |
+-----+-------+------+----------+----------+----------+
CMD 命令类型
ARG 参数个数
L1 参数一长度
STR1 参数与值
Ln 第n个参数长度
STRN 第n个参数值
返回格式
+-----+-------+----------+
| SUC | LEN | BODY |
+-----+-------+----------+
| 1 | 4 | Variable |
+-----+-------+----------+
SUC 是否成功
LEN BODY长度
BODY 消息体
*/
package main
import (
"encoding/binary"
"errors"
"fmt"
"io"
"log"
"net"
"sync"
"time"
)
type Command struct {
Cmd uint8
Args []string
}
func readCommand(r io.Reader) (*Command, error) {
cmd := Command{}
head := []byte{0, 0} //读取 CMD和ARGS
_, err := io.ReadFull(r, head)
if err != nil {
return nil, err
}
cmd.Cmd = head[0]
args := int(head[1])
for i := 0; i < args; i++ { //循环读取 Ln STRn
var length = []byte{0}
_, err = r.Read(length)
if err != nil {
return nil, err
}
str := make([]byte, int(length[0]))
_, err := io.ReadFull(r, str)
if err != nil {
return nil, err
}
cmd.Args = append(cmd.Args, string(str))
}
return &cmd, nil
}
func readResp(r io.Reader) (string, error) {
suc := []byte{0} //读取SUC 如果不成功就返回
_, err := r.Read(suc)
if err != nil {
return "", err
}
if int(suc[0]) != 0 {
return "", errors.New(fmt.Sprintf("resp errcode %v", suc[0]))
}
var bodyLen int32
err = binary.Read(r, binary.BigEndian, &bodyLen) //大端读去长度 4字节
if err != nil {
return "", err
}
body := make([]byte, bodyLen)
_, err = io.ReadFull(r, body) //读取body
if err != nil {
return "", err
}
return string(body), nil
}
func main() {
addr := ":8088"
wg := sync.WaitGroup{}
server := func() {
wg.Add(1)
defer wg.Done()
l, err := net.Listen("tcp", addr)
if err != nil {
log.Fatal(err)
}
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
handle := func(conn net.Conn) {
defer conn.Close()
for {
cmd, err := readCommand(conn)
if err != nil {
break
}
fmt.Printf("server recv :%v\n",cmd)
switch cmd.Cmd {
case 1:
//拼resp 字节
conn.Write([]byte{uint8(0)})
binary.Write(conn, binary.BigEndian, int32(10)) //大端写长长度 注意要和client约定好,当然可以用小端
conn.Write([]byte("9876543210"))
case 2:
conn.Write([]byte{uint8(0)})
binary.Write(conn, binary.BigEndian, int32(16))
conn.Write([]byte("0000009876543210"))
}
}
}
go handle(conn)
}
}
client := func() {
wg.Add(1)
defer wg.Done()
conn, _ := net.Dial("tcp", addr)
//拼CMD字节
conn.Write([]byte{uint8(1), uint8(1), uint8(10)})
conn.Write([]byte("0123456789"))
ret, _ := readResp(conn)
fmt.Println("client recv:",ret)
//拼CMD字节
conn.Write([]byte{uint8(2), uint8(1), uint8(16)})
conn.Write([]byte("0123456789000000"))
ret, _ = readResp(conn)
fmt.Println("client recv:",ret)
}
go server()
time.Sleep(1e9)
go client()
wg.Wait()
}
$ go run main.go
server recv :&{1 [0123456789]}
client recv: 9876543210
server recv :&{2 [0123456789000000]}
client recv: 0000009876543210
这边我们实现了二进制协议的解析,二进制协议的解析效率会比文本方式快,而且通常情况下会省带宽。
总结
本小节介绍了golang tcp和udp server端和client端的编写,我们还介绍了运用层协议文本协议和二进制协议的编写。本小节的demo会比较有启发性,大家可以发散思维做代码的拓展。
go socks5实现
什么是SOCKS
SOCKS是一种网络传输协议,主要用于Client端与外网Server端之间通讯的中间传递。SOCKS是"SOCKETS"的缩写,意外这一切socks都可以通过代理。 SOCKS是一种代理协议,相比于常见的HTTP代理,SOCKS的代理更加的底层,传统的HTTP代理会修改HTTP头,SOCKS则不会它只是做了数据的中转。
SOCKS的最新版本为SOCKS5。
SOCKS5协议详解
SOCKS5的协议是基于二进制的,协议设计十分的简洁。
Client端和Server端第一次通讯的时候,Client端会想服务端发送版本认证信息,协议格式如下:
+----+----------+----------+
|VER | NMETHODS | METHODS |
+----+----------+----------+
| 1 | 1 | 1 to 255 |
+----+----------+----------+
- VER是SOCKS版本,目前版本是0x05;
- NMETHODS是METHODS部分的长度;
- METHODS是Client端支持的认证方式列表,每个方法占1字节。当前的定义是:
- 0x00 不需要认证
- 0x01 GSSAPI
- 0x02 用户名、密码认证
- 0x03 - 0x7F由IANA分配(保留)
- 0x80 - 0xFE为私人方法保留
- 0xFF 无可接受的方法
Server端从Client端提供的方法中选择一个并通过以下消息通知Client端:
+----+--------+
|VER | METHOD |
+----+--------+
| 1 | 1 |
+----+--------+
- VER是SOCKS版本,目前是0x05;
- METHOD是服务端选中的方法。如果返回0xFF表示没有一个认证方法被选中,Client端需要关闭连接。
SOCKS5请求协议格式:
+----+-----+-------+------+----------+----------+
|VER | CMD | RSV | ATYP | DST.ADDR | DST.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | X'00' | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+
- VER是SOCKS版本,目前是0x05;
- CMD是SOCK的命令码
- 0x01表示CONNECT请求
- 0x02表示BIND请求
- 0x03表示UDP转发
- RSV 0x00,保留
- ATYP DST.ADDR类型
- 0x01 IPv4地址,DST.ADDR部分4字节长度
- 0x03 域名地址,DST.ADDR部分第一个字节为域名长度,剩余的内容为域名。
- 0x04 IPv6地址,16个字节长度。
- DST.ADDR 目的地址
- DST.PORT 网络字节序表示的目的端口
Server端按以下格式返回给Client端:
+----+-----+-------+------+----------+----------+
|VER | REP | RSV | ATYP | BND.ADDR | BND.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | X'00' | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+
- VER是SOCKS版本,目前是0x05;
- REP应答字段
- 0x00 表示成功
- 0x01 普通SOCKSServer端连接失败
- 0x02 现有规则不允许连接
- 0x03 网络不可达
- 0x04 主机不可达
- 0x05 连接被拒
- 0x06 TTL超时域名地址
- 0x07 不支持的命令
- 0x08 不支持的地址类型
- 0x09 - 0xFF未定义
- RSV 0x00,保留
- ATYP BND.ADDR类型
- 0x01 IPv4地址,DST.ADDR部分4字节长度
- 0x03 域名地址,DST.ADDR部分第一个字节为域名长度,剩余的内容为域名。
- 0x04 IPv6地址,16个字节长度。
- BND.ADDR Server端绑定的地址
- BND.PORT 网络字节序表示的Server端绑定的端口
用go实现socks5
package main
import (
"errors"
"fmt"
"io"
"log"
"net"
"strconv"
"strings"
)
const (
IPV4ADDR = uint8(1) //ipv4地址
DNADDR = uint8(3) //域名地址
IPV6ADDR = uint8(4) //地址
CONNECTCMD = uint8(1)
SUCCEEDED = uint8(0)
NETWORKUNREACHABLE = uint8(3)
HOSTUNREACHABLE = uint8(4)
CONNECTIONREFUSED = uint8(5)
COMMANDNOTSUPPORTED = uint8(7)
)
type Addr struct {
Dn string
IP net.IP
Port int
}
func (a Addr) Addr() string {
if 0 != len(a.IP) {
return net.JoinHostPort(a.IP.String(), strconv.Itoa(a.Port))
}
return net.JoinHostPort(a.Dn, strconv.Itoa(a.Port))
}
type Command struct {
Version uint8
Command uint8
RemoteAddr *Addr
DestAddr *Addr
RealDestAddr *Addr
reader io.Reader
}
func auth(conn io.ReadWriter) error {
header := make([]byte,2)
_,err:= io.ReadFull(conn,header)
if err!=nil {
return err
}
//igonre check version
methods := make([]byte,int(header[1]))
_,err = io.ReadFull(conn,methods)
if err!=nil {
return err
}
_,err = conn.Write([]byte{uint8(5), uint8(0)}) // 返回协议5,不需要认证
return err
}
func readAddr(r io.Reader) (*Addr, error) {
d := &Addr{}
addrType := []byte{0}
if _, err := r.Read(addrType); err != nil {
return nil, err
}
switch addrType[0] {
case IPV4ADDR:
addr := make([]byte, 4)
if _, err := io.ReadFull(r, addr); err != nil {
return nil, err
}
d.IP = net.IP(addr)
case IPV6ADDR:
addr := make([]byte, 16)
if _, err := io.ReadFull(r, addr); err != nil {
return nil, err
}
d.IP = net.IP(addr)
case DNADDR:
if _, err := r.Read(addrType); err != nil {
return nil, err
}
addrLen := int(addrType[0])
DN := make([]byte, addrLen)
if _, err := io.ReadFull(r, DN); err != nil {
return nil, err
}
d.Dn = string(DN)
default:
return nil, errors.New("unkown addr type")
}
port := []byte{0, 0}
if _, err := io.ReadFull(r, port); err != nil {
return nil, err
}
d.Port = (int(port[0]) << 8) | int(port[1])
return d, nil
}
func request(conn io.ReadWriter) (*Command, error) {
header := []byte{0, 0, 0}
if _, err := io.ReadFull(conn, header); err != nil {
return nil, err
}
//igonre check version
dest, err := readAddr(conn)
if err != nil {
return nil, err
}
cmd := &Command{
Version: uint8(5),
Command: header[1],
DestAddr: dest,
reader: conn,
}
return cmd, nil
}
func replyMsg(w io.Writer, resp uint8, addr *Addr) error {
var addrType uint8
var addrBody []byte
var addrPort uint16
switch {
case addr == nil:
addrType = IPV4ADDR
addrBody = []byte{0, 0, 0, 0}
addrPort = 0
case addr.Dn != "":
addrType = DNADDR
addrBody = append([]byte{byte(len(addr.Dn))}, addr.Dn...)
addrPort = uint16(addr.Port)
case addr.IP.To4() != nil:
addrType = IPV4ADDR
addrBody = []byte(addr.IP.To4())
addrPort = uint16(addr.Port)
case addr.IP.To16() != nil:
addrType = IPV6ADDR
addrBody = []byte(addr.IP.To16())
addrPort = uint16(addr.Port)
default:
return errors.New("format address error")
}
bodyLen := len(addrBody)
msg := make([]byte, 6+bodyLen)
msg[0] = uint8(5)
msg[1] = resp
msg[2] = 0 // RSV
msg[3] = addrType
copy(msg[4:], addrBody)
msg[4+bodyLen] = byte(addrPort >> 8)
msg[4+bodyLen+1] = byte(addrPort & 0xff)
_, err := w.Write(msg)
return err
}
func handleSocks5(conn io.ReadWriteCloser) error {
if err := auth(conn);err !=nil {
return err
}
cmd,err := request(conn)
if err !=nil {
return err
}
fmt.Printf("%v",cmd.DestAddr)
if err := handleCmd( cmd, conn); err != nil {
return err
}
return nil
}
func handleCmd(cmd *Command, conn io.ReadWriteCloser) error {
dest := cmd.DestAddr
if dest.Dn != "" {
addr, err := net.ResolveIPAddr("ip", dest.Dn)
if err != nil {
if err := replyMsg(conn, HOSTUNREACHABLE, nil); err != nil {
return err
}
return err
}
dest.IP = addr.IP
}
cmd.RealDestAddr = cmd.DestAddr
switch cmd.Command {
case CONNECTCMD:
return handleConn(conn, cmd)
default:
if err := replyMsg(conn, COMMANDNOTSUPPORTED, nil); err != nil {
return err
}
return errors.New("Unsupported command")
}
}
func handleConn(conn io.ReadWriteCloser, req *Command) error {
target, err := net.Dial("tcp", req.RealDestAddr.Addr())
if err != nil {
msg := err.Error()
resp := HOSTUNREACHABLE
if strings.Contains(msg, "refused") {
resp = CONNECTIONREFUSED
} else if strings.Contains(msg, "network is unreachable") {
resp = NETWORKUNREACHABLE
}
if err := replyMsg(conn, resp, nil); err != nil {
return err
}
return errors.New(fmt.Sprintf("Connect to %v failed: %v", req.DestAddr, err))
}
defer target.Close()
local := target.LocalAddr().(*net.TCPAddr)
bind := Addr{IP: local.IP, Port: local.Port}
if err := replyMsg(conn, SUCCEEDED, &bind); err != nil {
return err
}
go io.Copy(target, req.reader)
io.Copy(conn, target)
return nil
}
func main() {
l,err := net.Listen("tcp",":8090")
if err !=nil {
log.Fatal(err)
}
for {
conn, err := l.Accept()
if err != nil {
log.Fatal(err)
}
handle := func(conn net.Conn) {
handleSocks5(conn)
}
go handle(conn)
}
}
$ go run main.go
&{ 180.101.49.12 443} ## 使用curl出现
$ export ALL_PROXY=socks5://127.0.0.1:8090 # 设置终端代理
$ curl https://www.baidu.com
<!DOCTYPE html>
...
上面的例子中我们,使用了linux的终端代理,这边隐藏了一个细节就是,终端代理实践上有socks5 client,所以我们并没有自己拼client相关的二进制协议。 linux的终端只支持http,https。像ssh协议这需要自己去实现client协议,有兴趣的同学可以自己去实现下,这不不再赘述。
总结
本小节介绍了socks5的协议,以及实现了socks代理server。socks5其实不仅仅支持tcp还有支持udp。总体来说是一个简洁但功能强大的协议。
go WebSocket
什么是WebSocket
WebSocket是一种网络传输协议,可在单个TCP连接上进行全双工通信。其实看这定义会发现,跟其他Socket的协议没什么区别,都是全双工通信,叫WebSocket有何深意? WebSocket使用了http和https的端口也就是80和443端口,同时第一次握手(handshaking)是基于http1.1。
WebSocket使用场景
WebSocket主要还是使用来浏览器和后端交互上,特别是js和后端服务的交互。在WebSocket出现之前,浏览器js和后端难以建立长连接,后端主动通知前端没有有效途径,只能靠前端自己轮循后端接口实现,这样子的做法低效而且相当耗资源。WebSocket的出现正好可以解决这个痛点。
WebSocket 握手过程
一个典型的Websocket握手请求如下:
客户端请求
GET / HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: example.com
Origin: http://example.com
Sec-WebSocket-Key: sN9cRrP/n9NdMgdcy2VJFQ==
Sec-WebSocket-Version: 13
服务器回应
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: fFBooB7FAkLlXgRSz0BT3v4hq5s=
Sec-WebSocket-Location: ws://example.com/
字段说明
- Connection必须设置Upgrade,表示客户端希望连接升级。
- Upgrade字段必须设置Websocket,表示希望升级到Websocket协议。
- Sec-WebSocket-Key是随机的字符串,服务器端会用这些数据来构造出一个SHA-1的信息摘要。把“Sec-WebSocket-Key”加上一个特殊字符串“258EAFA5-E914-47DA-95CA-C5AB0DC85B11”,然后计算SHA-1摘要,之后进行BASE-64编码,将结果做为“Sec-WebSocket-Accept”头的值,返回给客户端。如此操作,可以尽量避免普通HTTP请求被误认为Websocket协议。
- Sec-WebSocket-Version 表示支持的Websocket版本。RFC6455要求使用的版本是13,之前草案的版本均应当弃用。
- Origin字段是可选的,通常用来表示在浏览器中发起此Websocket连接所在的页面,类似于Referer。但是,与Referer不同的是,Origin只包含了协议和主机名称。
WebSocket数据帧
WebSocket在握手之后不再使用文本协议,而是采用二进制协议。它的数据帧格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
稍微有点复杂,各个字段的定义可以参考RFC6455 5.2。这边不再赘述。
go实现Websocket
golang的标准库就支持Websocket,但是我们推荐特性支持更多,而且性能更强的gorilla。
### 实现“回音程序” 我们写一个“回音程序”(client给服务端发消息,服务端回复给你同样的消息)。
package main
import (
"github.com/gorilla/websocket"
"html/template"
"net/http"
"log"
)
var addr = "localhost:8080"
var upgrader = websocket.Upgrader{}
func echo(w http.ResponseWriter, r *http.Request) {
c, err := upgrader.Upgrade(w, r, nil)
if err != nil {
log.Print("upgrade:", err)
return
}
defer c.Close()
for { //这边跟其他 和其他socket编程没什么区别,循环读取数消息
mt, message, err := c.ReadMessage()
if err != nil {
log.Println("read:", err)
break
}
log.Printf("server recv: %s", message)
err = c.WriteMessage(mt, message)
if err != nil {
log.Println("write:", err)
break
}
}
}
func home(w http.ResponseWriter, r *http.Request) {
homeTemplate.Execute(w, "ws://"+r.Host+"/echo")
}
func main() {
http.HandleFunc("/echo", echo)
http.HandleFunc("/", home)
log.Fatal(http.ListenAndServe(addr, nil))
}
var homeTemplate = template.Must(template.New("").Parse(`
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<script>
window.addEventListener("load", function(evt) {
var output = document.getElementById("output");
var input = document.getElementById("input");
var ws;
var print = function(message) {
var d = document.createElement("div");
d.innerHTML = message;
output.appendChild(d);
};
document.getElementById("open").onclick = function(evt) {
if (ws) {
return false;
}
ws = new WebSocket("{{.}}");
ws.onopen = function(evt) {
print("OPEN");
}
ws.onclose = function(evt) {
print("CLOSE");
ws = null;
}
ws.onmessage = function(evt) {
print("RESPONSE: " + evt.data);
}
ws.onerror = function(evt) {
print("ERROR: " + evt.data);
}
return false;
};
document.getElementById("send").onclick = function(evt) {
if (!ws) {
return false;
}
print("SEND: " + input.value);
ws.send(input.value);
return false;
};
document.getElementById("close").onclick = function(evt) {
if (!ws) {
return false;
}
ws.close();
return false;
};
});
</script>
</head>
<body>
<table>
<tr><td valign="top" width="50%">
<p>点击 "打开" 创建websocket连接,
点击 "发送" 将发送信息给服务端 , 点击"关闭" 将关闭websocket连接.
<p>
<form>
<button id="open">打开</button>
<button id="close">关闭</button>
<p><input id="input" type="text" value="Hello world!">
<button id="send">发送</button>
</form>
</td><td valign="top" width="50%">
<div id="output"></div>
</td></tr></table>
</body>
</html>
`))
运行程序
$ go run main.go
然后用chrome浏览器器访问http://localhost:8080/你会看到页面,按照页面提示操作,体验WebSocket创建和发送消息。
给服务端发shell命令
WebSocket可以让浏览器后端见了一个全双工通道,本质上就是一个tcp连接,所以能做的事情应该很多,比如ssh over WebSocket。 这个demo程序展示客服端发shell 命令在服务端执行并返回执行结果。
$ tree
.
├── go.mod
├── go.sum
├── home.html
└── main.go
main.go内容:
package main
import (
"bufio"
"flag"
"io"
"log"
"net/http"
"os"
"os/exec"
"time"
"github.com/gorilla/websocket"
)
var (
addr = flag.String("addr", "127.0.0.1:8080", "http service address")
cmdPath string
)
const (
writeWait = 10 * time.Second
maxMessageSize = 8192
pongWait = 60 * time.Second
pingPeriod = (pongWait * 9) / 10
closeGracePeriod = 10 * time.Second
)
func pumpStdin(ws *websocket.Conn, w io.Writer) {
defer ws.Close()
ws.SetReadLimit(maxMessageSize)
ws.SetReadDeadline(time.Now().Add(pongWait))
ws.SetPongHandler(func(string) error { ws.SetReadDeadline(time.Now().Add(pongWait)); return nil })
for {
_, message, err := ws.ReadMessage()
if err != nil {
break
}
message = append(message, '\n')
if _, err := w.Write(message); err != nil {
break
}
}
}
func pumpStdout(ws *websocket.Conn, r io.Reader, done chan struct{}) {
defer func() {
}()
s := bufio.NewScanner(r)
for s.Scan() {
ws.SetWriteDeadline(time.Now().Add(writeWait))
if err := ws.WriteMessage(websocket.TextMessage, s.Bytes()); err != nil {
ws.Close()
break
}
}
if s.Err() != nil {
log.Println("scan:", s.Err())
}
close(done)
ws.SetWriteDeadline(time.Now().Add(writeWait))
ws.WriteMessage(websocket.CloseMessage, websocket.FormatCloseMessage(websocket.CloseNormalClosure, ""))
time.Sleep(closeGracePeriod)
ws.Close()
}
func ping(ws *websocket.Conn, done chan struct{}) {
ticker := time.NewTicker(pingPeriod)
defer ticker.Stop()
for {
select {
case <-ticker.C:
if err := ws.WriteControl(websocket.PingMessage, []byte{}, time.Now().Add(writeWait)); err != nil {
log.Println("ping:", err)
}
case <-done:
return
}
}
}
func internalError(ws *websocket.Conn, msg string, err error) {
log.Println(msg, err)
ws.WriteMessage(websocket.TextMessage, []byte("Internal server error."))
}
var upgrader = websocket.Upgrader{}
func serveWs(w http.ResponseWriter, r *http.Request) {
ws, err := upgrader.Upgrade(w, r, nil)
if err != nil {
log.Println("upgrade:", err)
return
}
defer ws.Close()
outr, outw, err := os.Pipe()
if err != nil {
internalError(ws, "stdout:", err)
return
}
defer outr.Close()
defer outw.Close()
inr, inw, err := os.Pipe()
if err != nil {
internalError(ws, "stdin:", err)
return
}
defer inr.Close()
defer inw.Close()
proc, err := os.StartProcess(cmdPath, flag.Args(), &os.ProcAttr{
Files: []*os.File{inr, outw, outw},
})
if err != nil {
internalError(ws, "start:", err)
return
}
inr.Close()
outw.Close()
stdoutDone := make(chan struct{})
go pumpStdout(ws, outr, stdoutDone)
go ping(ws, stdoutDone)
pumpStdin(ws, inw)
inw.Close()
if err := proc.Signal(os.Interrupt); err != nil {
log.Println("inter:", err)
}
select {
case <-stdoutDone:
case <-time.After(time.Second):
// A bigger bonk on the head.
if err := proc.Signal(os.Kill); err != nil {
log.Println("term:", err)
}
<-stdoutDone
}
if _, err := proc.Wait(); err != nil {
log.Println("wait:", err)
}
}
func serveHome(w http.ResponseWriter, r *http.Request) {
if r.URL.Path != "/" {
http.Error(w, "Not found", http.StatusNotFound)
return
}
if r.Method != "GET" {
http.Error(w, "Method not allowed", http.StatusMethodNotAllowed)
return
}
http.ServeFile(w, r, "home.html")
}
func main() {
var err error
cmdPath, err = exec.LookPath("sh")
if err != nil {
log.Fatal(err)
}
http.HandleFunc("/", serveHome)
http.HandleFunc("/ws", serveWs)
log.Fatal(http.ListenAndServe(*addr, nil))
}
home.html内容
<!DOCTYPE html>
<html lang="en">
<head>
<title>Command Example</title>
<script type="text/javascript">
window.onload = function () {
var conn;
var msg = document.getElementById("msg");
var log = document.getElementById("log");
function appendLog(item) {
var doScroll = log.scrollTop > log.scrollHeight - log.clientHeight - 1;
log.appendChild(item);
if (doScroll) {
log.scrollTop = log.scrollHeight - log.clientHeight;
}
}
document.getElementById("form").onsubmit = function () {
if (!conn) {
return false;
}
if (!msg.value) {
return false;
}
conn.send(msg.value);
msg.value = "";
return false;
};
if (window["WebSocket"]) {
conn = new WebSocket("ws://" + document.location.host + "/ws");
conn.onclose = function (evt) {
var item = document.createElement("div");
item.innerHTML = "<b>Connection closed.</b>";
appendLog(item);
};
conn.onmessage = function (evt) {
var messages = evt.data.split('\n');
for (var i = 0; i < messages.length; i++) {
var item = document.createElement("div");
item.innerText = messages[i];
appendLog(item);
}
};
} else {
var item = document.createElement("div");
item.innerHTML = "<b>Your browser does not support WebSockets.</b>";
appendLog(item);
}
};
</script>
<style type="text/css">
html {
overflow: hidden;
}
body {
overflow: hidden;
padding: 0;
margin: 0;
width: 100%;
height: 100%;
background: gray;
}
#log {
background: white;
margin: 0;
padding: 0.5em 0.5em 0.5em 0.5em;
position: absolute;
top: 0.5em;
left: 0.5em;
right: 0.5em;
bottom: 3em;
overflow: auto;
}
#log pre {
margin: 0;
}
#form {
padding: 0 0.5em 0 0.5em;
margin: 0;
position: absolute;
bottom: 1em;
left: 0px;
width: 100%;
overflow: hidden;
}
</style>
</head>
<body>
<div id="log"></div>
<form id="form">
<input type="submit" value="Send" />
<input type="text" id="msg" size="64"/>
</form>
</body>
</html>
运行程序
$ go run main.go
用chrome浏览器打开http://localhost:8080/,在最下发发送ls或者netstat等等命令,可以在显示区域看到执行结果。
总结
WebSocket一般不会用来做后端后后端的通信,经常来做web前端和后端的通信。本小节简要的介绍了WebSocket的工作原理和它的常见使用场景。以及用两个demo展示WebSocket的能力。其实还有很多场景可以去挖掘,感兴趣的同学可以去研究下。
参考资料
深入理解connection multiplexing
yamux是golang连接多路复用(connection multiplexing)的一个库,想法来源于google的SPDY(也就是后来的http2)。yamux能用很小的代价在一个真实连接(net connection)上实现上千个Client-Server逻辑流。
基本概念
-
session(会话) session用于包裹(wrap)可靠的有序连接(net connection)并将其多路复用为多个流(stream)。
-
stream(流) 在session中,stream代表一个client-server逻辑流。stream有唯一且自增(+2)的id,客服端向server端的stream id为奇数,服务端向客户端发送的stream为偶数,同事0值代表session。stream是逻辑概念,传输的数据是以帧的形态传输的。
-
frame(帧)
帧是在session中真正传输的数据,帧有两部分header和body- header包含12个字节的数据,(也就算每次消息发送会参数额外12字节)。
- Version (8 bits) 协议版本,目前总是为0
- Type (8 bits) 帧消息类型,
- 0x0(Data)数据传输
- 0x1(Window Update) 用更新stream收消息recvWindow的大小。(注意这个时候length字段则为窗口的增量值)
- 0x2(Ping)心跳,keep alives和RTT度量作用
- 0x3(Go Away) 用于关闭会话
- Flags (16 bits)
- 0x1 SYN : 新stream需要被创建
- 0x2 ACK : 确认新stream开始
- 0x4 FIN : 执行stream的半关闭
- 0x8 RST : 立即重置stream
- StreamID (32 bits) 流ID用于区分逻辑流
- Length (32 bits) body的长度或者type为Window Update时的delta值
- body 是真实需要传输的数据,可能没有。
- header包含12个字节的数据,(也就算每次消息发送会参数额外12字节)。
实现原理
yamux multiplexing 如何实现的
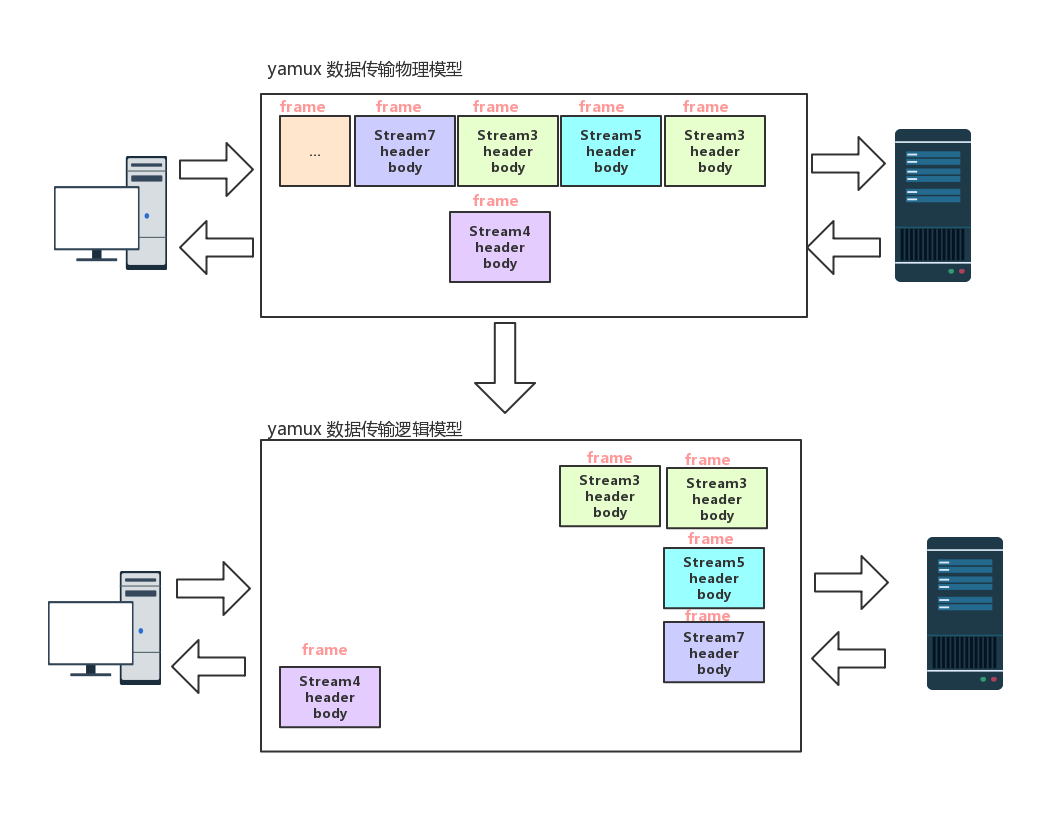
从上图我们可以看出multiplexing的原理:传输过程中使用frame传输,每个frame都带有stream ID,在传输过程中stream相同stream的数据有先后顺序但可能不是连续的,接收端通过逻辑映射关系整合成有序的stream。
stream的状态变迁
类似tcp连接,每一个stream都是有链接状态的。一个新的stream在创建的时候client会向server发送SYN信息(这边和tcp有个不一样的地方是,SYN发送后可以立即发送数据而不是等等对方ACK后再发),server端接收到SYN信息后会回传ACK信息。close的时候会给对方发送FIN,对方接收到同样会回一个FIN。这个过程会伴随整个stream的状态变迁。
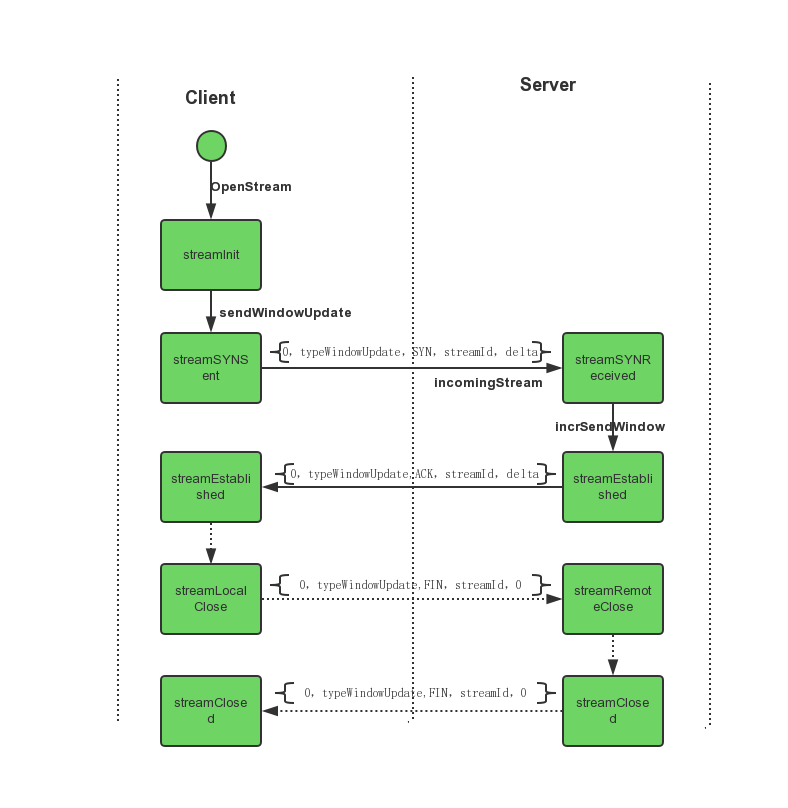
上图还有一种 streamReset 状态没有呈现,server端Accept等待队列满的时候会发flagRST送给client的信息,client收到这个消息后会把流状态设置成streamReset这个时候流会停止。
流控制(Flow Control)
类似TCP的流控制,yamux也提供一种机制可以让发送端根据接收端接收能力控制发送的数据的大小。Tcp流控制的操作是接收端向发送端通知自己可以接收数据的大小,发送端会发送不超过这个限度的数据。这个大小限度就被称作窗口(window)大小。我们从stream状态迁移的图中看到了一个概念-window(窗口),就是和Tcp窗口类似的概念。
yamux的每个stream的初始窗口为256k,当然这个值是是可以配置修改的,在stream的SYN和ACK的消息交互中就带了窗口大小的协商。
窗口的大小由接收端决定的,接收端将自己可以接收的缓冲区大小通typeWindowUpdate类型的Header发送给发送端,发送端根据这个值调整自己发送数据的大小,如果发现是0就会阻塞发送。
源码分析
创建session和数据读写
创建session只能通过 Server(conn io.ReadWriteCloser, config *Config) 和 func Client(conn io.ReadWriteCloser, config *Config) 这两个方法创建,本质上都调用了newSession的方法。我们具体看下newSession的方法。
func newSession(config *Config, conn io.ReadWriteCloser, client bool) *Session {
...
s := &Session{
config: config,
logger: logger,
conn: conn, //真实连接(实际上io.ReadWriteCloser)
bufRead: bufio.NewReader(conn),
pings: make(map[uint32]chan struct{}),
streams: make(map[uint32]*Stream), //流映射
inflight: make(map[uint32]struct{}),
synCh: make(chan struct{}, config.AcceptBacklog),
acceptCh: make(chan *Stream, config.AcceptBacklog), // 控制accept 队列长度
sendCh: make(chan sendReady, 64), //发送的队列长度
recvDoneCh: make(chan struct{}), //recvloop 终止信号
shutdownCh: make(chan struct{}), //session 关闭信号
}
if client {
s.nextStreamID = 1 //client端的话初始stream Id是1
} else {
s.nextStreamID = 2 //client端的话初始stream Id是2
}
go s.recv() //循环读取真实连接frame数据,然后分发到相应的message-type handler
go s.send() //循环通过真实连接发送frame数据
if config.EnableKeepAlive {
go s.keepalive() //通过`ping`心跳保持连接
}
return s
}
从上面的代码我们可以看出client和server唯一的区别是nextStreamID不一样,发送和接收数据的方式并没有区别。
Session.recv() 实际调用的是Session.recvLoop方法
defer close(s.recvDoneCh)
hdr := header(make([]byte, headerSize))
for {
// Read the header
if _, err := io.ReadFull(s.bufRead, hdr); err != nil { //读取 frame Header
...省略错误处理代码
}
...省略版本确认代码
mt := hdr.MsgType()
if mt < typeData || mt > typeGoAway { //验证header type
return ErrInvalidMsgType
}
if err := handlers[mt](s, hdr); err != nil { //handle header type
...省略代码
}
}
handlers 是一个全局变量,已经初始化的一个函数指针数组
handlers = []func(*Session, header) error{
typeData: (*Session).handleStreamMessage,
typeWindowUpdate: (*Session).handleStreamMessage,
typePing: (*Session).handlePing,
typeGoAway: (*Session).handleGoAway,
}
我们重点关注 handleStreamMessage方法,这个方法处理typeWindowUpdate和typeData这两个核心的消息类型。
func (s *Session) handleStreamMessage(hdr header) error {
id := hdr.StreamID()
flags := hdr.Flags()
if flags&flagSYN == flagSYN {
if err := s.incomingStream(id); err != nil { //如果是SYN信号,在接收端初始化stream作为发送端的副本和发送的stream保持通讯和协同window大小。创建后又通过
return err
}
}
// Get the stream
s.streamLock.Lock()
stream := s.streams[id]
s.streamLock.Unlock()
...省略代码
if hdr.MsgType() == typeWindowUpdate {
if err := stream.incrSendWindow(hdr, flags); err != nil { //如果是typeWindowUpdate类型,这个调节本地发送窗口(sendWindow),触发`sendNotifyCh`可以发送更多数据
...省略错误处理代码
return err
}
return nil
}
if err := stream.readData(hdr, flags, s.bufRead); err != nil { //读取body
...省略错误处理代码
return err
}
return nil
}
总得来说 recv 的工作职责就是,读取每一个frame header,然后根据header type handle到不同的处理函数中。
Session.send()方法就相对简单些,职责是用底层真实链接发送frame给接收方。
func (s *Session) send() {
for {
select {
case ready := <-s.sendCh: //从缓冲管道(队列)获取frame
if ready.Hdr != nil {
sent := 0
for sent < len(ready.Hdr) {
n, err := s.conn.Write(ready.Hdr[sent:]) //先写header
if err != nil {
...省略错误处理代码
return
}
sent += n
}
}
if ready.Body != nil { //如果有body写body
_, err := io.Copy(s.conn, ready.Body)
if err != nil {
...省略错误处理代码
}
}
...省略代码
}
}
Stream创建和数据读写
Stream的创建一定是先在发送端创建的,然后通过一个SYN信号的发送到了接收方,Session.incomingStream的接收的stream就是从客户端发送过来的。
func (s *Session) OpenStream() (*Stream, error) {
...省略代码
GET_ID:
id := atomic.LoadUint32(&s.nextStreamID)
...省略代码
if !atomic.CompareAndSwapUint32(&s.nextStreamID, id, id+2) {
goto GET_ID
}
stream := newStream(s, id, streamInit) //创建新的stream,注意streamInit 状态和上面状态迁移的图对应这看
s.streamLock.Lock()
s.streams[id] = stream //这边发送端注册stream
s.inflight[id] = struct{}{}
s.streamLock.Unlock()
if err := stream.sendWindowUpdate(); err != nil { //通知接收方有新的stream创建,stream状态改成flagSYN,还把window的size告诉接收方
select {
case <-s.synCh:
default:
...省略错误处理代码
}
return nil, err
}
return stream, nil
}
这边对照这Session.incomingStream的代码一块看
func (s *Session) incomingStream(id uint32) error {
...省略错误处理代码
stream := newStream(s, id, streamSYNReceived) //id和客户端的一样。状态迁移
s.streamLock.Lock()
defer s.streamLock.Unlock()
if _, ok := s.streams[id]; ok {
...省略错误处理代码
return ErrDuplicateStream
}
s.streams[id] = stream //在接收到注册新的stream
select {
case s.acceptCh <- stream: //通过 Session.acceptCh管道通知接收端有新的stream
return nil
default:
...省略错误处理代码
}
}
Stream的读取操作
func (s *Stream) Read(b []byte) (n int, err error) {
defer asyncNotify(s.recvNotifyCh)
START:
...省略状态判断代码
s.recvLock.Lock()
if s.recvBuf == nil || s.recvBuf.Len() == 0 {
s.recvLock.Unlock()
goto WAIT
}
n, _ = s.recvBuf.Read(b)
s.recvLock.Unlock()
err = s.sendWindowUpdate() //这边就是上文提到流控相关的代码,向发送端发送改变window大小的信息,调节(增加)发送端发送流量。
return n, err
WAIT:
var timeout <-chan time.Time
var timer *time.Timer
readDeadline := s.readDeadline.Load().(time.Time)
if !readDeadline.IsZero() { //读超时判断
delay := readDeadline.Sub(time.Now())
timer = time.NewTimer(delay)
timeout = timer.C
}
select {
case <-s.recvNotifyCh:
if timer != nil {
timer.Stop()
}
goto START
case <-timeout:
return 0, ErrTimeout
}
}
stream的写操作,yamux稍微做了下个封装,来处理由于window大小限制带来的分包发送问题。
func (s *Stream) Write(b []byte) (n int, err error) {
s.sendLock.Lock()
defer s.sendLock.Unlock()
total := 0
for total < len(b) { //被分包了
n, err := s.write(b[total:])
total += n
if err != nil {
return total, err
}
}
return total, nil
}
func (s *Stream) write(b []byte) (n int, err error) {
var flags uint16
var max uint32
var body io.Reader
START:
...省略状态判断代码
window := atomic.LoadUint32(&s.sendWindow)
if window == 0 {
goto WAIT
}
flags = s.sendFlags()
max = min(window, uint32(len(b)))
body = bytes.NewReader(b[:max])
s.sendHdr.encode(typeData, flags, s.id, max) //封装header
if err = s.session.waitForSendErr(s.sendHdr, body, s.sendErr); err != nil { //封装sendReady{Hdr: hdr, Body: body, Err: errCh}给 Session.sendCh 管道,然后Session.send会发送这个frame
select {
case s.sendCh <- ready:
return 0, err
}
atomic.AddUint32(&s.sendWindow, ^uint32(max-1)) //减少sendWindow大小
return int(max), err
WAIT:
var timeout <-chan time.Time
writeDeadline := s.writeDeadline.Load().(time.Time)
if !writeDeadline.IsZero() { //写超时判断
delay := writeDeadline.Sub(time.Now())
timeout = time.After(delay)
}
select {
case <-s.sendNotifyCh: //可以在发送的信号
goto START
case <-timeout:
return 0, ErrTimeout
}
return 0, nil
}
总的来说,了解connection multiplexing的工作原理后在看代码会非常容易理解,如果不懂原理直接看代码就会非常晦涩难懂,特别是向golang这样,一个channel或者interface之后代码上下文就不好联系上。
总结
yamux的原理和代码分析到这边,我大致等了解它的工作原理,这对我们了解grpc和http2非常有帮助。yamux作为golang生态中优秀的connection multiplexing库目前被广泛用在p2p领域。
参考文档
微服务
什么是微服务
注:来自维基百科 微服务 (Microservices) 是一种软件架构风格,它是以专注于单一责任与功能的小型功能区块为基础,利用模块化的方式组合出复杂的大型应用程序,各功能区块使用与语言无关 的 API 集相互通信。
微服务的规划与单体式应用程序十分不同,微服务中每个服务都需要避免与其他服务有所牵连,且都要能够自主,并在其他服务发生错误时不受干扰。其实这也SOA(面向服务编程)的理念非常类似,应该说微服务不算一个全新的一个概念,只是这几年随着容器技术的成熟,微服务的实践越来越方便。
微服务特点
注:来自维基百科 一个微服务框架的应用程序有下列特性:
- 每个服务都容易被取代。
- 服务是以能力来组织的,例如用户界面、前端、推荐系统、账单或是物流等。
- 由于功能被拆成多个服务,因此可以由不同的编程语言、数据库实现。
- 架构是对称而非分层(即生产者与消费者的关系)。
- 一个微服务框架:
- 适用于具持续交付 (Continuous Delivery) 的软件开发流程。
- 与服务导向架构 (Service-Oriented Architecture) 不同,后者是集成各种业务的应用程序,但微服务只属于一个应用程序。
微服务的技术核心
-
服务发现(Service Discovery):
微服务上线后只需要在服务注册中心,注册自己ip和服务内容,并不需要想整个集群广播自己的。当某个服务要调用某个服务时会向注册中心询问该服务的ip地址。服务注册中心保留了集群的服务到ip的映射关系,同时还会检查每个服务的健康状态,及时摘除故障服务或节点。
-
容器技术
单体运营拆分成微服务后,部署和伸缩都会比单体运用复杂很多,所以说没有容器技术,微服务还是很难盛行的。
容器技术特点:
- 轻量:相比于虚拟机计算。容器技术非常轻量,有更快的启动时间。
- 易于部署迁移:由于环境一致性,所以能做到一次构建,处处部署;
- 弹性伸缩:Kubernetes、docker Swarm等容器编排技术,可以做到弹性伸缩。
go和微服务
当前践行微服务的主流编程语言只有go和java,go由于容器话技术的友好支持,成为微服务的首选语言。
go的微服务生态也很齐全,服务发现 (consun,etcd),通讯协议(go-grpc),微服务框架(go-micro,go-kit)等等都非常成熟。
参考资料
grpc和protobuf
什么是rpc
RPC(Remote Procedure Call),翻译成中文叫远程过程调用。其设计思路是程序A可以像支持本地函数一样调用远程程序B的一个函数。程序A和程序B很可能不在一台机器上,这中间就需要网络通讯,一般都是基于tcp或者http协议。函数有入参和返回值这里就需要约定一致的序列化方式,比较常见的有binary,json,xml。函数的调用过程可以同步和异步。随着分布式程序近几年的大行其道,rpc作为其主要的通讯方式也越来越进入我们的视野,比如grpc,thrift。
go标准库的rpc
golang的标准库就支持rpc。
server端
package main
import (
"errors"
"log"
"net"
"net/rpc"
)
type Param struct {
A,B int
}
type Server struct {}
func (t *Server) Multiply(args *Param, reply *int) error {
*reply = args.A * args.B
return nil
}
func (t *Server) Divide(args *Param, reply *int) error {
if args.B == 0 {
return errors.New("divide by zero")
}
*reply = args.A / args.B
return nil
}
func main() {
rpc.RegisterName("test", new(Server))
listener, err := net.Listen("tcp", ":9700")
if err != nil {
log.Fatal("ListenTCP error:", err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Fatal("Accept error:", err)
}
go rpc.ServeConn(conn)
}
}
client端
package main
import (
"fmt"
"log"
"net/rwida/micro-server
"time"wida/micro-server
)
type Param struct {
A,B int
}
func main() {
client, err := rpc.Dial("tcp", "localhost:9700")
if err != nil {
log.Fatal("dialing:", err)
}
//同步调用
var reply int
err = client.Call("test.Multiply", Param{34,35}, &reply)
if err != nil {
log.Fatal(err)
}
fmt.Println(reply)
//异步调用
done := make(chan *rpc.Call, 1)
client.Go("test.Divide", Param{34,17}, &reply,done)
select {
case d := <-done:
fmt.Println(* d.Reply.(*int))
case <-time.After(3e9):
fmt.Println("time out")
}
}
$ go run server/main.go &
$ go run client/main.go
1190
2
程序中我们没有看到参数的序列化和反序列化过程,实际上go标准库rpc使用encoding/gob做了序列化和反序列化操作,但是encoding/gob只支持go语言内部做交互,如果需要夸语言的话就不能用encoding/gob了。我们还可以使用标准库中的jsonrpc.
server
package main
import (
"errors"
"log"
"net"
"net/rpc"
"net/rpc/jsonrpc"
)
type Param struct {
A,B int
}
type Server struct {}
func (t *Server) Multiply(args *Param, reply *int) error {
*reply = args.A * args.B
return nil
}
func (t *Server) Divide(args *Param, reply *int) error {
if args.B == 0 {
return errors.New("divide by zero")
}
*reply = args.A / args.B
return nil
}
func main() {
rpc.RegisterName("test", new(Server))
listener, err := net.Listen("tcp", ":9700")
if err != nil {
log.Fatal("ListenTCP error:", err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Fatal("Accept error:", err)
}
go rpc.ServeCodec(jsonrpc.NewServerCodec(conn))
}
}
$ go run server/main.go &
$ echo -e '{"method":"test.Multiply","params":[{"A":34,"B":35}],"id":0}' | nc localhost 9700
{"id":0,"result":1190,"error":null}
$ echo -e '{"method":"test.Divide","params":[{"A":34,"B":17}],"id":1}' | nc localhost 9700
{"id":0,"result":1190,"error":null}
这个例子中我们用go写了服务端,客户端我们使用linux 命令行工具nc(natcat可能需要单独安装)直接和服务端交互。可以看到交互的序列化方式是json,因此其它语言也很容易实现和该服务端的交互。
当然我们上面演示的是基于tcp的rpc方式,标准库同时也支持http协议的rpc,感兴趣的同学可以去了解下,这边就不做展开介绍。
GRPC
上面我们发了一些篇幅介绍了标准库的rpc,主要的目的是了解rpc是什么。实际的开发中我们反而比较少用标准库的rpc,我们通常会选择grpc,grpc不仅仅在go生态里头非常流行,在其他语言生态里头同样也非常流行。
grpc是google公司开发的基于http2协议设计和protobuf开发的,高性能,跨语言的rpc框架。这边着重介绍下http2的一个重要特性当tcp多路复用功能,说得直白点就是一个在tcp链接执行多个请求,所以Service A提供N多个服务,Client B和A的所有交互都只用一个链接,这样子可以省很多的链接资源。对tcp连接复用( connection multiplexing)感兴趣的同学可以阅读下yamux的源码。
protobuf
protobuf是google开发的一种平台中立,语言中立,可拓展的数据描述语言。类似json,xml等数据描述语言类似,proto也实现了自己的序列化和反序列化方式,对相对于json来说,protobuf序列化效率更高,体积更小。官方地址protobuf有兴趣的同学可以看看。
protobuf安装
我们可以从protobuf/releases里头下载到相应的二进制版本安装protobuf。比如
protoc-3.10.0-win32.zip
protoc-3.10.0-linux-x86_64.zip
解压文件到文件夹,然后将该文件目录添加到环境变量PATH中。
$ protoc --version
libprotoc 3.10.0
ok protobuf就安装成功了。
安装protobuf go插件
go get -u -v github.com/golang/protobuf/proto
go get -u -v github.com/golang/protobuf/protoc-gen-go
hello world
新建一个go项目
├── client
│ └── main.go
├── pb
│ ├── gen.sh
│ └── search.proto
└── server
└── main.go
protobuf 消息定义文件为 pb/search.proto
syntax = "proto3";
package pb;
service Searcher {
rpc Search (SearchRequest) returns (SearchReply) {}
}
message SearchRequest {
bool name = 1;
}
message SearchReply {
string name = 1;
}
这个文件我定义了rpc的服务Searcher,里头定了一个接口Search,同时定义了入参和返回值类型。
我们写一个shell脚本gen.sh来生成go程序文件
#!/bin/bash
PROTOC=`which protoc`
$PROTOC --go_out=plugins=grpc:. search.proto
cd 到pb文件夹执行 gen.sh 脚本
$ ./gen.sh
$ cd ../ && tree
├── client
│ └── main.go
├── pb
│ ├── gen.sh
│ ├── search.pb.go
│ └── search.proto
└── server
└── main.go
可以看到我们多了一个 search.pb.go的文件。
我们在server文件下写我们服务main.go
package main
import (
"log"
"net"
"context"
"github.com/widaT/gorpc_demo/grpc/pb"
"google.golang.org/grpc"
)
const (
port = ":50051"
)
type server struct{}
func (s *server) Search(ctx context.Context, in *pb.SearchRequest) (*pb.SearchReply, error) {
return &pb.SearchReply{Name:"hello " + in.GetName()}, nil
}
func main() {
lis, err := net.Listen("tcp", port)
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
s := grpc.NewServer()
pb.RegisterSearcherServer(s, &server{})
s.Serve(lis)
}
我们在client文件下写我们的客户端main.go
package main
import (
"context"
"fmt"
"github.com/widaT/gorpc_demo/grpc/pb"
"google.golang.org/grpc"
"log"
"time"
)
const (
address = "localhost:50051"
)
func main() {
// Set up a connection to the server.
conn, err := grpc.Dial(address, grpc.WithInsecure())
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
c := pb.NewSearcherClient(conn)
s := time.Now()
r, err := c.Search(context.Background(), &pb.SearchRequest{Name: "world"})
if err != nil {
log.Fatalf("could not greet: %v", err)
}
fmt.Println(r , time.Now().Sub(s))
}
$ go run server/main.go &
$ go run client/main.go &
name:"hello world" 14.767013ms
grpc stream
上面的hello world程序演示了grpc的一般用法,这种方式能满足大部分的场景。grpc还提供了双向或者单向流的方式我们成为grpc stream,stream的方式一般用在有大量的数据交互或者长时间交互。
我们修改的grpc服务定义文件pb/search.proto,在service增加 rpc Search2 (stream SearchRequest) returns (stream SearchReply) {}
syntax = "proto3";
package pb;
service Searcher {
rpc Search (SearchRequest) returns (SearchReply) {}
rpc Search2 (stream SearchRequest) returns (stream SearchReply) {}
}
message SearchRequest {
string name = 1;
}
message SearchReply {
string name = 1;
}
服务端我们修改代码,添加一个func (s *server) Search2(pb.Searcher_Search2Server) error的一个实现方法。
package main
import (
"io"
"log"
"net"
"context"
"github.com/widaT/gorpc_demo/grpc/pb"
"google.golang.org/grpc"
)
const (
port = ":50051"
)
type server struct{}
func (s *server) Search(ctx context.Context, in *pb.SearchRequest) (*pb.SearchReply, error) {
return &pb.SearchReply{Name:"hello " + in.GetName()}, nil
}
func (s *server) Search2(stream pb.Searcher_Search2Server) error {
for {
args, err := stream.Recv()
if err != nil {
if err == io.EOF {
return nil
}
return err
}
reply := &pb.SearchReply{ Name:"hello:" + args.GetName()}
err = stream.Send(reply)
if err != nil {
return err
}
}
return nil
}
func main() {
lis, err := net.Listen("tcp", port)
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
s := grpc.NewServer()
pb.RegisterSearcherServer(s, &server{})
s.Serve(lis)
}
为了方便阅读代码,client代码我们重写
package main
import (
"context"
"fmt"
"github.com/widaT/gorpc_demo/grpc/pb"
"google.golang.org/grpc"
"io"
"log"
"time"
)
const (
address = "localhost:50051"
)
func main() {
conn, err := grpc.Dial(address, grpc.WithInsecure())
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
c := pb.NewSearcherClient(conn)
stream, err := c.Search2(context.Background())
if err != nil {
log.Fatal(err)
}
go func() { //这边启动一个goroutine 发送请求
for {
if err := stream.Send(&pb.SearchRequest{Name: "world"}); err != nil {
log.Fatal(err)
}
time.Sleep(time.Second)
}
}()
for { //主goroutine 一直接收结果
rep, err := stream.Recv()
if err != nil {
if err == io.EOF {
break
}
log.Fatal(err)
}
fmt.Println(rep.GetName())
}
}
运行代码
$ go run server/main.go &
$ go run client/main.go
hello:world
hello:world
hello:world
...
总结
本文只是对golang使用grpc做了简要的介绍,grpc的使用范围很广,需要我们持续了解和学习。 下面推荐个资料
参考文档
docker
docker简介
docker是基于golang语言开发,基于linux kernel的cgroup和namespace,以及union Fs等技术对进程进行封装和隔离的轻量级容器。
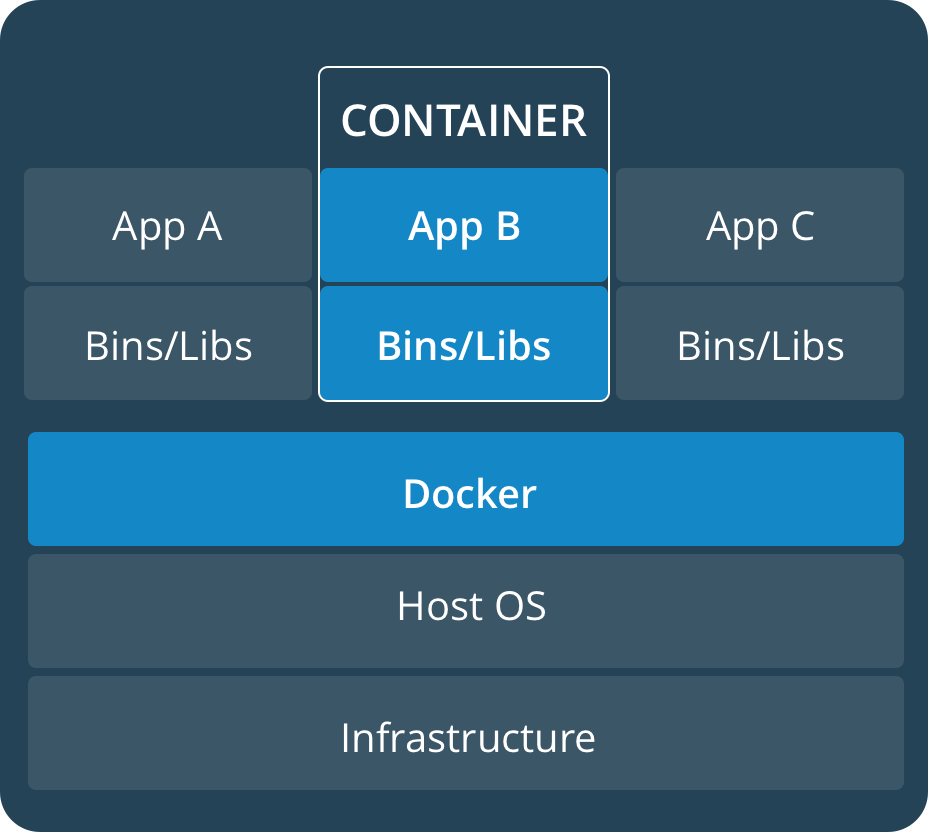
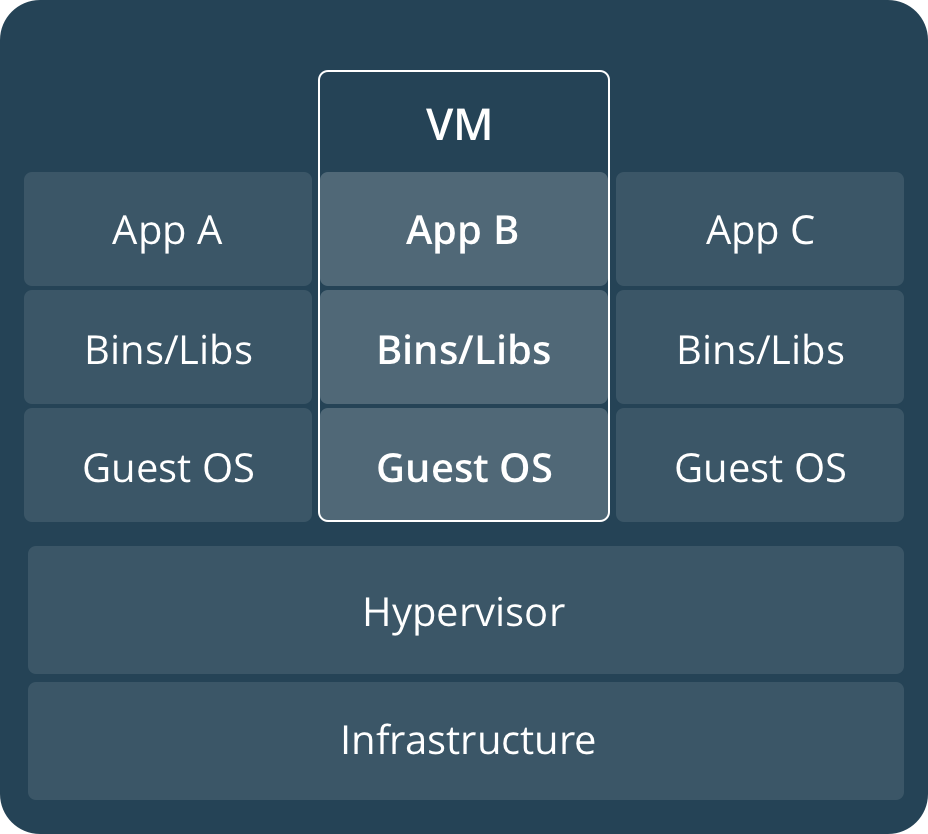
相比较传统的虚拟机(VM),docker和其他docker容器贡献宿主机内核,所以运行一个docker容器中的程序相当快。而VM则占用很多程序逻辑以外的开销。
总的说来docker有以下的特点:
- 灵活:即使最复杂的应用程序也可以容器化。
- 轻量级:容器利用并共享主机内核,在系统资源方面比虚拟机更有效。
- 可移植:您可以在本地构建,部署到云并在任何地方运行。
- 松散耦合:容器是高度自给自足并封装的容器,使您可以在不破坏其他容器的情况下更换或升级它们。
- 可扩展:您可以在数据中心内增加并自动分发容器副本。
- 安全:容器将积极的约束和隔离应用于流程,而无需用户方面的任何配置。
docker架构
docker采用经典的CS(客户端-服务器)架构。Docker客户端与Docker守护进程进行通讯,Docker守护进程完成了构建,运行和分发Docker容器的繁重工作。
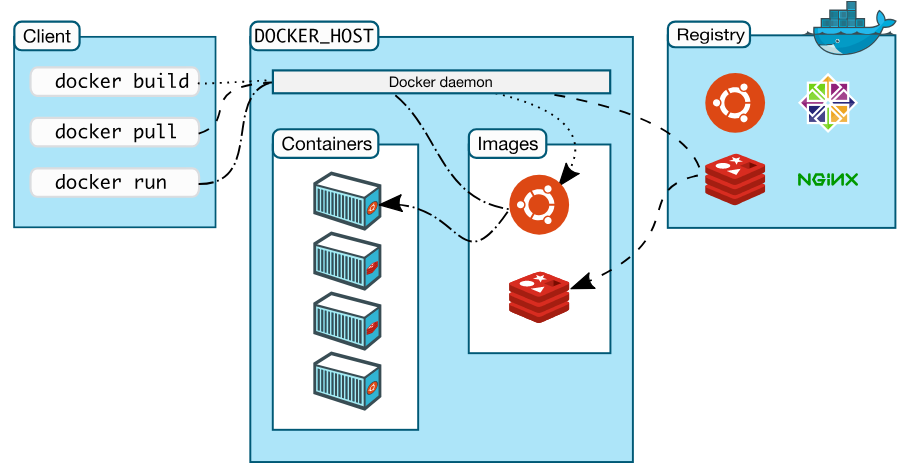
Docker守护进程
docker守护进程(dockerd)侦听docker API请求并管理docker对象,例如镜像,容器,网络和数据卷。docker守护进程还可以与其他docker守护进程组成集群。
Docker client
docker client(docker)是docker用户与docker交互的主要方式。使用诸如docker run等命令时,docker client会将这些命令发送到docker守护进程执行这些命令。Docker client还可以与多个docker守护进程通信。
Docker仓库
docker仓库存储Docker镜像。Docker Hub是任何人都可以使用的Docker仓库,默认情况下docker在Docker Hub上查找镜像。用户也可以运行自己的私人镜像
Docker对象
-
docker镜像
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源配置等文件外,还包含了一些为运行时准备的一些配置参数( 如匿名卷、环境变量、用户等) 。
-
docker容器
镜像( Image) 和容器( Container) 的关系,就像是面向对象程序设计中和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以创建、启动、停止、删除、暂停等。容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。
linux安装docker
使用一键安装命令
curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -
docker的使用
镜像管理
-
获取镜像
docker pull [OPTIONS] NAME[:TAG|@DIGEST]docker pull ubuntu:17.10从docker hub 现在镜像docker pull http://abc.com:/ubuntu:17.10从其他仓库地址现在镜像
-
镜像列表
docker images [OPTIONS] [REPOSITORY[:TAG]]docker images列出本地镜像,默认不显示中间镜像(intermediate image),列表包含了 仓库名 、 标签 、 镜像 ID 、 创建时间 以及 所占用的空间 。$ docker images micro-server v1.0 bf580c3b368f 7 weeks ago 28.3MB wordpress <none> 42a9bf5a6127 8 weeks ago 502MB #悬虚镜像docker image ls -f dangling=true查看所以悬虚镜像docker image prune删除悬虚镜像,悬虚镜像已经没有作用可以随意删除docker images -a列出本地所有的镜像$ docker images -a REPOSITORY TAG IMAGE ID CREATED SIZE grafana/grafana 6.0.1 ffd9c905f698 8 months ago 241MB <none> <none> f5690672aa36 12 months ago 133MB #中间层级镜像docker image ls -f过滤镜像docker image ls --format特定格式显示列表
-
删除镜像
docker rmi [OPTIONS] IMAGE [IMAGE...]docker rmi ffd9c905f698删除镜像docker image rm $(docker image ls -q redis)复合命令删除名字为redis的所有镜像
-
制作镜像
-
修改后的容器保存成镜像
docker commit --author "xxx<xxx@xxx.com>" --message "nginx" webserver nginx:v2这个方案很少用 -
使用Dockerfile定制镜像,这种方式比较主流
Dockerfile命令
- FROM 制定基础镜像,例如
FROM alpine:latest代表在alpine:latest基础镜像上构建新的镜像 - RUN 执行shell命令 例如
RUN apt-get update更新apt的源 - COPY 拷贝本地文件到镜像中
COPY cmd/server/server /拷贝server到根目录 - ADD 加强版的COPY,支持url文件拷贝
- CMD 用于指定容器主进程的启动命令
CMD ["./server"] - ENTRYPOINT 和CMD功能类似,稍微有点不同的是在运行容器的时候参数会附加到后面
- ENV 用于设置环境变量,容器很多运用都会通过读环境变量的方式来实现灵活配置,
ENV MYSQL_ROOT_PASSWORD=root - VOLUME 定义匿名卷,一般用于防止向容器写入大量数据。
- EXPOSE 声明容器运行时的服务端口,运行容器的时候不会真的绑定这个端口
- WORKDIR 指定工作路径,如果你的程序用的相对路径的配置文件的话,指定工作路径就能派上用场。
- USER 指定用户
FROM alpine:latest WORKDIR / COPY cmd/server/server / #EXPOSE 8000 CMD ["./server"] `` `docker build -t wida/micro-service:v1.0 .` 使用docker build 生产镜像 - FROM 制定基础镜像,例如
-
-
镜像仓库管理
docker tag SOURCE_IMAGE[:TAG] TARGET_IMAGE[:TAG]设置镜像标签docker tag 860c279d2fec wida/nginx:v1
docker push [OPTIONS] NAME[:TAG]向远程镜像仓库推送标签的镜像docker push wida/nginx:v1这边是往docker hub推送
容器管理
- 查看容器列表
docker ps [-a]不带-a的只列出正在运行的容器,带-a的列出所有容器 - 启动容器
- 新建启动
docker run ubuntu:14.04 /bin/echo 'Hello world'运行容器docker run -t -i ubuntu:14.04 /bin/bash交互运行容器,-t让Docker分配一个伪终端并绑定到容器的标准输入上, -i则让容器的标准输入保持打开。docker run -id -p 8000:80 --name webserver nginx:v2使用-d后台运行
- 启动停止的容器
docker start container
- 新建启动
- 停止容器
docker stop container - 进入容器
docker attach container不建议使用docker exec container
exp:docker exec -i -t nginx /bin/bash 让容器打开终端交互模式
- 删除容器
docker rm container删除制定容器,首先得stop容器docker container prune删除所有停止容器
Docker数据持久化
docker 容器内是不适合做数据存储的,通常我们会把数据存到容器外,主要有以下两种方式:
- 数据卷
docker volume create myvol创建数据卷docker run -id -v myvol:/data/app --name damov1 damo:v1挂载数据卷到容器/data/app
- 挂载主机目录
docker run -id -v /data/local/app:/data/app --name damov1 damo:v1挂载宿主机目录到容器目录/data/app
Docker网络
-
网络端口映射
-P是容器内部端口随机映射到主机的高端口。docker run -d -P --name damov1 damo:v1随机映射端口到容器的开放端口上
-p是容器内部端口绑定到指定的主机端口。docker run -id -p 8010:50051 --name damov1 damo:v1将容器的端口50051映射到宿主机8010上docker run -id -p 127.0.0.1::50051 --name damov1 damo:v1将容器50051映射到localhost的随机端口上docker run -id -p 8010:50051/udp --name damov1 damo:v1指定network类型,容器udp 50051端口映射到宿主机udp 8010端口。不写默认都是tcp。
-
容器互联 两个容器要互相通讯需要如下步骤
- 建立新的网络
docker network create -d bridge mynet - 运行容器1指定network
docker run -it --rm --name server1 --network mynet busybox sh - 运行容器2指定network和容器1相同
docker run -it --rm --name server2 --network mynet busybox sh
# ping server1 PING server1 (172.18.0.2): 56 data bytes 64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.167 ms 64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.151 ms - 建立新的网络
总结
本文只是介绍docker常用的一些命令,关于的docker的高级运用,建议大家看下docker官方的文档Docker Documentation。另外docker本身到的容器编排工具docker-swarm将在容器编排小节一块介绍。
参考资料
容器编排
什么是容器编排
容器编排是指容器的集群化管理和容器调度。常有的功能有启动容器,根据资源调动容器所在的位置,会跟踪和监控容器的状态,如果一个容器异常故障,编排系统会重启容器。在部署和更新容器时,如果出现问题,还可以回滚。常用的容器编排系统有Docker swarm 、Kuberbetes等。
Docker swarm简介
Docker swarm架构图
docker 节点(node)
-
manager节点维持集群状态,调动任务,集群服务。manager节点采用raft一致性协议,所以建议至少的2n+1,这个集群会通过raft选举出一位leader。
-
worker节点是真正执行docker容器的节点。manager节点本身也可以是worker节点,当然可以配置成不作为worker节点。worke之间的状态使用gossip分布式是一致性协议,gossip的特性是最终一致性和幂等性,相比于raft,gossip的时效性差一点,但是raft集群数(基于log的状态机复制)是有限制的。
任务(task), 服务(service),容器
例如上图,我们定义了一个http server服务,我们在三个http服务三个实例之间实现负载平衡。上图图显示了具有三个副本的http服务,这三个实例中的每个实例都是集群中的任务。容器是一个孤立的进程。在群体模式模型中,每个任务仅调用一个容器。容器处于活动状态后,调度程序将识别出该任务处于运行状态。
Docker swarm使用
-
初始化集群
#manager docker swarm init -advertise-addr 192.168.99.100 #worker docker swarm join --token XXXX #查看集群 docker node ls $ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION itbo6pz5lm94vg21huw22lyxn * ulucu-develop-008.int.uops.cn Ready Active Leader 18.06.1-ce h3gvgyslfg0pxpu5l57s5pn56 wida Ready Active 18.03.1-ce -
新建服务
#分布式运用部署 #swarm 下面的overlay 网络创建 docker network create -d overlay demo #在使用后才可以在node节点可见 docker service create --name mysql --env MYSQL_ROOT_PASSWORD=root --env MYSQL_DATABASE=wordpress --network=demo --mount type=volume,source=mysql-data,destination=/var/lib/mysql mysql:5.7 docker service create --name wordpress -p 80:80 --network=demo --replicas 3 --env WORDPRESS_DB_PASSWORD=root --env WORDPRESS_DB_HOST=mysql wordpress #查看service 列表 docker service ls #查看某个服务的容器分布情况 docker service ps wordpress #来查看某个服务的日志 docker service logs wordpress -
更新服务
#service服务伸缩 docker service scale wordpress=5 #拓展到5台 #service 无中断更新 docker service update --image=xxx:2.0 wordpress #service 更新端口 docker service update --public-rm 8080:80 --public-add 8088:80 wordpress -
删除服务
docker service rm wordpress -
使用docker stack 我们用一个配置文件描述一组服务,然后docker stack 相关命令管理管理这一组服务。
我们创建问文件docker-compose.yaml
version: "3" services: wordpress: image: wordpress ports: - 80:80 networks: - overlay environment: WORDPRESS_DB_HOST: db:3306 WORDPRESS_DB_USER: wordpress WORDPRESS_DB_PASSWORD: wordpressdocker stack replicas: 3 db: image: mysql command: --default-authentication-plugin=mysql_native_password networks: - overlay volumes: - db-data:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: somewordpress MYSQL_DATABASE: wordpress MYSQL_USER: wordpress MYSQL_PASSWORD: wordpress deploy: placement: constraints: [node.role == manager] visualizer: image: dockersamples/visualizer:stable ports: - "8080:8080" stop_grace_period: 1m30s volumes: - "/var/run/docker.sock:/var/run/docker.sock" deploy: placement: constraints: [node.role == manager] volumes: db-data: networks: overlay:stack 管理
#部署服务 docker stack deploy -c docker-compose.yml wordpress #查看stack docker stack ls #docer stack 更新 修改docker-compose.yaml文件 然后直接docker stack deploy -c docker-compose.yaml wordpress #删除stack docker stack down wordpress
Kuberbetes简介
coming soon
Kuberbetes使用
coming soon
参考资料
go-micro微服务框架
go-micro简介
Go Micro是可插拔的微服务开发框架。micro的设计哲学是可插拔的架构理念,她提供可快速构建系统的组件,并且可以根据自身的需求剥离默认实现并自行定制。详细的介绍可参考官方中文文档Go Micro,目前go micro这个项目最新版本为v3。
安装go-micro依赖
- 安装protobuf 参考grcp和protobuf 中protobuf的安装方式
- 安装protoc-gen-micro,这个是go-micro定制的protobuf插件,用于生成go-micro定制的类似grpc的代码。
go get github.com/micro/protoc-gen-micro
写一个微服务版本的hello world程序
这个程序包含一个service,web,cli:
- service作为微服务的具体体现,他的功能是提供某一类服务,我们这边的稍作简化,只提供一个grpc服务。在实际场景中service是某一类服务接口的集合,接口数量不宜太多,得考虑负载情况和业务情况相结合做适当的拆分整合。
- web作为前端应用,对外提供http服务。在实践场景中web通常会整合各种后端service包装成业务接口提供给终端或者第三方合作伙伴使用。
- cli也是前端应用的另一种形式,不对外提供http服务,可以在命令行下的脚本任务或者某些守护进程。
跟grpc一样我们先编写proto文件,定义service
syntax = "proto3";
option go_package = "../proto";
service Say {
rpc Hello(Request) returns (SayResponse) {}
}
message Request {
string name = 1;
}
message Pair {
int32 key = 1;
string values = 2;
}
message SayResponse {
string msg = 1;
// 数组
repeated string values = 2;
// map
map<string, Pair> header = 3;
RespType type = 4;
}
enum RespType {
NONE = 0;
ASCEND = 1;
DESCEND = 2;
}
我们写一个shell脚本来生成golang源码文件
#!/bin/bash
protoc --go_out=. --micro_out=. test.proto
目录结构
$ tree
.
├── cli.Dockerfile
├── cmd
│ ├── cli
│ │ └── main.go
│ ├── service
│ │ └── main.go
│ └── web
│ └── main.go
├── docker-compose.yml
├── go.mod
├── go.sum
├── Makefile
├── proto
│ ├── gen.sh
│ ├── test.pb.go
│ ├── test.pb.micro.go
│ └── test.proto
├── README.md
├── service.Dockerfile
└── web.Dockerfile
编写service
注意go-micro这边使用了默认的mdns来做服务发现,mdns的相关原理可参考Multicast_DNS
package main
import (
"context"
"log"
hello "mircotest/proto"
"os"
"github.com/asim/go-micro/v3"
)
type Hello struct{}
func (s *Hello) Hello(ctx context.Context, req *hello.Request, rsp *hello.SayResponse) error {
log.Print("Received Say.Hello request")
hostname, _ := os.Hostname()
rsp.Msg = "Hello " + req.Name + " ,Im " + hostname
rsp.Header = make(map[string]*hello.Pair)
rsp.Header["name"] = &hello.Pair{Key: 1, Values: "abc"}
return nil
}
func main() {
service := micro.NewService(
micro.Name("wida.micro.srv.greeter"),
)
service.Init()
// Register Handlers
hello.RegisterSayHandler(service.Server(), new(Hello))
// Run server
if err := service.Run(); err != nil {
log.Fatal(err)
}
}
编写web
package main
import (
"context"
"fmt"
"log"
hello "mircotest/proto"
"net/http"
"github.com/asim/go-micro/v3/client"
"github.com/asim/go-micro/v3/web"
)
func main() {
service := web.NewService(
web.Name("wida.micro.web.greeter"),
web.Address(":8009"),
)
service.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
if r.Method == "POST" {
r.ParseForm()
name := r.Form.Get("name")
if len(name) == 0 {
name = "World"
}
cl := hello.NewSayService("wida.micro.srv.greeter", client.DefaultClient)
rsp, err := cl.Hello(context.Background(), &hello.Request{
Name: name,
})
if err != nil {
http.Error(w, err.Error(), 500)
return
}
w.Write([]byte(`<html><body><h1>` + rsp.Msg + `</h1></body></html>`))
return
}
fmt.Fprint(w, `<html><body><h1>Enter Name<h1><form method=post><input name=name type=text /></form></body></html>`)
})
if err := service.Init(); err != nil {
log.Fatal(err)
}
if err := service.Run(); err != nil {
log.Fatal(err)
}
}
编写cli
package main
import (
"context"
"fmt"
hello "mircotest/proto"
roundrobin "github.com/asim/go-micro/plugins/wrapper/select/roundrobin/v3"
"github.com/asim/go-micro/v3"
)
func main() {
wrapper := roundrobin.NewClientWrapper()
service := micro.NewService(
micro.WrapClient(wrapper),
)
service.Init()
cl := hello.NewSayService("wida.micro.srv.greeter", service.Client())
rsp, err := cl.Hello(context.Background(), &hello.Request{
Name: "John",
})
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("%s \n", rsp.Msg)
}
编写Makefile简化编译过程
export GOCMD=GO111MODULE=on CGO_ENABLED=0 go
GOINSTALL=$(GOCMD) install
GOBUILD=$(GOCMD) build
GORUN=$(GOCMD) run
GOCLEAN=$(GOCMD) clean
GOTEST=$(GOCMD) test
GOGET=$(GOCMD) get
GOFMT=$(GOCMD) fmt
all : service web cli
service :
@echo "build service"
@mkdir -p build
$(GOBUILD) -a -installsuffix cgo -ldflags '-w' -o build/service cmd/service/*.go
web :
@echo "build web"
$(GOBUILD) -a -installsuffix cgo -ldflags '-w' -o build/web cmd/web/*.go
cli :
@echo "build cli"
$(GOBUILD) -a -installsuffix cgo -ldflags '-w' -o build/cli cmd/cli/*.go
docker:
@echo "build docker images"
docker-compose up --build
.PHONY: clean
clean:
@rm -rf build/
.PHONY: proto
proto:
protoc --go_out=. --micro_out=. test.proto
这边需要注意我们编译golang的时候使用了CGO_ENABLED=0 go build -a -installsuffix cgo -ldflags '-w' -o 这样的编译参数是为了去掉编译后的golang可执行文件对cgo的依赖,我们的程序要放在alpine:latest容器中,如果依赖cgo则运行不起来。
$ make
build service
GO111MODULE=on CGO_ENABLED=0 go build -a -installsuffix cgo -ldflags '-w' -o build/service cmd/service/*.go
build web
GO111MODULE=on CGO_ENABLED=0 go build -a -installsuffix cgo -ldflags '-w' -o build/web cmd/web/*.go
build cli
GO111MODULE=on CGO_ENABLED=0 go build -a -installsuffix cgo -ldflags '-w' -o build/cli cmd/cli/*.go
$ tree
.
├── build
│ ├── cli
│ ├── service
│ └── web
├── cli.Dockerfile
├── cmd
│ ├── cli
│ │ └── main.go
│ ├── service
│ │ └── main.go
│ └── web
│ └── main.go
├── docker-compose.yml
├── go.mod
├── go.sum
├── Makefile
├── proto
│ ├── gen.sh
│ ├── test.pb.go
│ ├── test.pb.micro.go
│ └── test.proto
├── README.md
├── service.Dockerfile
└── web.Dockerfile
微服务运行环境
一般情况下微服务是运行在容器中的,容器化部署会带来很大的运维管理便利性。但是容器化运行不是必选项,通常我们在开发调试的时候我们选择可以物理机运行。等程序运行稳定后,我们才打包成docker镜像。
物理机运行微服务
$ cd build/
$ ./service #运行service
2019/11/11 15:04:48 Transport [http] Listening on [::]:45645
2019/11/11 15:04:48 Broker [http] Connected to [::]:41175
2019/11/11 15:04:48 Registry [mdns] Registering node: wida.micro.srv.greeter-ffb7abee-f8e2-43fe-a238-8f8348172dae
2019/11/11 15:07:59 Received Say.Hello request
$ ./cli #运行cli
&com_hello.SayResponse{Msg:"HelloJohn ,Im wida", Values:[]string(nil), Header:map[string]*com_hello.Pair{"name":(*com_hello.Pair)(0xc0002c0200)}, Type:0, XXX_NoUnkeyedLiteral:struct {}{}, XXX_unrecognized:[]uint8(nil), XXX_sizecache:0}
$ ./web
2019/11/11 15:09:54 Listening on [::]:8009
$ curl -d"name=wida" localhost:8009 #这边简化web请求采用curl,同样可以打开浏览器 from表单提交
<html><body><h1>Hello wida ,Im wida</h1></body></html>
容器化运行服务
编写Dockfile
分别编写三个dockerfile
FROM alpine:latest
WORKDIR /
COPY build/cli /
CMD ["./cli"]
编写docker-composer.yml
version: "3"
services:
etcd:
command: --listen-client-urls http://0.0.0.0:2379 --advertise-client-urls http://0.0.0.0:2379
image: appcelerator/etcd:latest
ports:
- "2379:2379"
networks:
- overlay
server:
command: ./service --registry=etcd --registry_address=etcd:2379 --register_interval=5 --register_ttl=10
build:
dockerfile: ./service.Dockerfile
context: .
image: wida/micro-service:v1.0
networks:
- overlay
depends_on:
- etcd
deploy:
mode: replicated
replicas: 2
web:
command: ./web --registry=etcd --registry_address=etcd:2379 --register_interval=5 --register_ttl=10
image: wida/micro-web:v1.0
build:
dockerfile: ./web.Dockerfile
context: .
networks:
- overlay
depends_on:
- etcd
ports:
- "8009:8009"
networks:
overlay:
这个时候我们我们采用了etcd做服务发现。etcd相关文档请查看官方文档
docker-compose 部署服务
$ make docker
$ curl -d "name=wida" http://127.0.0.1:8009 ## 看服务都完全部署完毕后执行
<html><body><h1>Hello 111 wida ,Im 7247ec528ca4</h1></body></html>
在Kuberbetes中运行
coming soon
总结
本小节简要的介绍了go-micro的使用,go-micro实践的生态也比较庞大,代码也写的很优雅是一个不错的代码研究学习对象。更多关于go-micro的情况可以看github源码和参考资料中的文档。
本小节代码
参考资料
go runtime简介
有别于java和c#的runtime是一个虚拟机,go的runtime和我们的go代码一同编译成二进制可执行文件。
go的runtime负责:
- goroutine的调度
- go内存分配
- 垃圾回收(GC)
- 封装了操作系统底层操作,如syscall,原子操作,CGO
- map,channel,slice,string内置类型的实现
- 反射(reflection)的实现
- pprof,trace,race的实现
本小节将依次介绍
- map底层实现
- channel的底层实现
- goroutine调度器
- go 内存分配器
- go 垃圾会收器
go map
map结构是一种高频使用的数据结构,go的map是采用链表法(解决hash冲突的时候,落在相同hash结果的bucket采用链表连接)的hash table。
go map的源码的目录为go/src/runtime/map.go。本文基于go1.13的版本。map的底层数据结构其实是hmap的指针。
hmap结构体如下:
type hmap struct {
count int // map的大小,len(map)返回的值
flags uint8 //状态flag 值有 1,2,4,8
B uint8 // bucket数量的对数值 例如B为5 则表明有2^5(32)个桶
noverflow uint16 // 溢出桶(overflow buckets)的大概数量
hash0 uint32 // hash seed
buckets unsafe.Pointer // 桶数组的指针,如果len为0,则指针为nil.
oldbuckets unsafe.Pointer // 在扩容的时候这个指针不为nil
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // 当key和value都可内嵌的时候会用到这个字段
}
bucket的定义原始定义是:
type bmap struct {
tophash [bucketCnt]uint8
}
当时在实际编译后会变成如下结构:
type bmap struct {
tophash [8]uint8 //存储hash值的高8位(1个uint8)数组,
keys [8]keysize
values [8]keysize
overflow uintptr
}
bmap实际上就是一个hashmap的一个桶,这个桶为存储8个key-value。
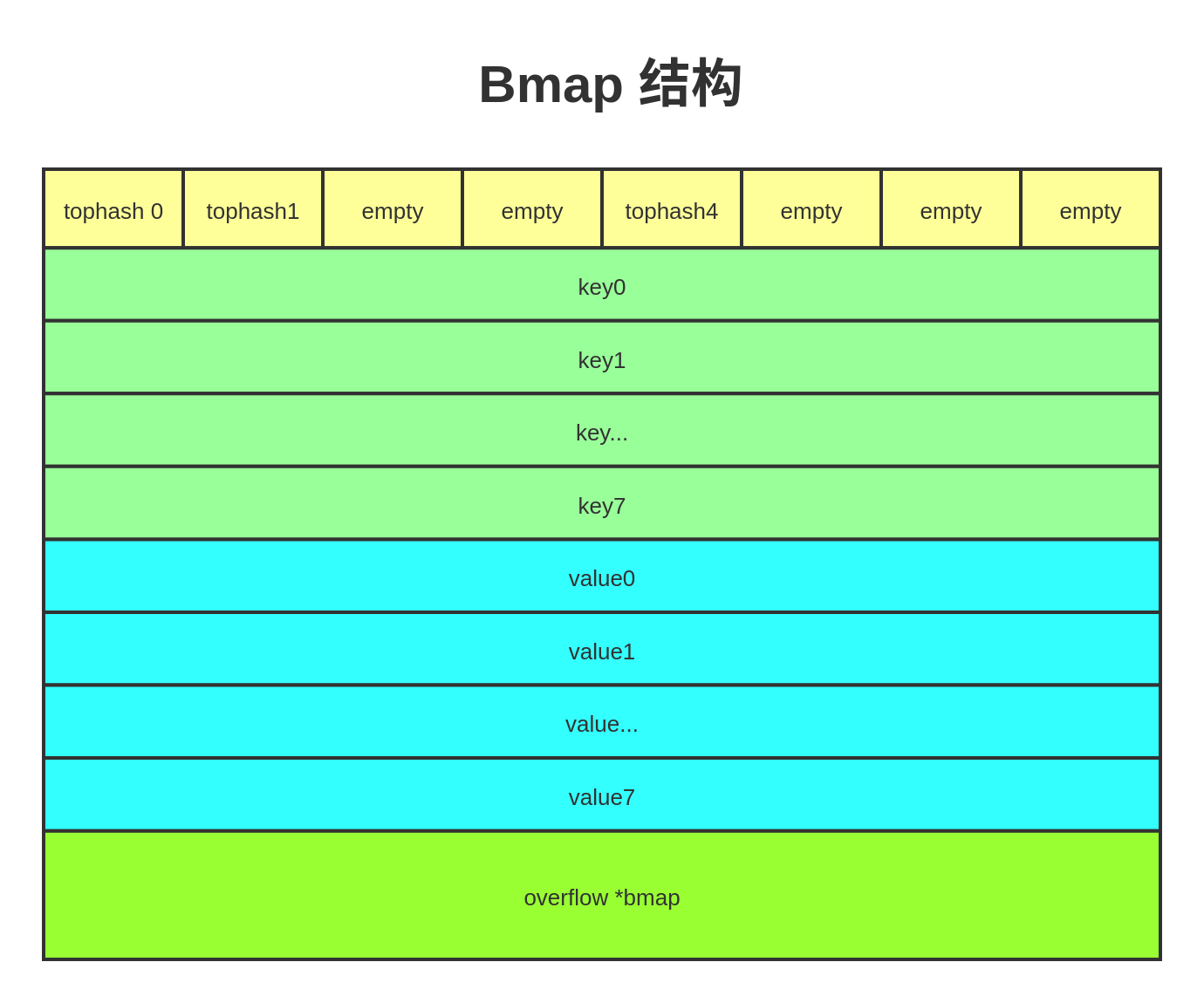
如上图所示,tophash一遍情况下是从零值往后塞,如果被删除了在会边empty,如果8个位置放不下了则会再创建一个bmap由 voerflow指针指向。 还要就是key-value的存储方式是,key放在一起,value放在一起,而不是key-value这种组合存储的,目的是为了节省空间减少内存空洞。
到这边我们可以知道hmap和bmap整个的关系图如下;
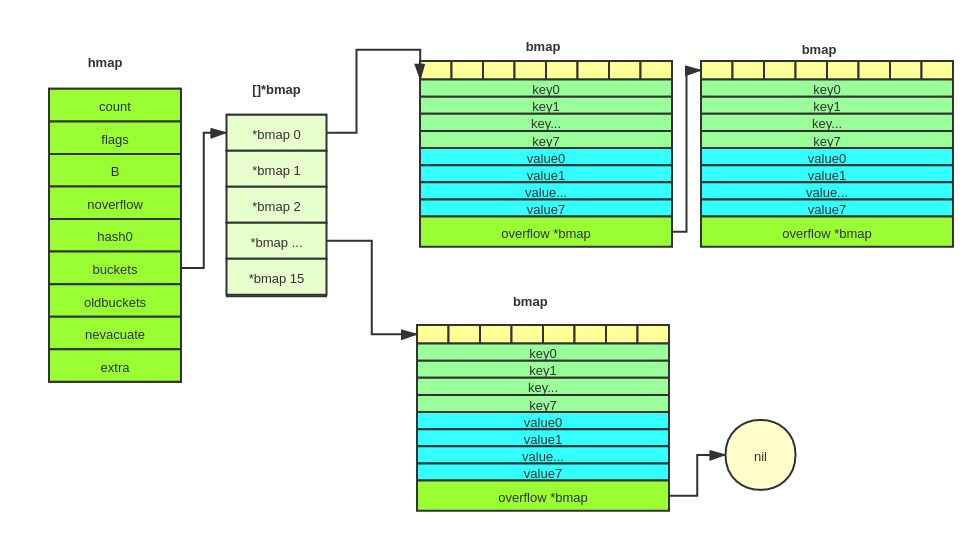
上图展示了B为4时候的hmap结果示意图。
make map的过程
map的make会根据参数编译成不同版本.
当 make(map[k]v)不带参数或者make(map[k]v,int)在编译期知道最大bucket数量同时这个map必须在堆上分配的时候会用 makemap_small 函数
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
另外一个函数叫makemap
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
//计算B的值
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
//初始化 bucket
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
访问map元素
假设B=4它将创建2^4即16个桶,一个key通过hash函数计算会得到一个int64的值如下, 00000101 | 0000110111101100100011100000001000100101100100000100 | 0010 我们看到后四位 是0010 也就是2,那么他将落在第二个桶,高8为的值是5,它在整个hmap的位置如下:
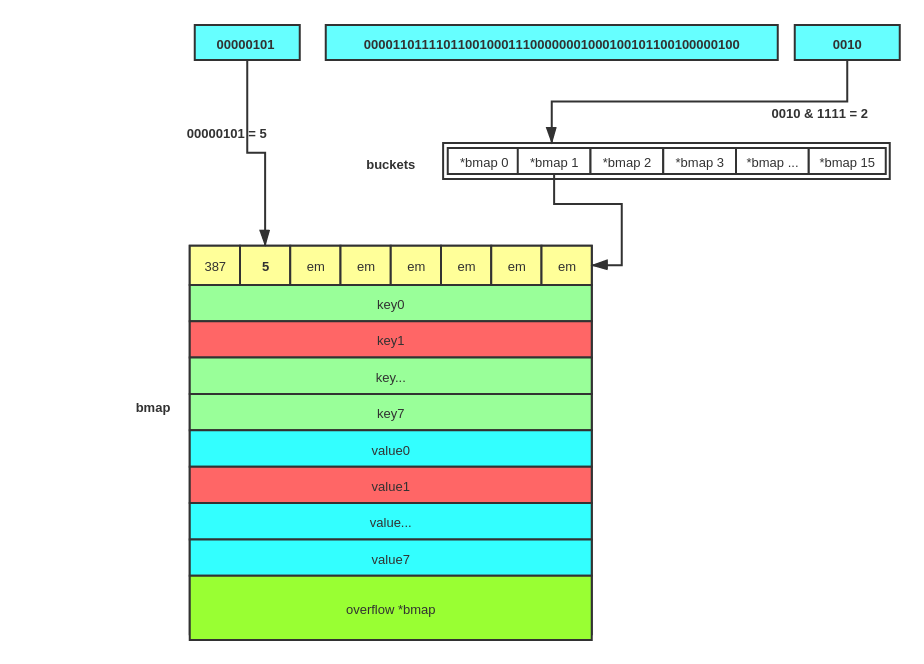
在runtime里头map的索引函数有好多个,主要是因为key的大小和类型不同区分了好多个mapaccess。我们调休
mapaccess2来看下其他几个大同小异。
mapaccess2对应的是 go代码中a,found = map[key]写法。
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess2)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.key.alg.hash(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0]), false
}
//这个地方就是并发读写检测的地方
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
alg := t.key.alg
//不同类型的key,用的 hash算法不一样
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
//定位bmap的位置
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
//发生扩容的场景
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
//这个地方就是上图中取前8为的地方
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//定位key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//判断key和k是不是一样
if alg.equal(key, k) {
//定位value位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e, true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}
为key赋值
跟mapaccess类似,赋值操作也根据key的类型有多个,我们看其中的mapassign
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled {
msanread(key, t.key.size)
}
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
//改变flag为写入
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
//计算bucket位置
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
//tophash 高8位
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
//这边会遍历8个位置
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
//这个位置没有被占,可以被插入
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !alg.equal(key, k) {
continue
}
// 如何key已经存在,则更新value
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
//8个位置满了,这需要进入overflow流程
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
//flag 置成非写入
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
mapassign 并没有真正做赋值,仅仅返回值的位置,赋值的操作在汇编代码中。
删除key
删除key对应的函数是mapdelete
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapdelete)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.key.alg.hash(key, 0) // see issue 23734
}
return
}
//并发读写冲突检测
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
//将flag设置为写操作
h.flags ^= hashWriting
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !alg.equal(key, k2) {
continue
}
// 如果key是指针则清除指向的内容
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
memclrHasPointers(k, t.key.size)
}
//计算value的位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
//如果value是指针则清除指向的内容
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
// 设置 tophash[i]的位置置空
b.tophash[i] = emptyOne
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for {
// 设置 tophash[i]的位置置空
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
notLast:
//len 减少
h.count--
break search
}
}
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
//清除置成非写入flag
h.flags &^= hashWriting
}
总结
map的几个特点:
- go的map是非线程安全的,在并发读写的时候会触发
concurrent map read and map write的panic。 - map的key不是有序的,所以在for range的时候经常看到map的key不是稳定排序的。
- map在删除某个key的时候不是真正的删除,只是标记为空,空间还在,所以在for range删除map元素是安全的。
参考资料
go channal是如何实现的
我们先通过golang汇编追踪下 make(chan,int)到底做了什么。
package main
import "fmt"
func main() {
ch := make(chan int,1)
go func() {
for {
ch <-1
}
}()
ret := <- ch
fmt.Println(ret)
}
go build --gcflags="-S" main.go
看到如下这段go汇编代码
LEAQ type.chan int(SB), AX //获取type.chan int 类型指针
MOVQ AX, (SP) //压栈 make的第一个参数
MOVQ $1, 8(SP) //压栈 make的第一个参数
CALL runtime.makechan(SB) //实际调用 runtime.makechan函数
那么ch := make(chan int,1) 其实是调用 runtime.makechan的方法,
go 1.13 源码
func makechan(t *chantype, size int) *hchan {
elem := t.elem
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0:
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
c = new(hchan)
c.buf = mallocgc(mem, elemblockevent, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}
返回的类型是*hchan。所以chan是一个指针类型,这样子chan在各个goroutine的传递 都是直接传chan,传递chan 指针。
我看从go源码的(src/runtime/chan.go)看到的hchan struct
type hchan struct {
qcount uint // 当前使用的个数
dataqsiz uint // 缓冲区大小 make的第二个参数
buf unsafe.Pointer // 缓存数组的指针,带缓冲区的chan指向缓冲区,无缓存的channel指向自己指针(仅做数据竞争分析使用)
elemsize uint16 // 元素size
closed uint32 //是否已经关闭 1已经关闭 0还没关闭
elemtype *_type // 元素类型
sendx uint // 发送的索引 比如缓冲区大小为3 这个索引 经历 0-1-2 然后再从0开始
recvx uint // 接收的索引
recvq waitq // 等待recv的goroutine链表
sendq waitq // 等待send的goroutine链表
lock mutex //互斥锁
}
ret := <- ch 这个语句对于汇编是
LEAQ ""..autotmp_12+64(SP), CX
MOVQ CX, 8(SP)
CALL runtime.chanrecv2(SB)
我们看到源码中用 chanrecv1 和 chanrecv2 两个函数:
// entry points for <- c from compiled code
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
我们这边对应的是 chanrecv2, 那么什么时候是chanrecv1?什么时候是chanrecv2呢?
当 <- ch chan左边没有接收值的时候使用的是 chanrecv1,当左边有接收值的时候是chanrecv2,注意 chan 的接收值有两个
ret := <- ch
//带bool值
ret,ok := <- ch
这两个都是使用chanrecv2。
ch <-1对应的汇编是
LEAQ ""..stmp_0(SB), CX
MOVQ CX, 8(SP)
CALL runtime.chansend1(SB)
这边可以看到实际上是调用runtime.chansend1 源码如下
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
实现上是调用runtime.chansend
获取chan的关闭状态
通过什么的一些源码阅读我们来实现下chan关闭状态的获取。
package main
import (
"fmt"
"unsafe"
)
func main() {
c := make(chan int, 10)
fmt.Println(isClosed(&c))
close(c)
fmt.Println(isClosed(&c))
}
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
}
func isClosed(c *chan int) uint32 {
a := unsafe.Pointer(c)
d := (**hchan)(a)
return (*d).closed
}
# go run main.go
0
1
参考文档
深度解密Go语言之channel understanding channels
go的调度器
GMP调度模型
- G表示Goroutine;
- M表示一个操作系统的线程;
- P表示一个CPU处理器,通常P的数量等于CPU核数(GOMAXPROCS)。
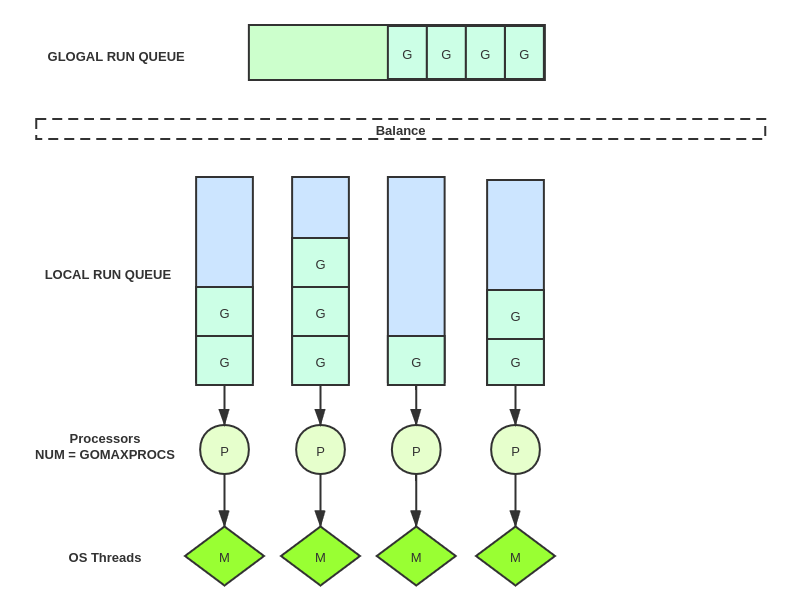
如上图所示
- 全局队列的作用是负载均衡(Balance)。
- M需要和P绑定后不停的执行G的任务。
- P本地有个任务队列,可以无锁状态下执行高效操作。当本地队列为空时会尝试去全局队列去获取G,如果全局队列也为空,这个时候从其他有G的P哪里偷取一半G过来,放到自己的P本地队列。
- M和P并不一定是一一对应的,通常P数量是等于GOMAXPROCS,M的数量则由调度器的监控线程决定的。
我们再看下《Go 1.5 源码剖析 》中的示意图
+-------------------- sysmon ---------------//-------+
| |
| |
+---+ +---+-------+ +--------+ +---+---+
go func() ---> | G | ---> | P | local | <=== balance ===> | global | <--//--- | P | M |
+---+ +---+-------+ +--------+ +---+---+
| | |
| +---+ | |
+----> | M | <--- findrunnable ---+--- steal <--//--+
+---+
| 1. 语句go func() 创建G
| 2. 放入P本地队列或者平衡到全局队列
+--- execute <----- schedule 3. 唤醒或者新建M执行任务
| | 4. 进入调度循环 schedul
| | 5. 竭力获取待执行 G 任务并执行
+--> G.fn --> goexit ----+ 6. 清理现场,重新进入调度循环
M 通过修改寄存器,将执⾏栈指向 G ⾃带栈内存,并在此空间内分配堆栈帧,执⾏任务函数。
当需要中途切换时,只要将相关寄存器值保存回 G 空间即可维持状态,任何 M 都可据此恢复执⾏。
线程仅负责执⾏,不再持有状态,这是并发任务跨线程调度,实现多路复⽤的根本所在。
调试调度器
调试go调度器,我们有专门的小节来介绍GODEBUG追踪调度器
参考资料
go内存分配器(未完)
go的垃圾回收器
参考资料
cgo简介
什么是cgo
在某些场景下go很可能需要调动c函数,比如调用系统底层驱动。c在过去几十年的积累了非常多优秀的lib库,所以很多编程语言都会选择跨语言调用c,这项技术被称为foreign-function interfaces (简称ffi)。go和c语言有相当深的颜渊,go当然不会拒绝继承c语言的这些财产,于是便有了cgo。
cgo是golang自带的go和c互相调用的工具。注意go不仅仅可以调用c,而且还可以让c调用go。
cgo is not go
任何技术都不是完美的,虽然go可以通过cgo的方式使用c语言的很多优秀的lib库,但是cgo的使用并不是没有代价的,在某些场景下代价还挺大。cgo is not go这个文章详细描述了cgo不是很让人满意的地方。
总的来说有如下几点:
- cgo让构建go程序变得复杂,必须安装c语言相关工具链
- cgo不支持交叉编译
- cgo无法使用go语言很多工具,像pprof
- 用了cgo后部署变得更加复杂。c语言很多依赖动态链接库,go语言原先只编成一个二进制可执行文件,现在这种局面被打破。
- cgo代理额外的性能损耗。cgo中go的堆栈和c语言堆栈是分开的,go调用c语言函数通常需要申请额外的堆内存进行数据拷贝。
cgo作用大,但是非必要条件不要使用cgo。
cgo hello world
package main
/*
#include <stdio.h>
#include <stdlib.h> //C.free 依赖这个头文件
void myprint(char* s) {
printf("%s\n", s);
}
*/
import "C"
import "unsafe"
func main() {
cs := C.CString("Hello from stdio\n")
C.myprint(cs)
C.free(unsafe.Pointer(cs))
}
$ go run main.go
Hello from stdio
参考资料
cgo入门
开启cgo
要使用cgo需要先导入伪Package C,
// #include <stdio.h> //这边的特殊注释属于c语言的代码
// #include <errno.h>
import "C" //这边需要注意 上面不能有空行,而且这行不能和其他import同行
当然还可以换一种注释
/*
#include <stdio.h>
#include <errno.h>
*/
import "C"
import C上面注释里头可以写c语言的代码
/*
#include <stdio.h>
#include <errno.h>
void sayHello() {
printf("hello");
}
*/
import "C"
可以引入自定义的头文件
$ tree
.
├── go.mod
├── main.go
├── myhead.h
└── say.c
myhead.h内容
#include<stdio.h>
#include<stdlib.h>
int sayHello(void * a, const char* b);
say.c内容
#include "myhead.h"
int sayHello(void *a, const char* b){
return sprintf((char *)a,b);
}
main.go 内容
package main
/*
#include "myhead.h"
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
b := make([]byte,20)
bb := C.CBytes(b) //会拷贝内存
char :=C.CString("Hello, World") //会拷贝内存
defer func() { //这边需要手动释放堆内存
C.free(unsafe.Pointer(char))
C.free(bb)
}()
l := C.sayHello(bb,char)
fmt.Println(string(C.GoBytes(bb,l)))
}
编译的时候go编译器会自动扫描源码目录下c语言的源码文件
$ go build #和正常程序编译没有区别
$ tree
.
├── cdo-demo #这个是编译后的程序
├── go.mod
├── main.go
├── myhead.h
└── say.c
$ ./cdo-demo
Hello, World
cgo的编译链接参数
cgo的编译链接参数通过在注释中使用 #cgo伪命令实现。#cgo命令定义CFLAGS,CPPFLAGS,CXXFLAGS,FFLAGS和LDFLAGS,以调整C,C ++或Fortran编译器的行为。多个指令中定义的值被串联在一起。同时#cgo可以包括一系列构建约束,这些约束将其作用限制在满足其中一个约束的系统上。
// #cgo CFLAGS:-DPNG_DEBUG = 1 #宏定义及赋值
// #cgo amd64 386 CFLAGS:-DX86 = 1 #这边包含了系统约束 (adm64或者386)
// #cgo LDFLAGS:-lpng
// #include <png.h>
import“ C”
另外,CPPFLAGS和LDFLAGS可以通过pkg-config工具使用#cgo pkg-config:指令后跟软件包名称来获得。例如:
// #cgo pkg-config: png cairo
// #include <png.h>
import "C
在程序构建时:
- 程序包中的所有CPPFLAGS和CFLAGS伪指令被串联在一起,并用于编译该软件包中的C文件。
- 程序包中的所有CPPFLAGS和CXXFLAGS伪指令被串联在一起,并用于编译该程序包中的C++文件。
- 程序包中的所有CPPFLAGS和FFLAGS指令都已连接在一起,并用于编译该程序包中的Fortran文件。
- 程序中任何程序包中的所有LDFLAGS伪指令在链接时被串联并使用。
- 所有pkg-config伪指令被串联并同时发送到pkg-config,以添加到适当的编译链接参数。
#cgo伪命令中包含${SRCDIR}标志的将被展开成源文件的目录的绝对路径。
// #cgo LDFLAGS: -L${SRCDIR}/libs -lfoo
上面的代码在将被展开为:
// #cgo LDFLAGS: -L/go/src/foo/libs -lfoo
类型转换
数组类型转换
数值类型对应表
| c | cgo |
|---|---|
| signed char | C.char |
| unsigned char | C.uchar |
| unsigned short | C.short |
| unsigned int | C.int |
| unsigned long | C.long |
| long long | C.longlong |
| unsigned long long | C.ulonglong |
| float | C.float |
| double | C.double |
结构体,联合体,枚举类型转换
cgo使用C.struct_xxx 访问c语言中的结构体,例如c语言中结构体为struct S cgo返回为C.struct_S。
cgo使用C.union_xxx 访问c语言中的联合体,注意的是cgo没办法访问联合体内的字段,C.union_xxx会变成字节数组。
cgo使用C.enum_xxx访问c语言枚举类型。
package main
/*
struct S {
int i;
float type;yuy
union U {
int i;
float f;
};
enum E {
A,
B,
};
*/
import "C"
import (
"encoding/binary"
"fmt"
"unsafe"
)
func main() {
var a C.struct_S
a.i =10
a._type =10.0
fmt.Println(a.i)
fmt.Println(a._type)
var b C.union_U //联合体转成了[4]byte
binary.LittleEndian.PutUint32(b[:],9) //写入i的值
fmt.Printf("%T\n", b) // [4]uint8
fmt.Println(*(*C.int)(unsafe.Pointer(&b)) )
var c C.enum_E = C.B
fmt.Println(c)
}
$ go run main.go
10
10
[4]uint8
9
1
字符串和字节数组
go string转 char * ,[]byte 转 void *(unsafe.Pointer)
func C.CString(string) *C.char
func C.CBytes([]byte) unsafe.Pointer
这几个转换都有额外的内存耗损,使用完记得C.free释放内存。
char * 转go string,void *(unsafe.Pointer)转[]byte
func C.GoString(*C.char) string
func C.GoStringN(*C.char, C.int) string
func C.GoBytes(unsafe.Pointer, C.int) []byte
需要注意的是c语言的string是以'\0'结尾的char数组表示,而go的string底层数据是
type StringHeader struct {
Data uintptr
Len int
}
StringHeader中的Data指向的数据末尾是不带'\0'的。
cgo中c函数返回值
c语言是不支持多个返回值的,cgo调用c函数会有两个返回值(即使c函数原本返回void)。第二个返回值为
#include <errno.h>中的errno变量对应的错误描述,errno是一个全局变量,用于返回最近一次调用错误结果。
package main
/*
#cgo LDFLAGS:-lm
#include <math.h>
#include <errno.h>
int div(int a, int b) {
if(b == 0) {
errno = EINVAL;
return 0;
}
return a/b;
}
void voidFunc() {}
*/
import "C"
import "fmt"
func main() {
_, err := C.sqrt(-1) //参数错误
fmt.Println(err)
n,err := C.sqrt(4)
fmt.Println(n,err)
_,err = C.voidFunc() //函数返回void
fmt.Println(err)
d,err :=C.div(4,0) //除数不能为0
fmt.Println(d,err)
}
$ go run main.go
numerical argument out of domain
2 <nil>
<nil>
0 invalid argument
go导出函数给c使用
就像在本章节开头介绍的那样,go函数也是可以导出给c使用的。我们来写一个demo,项目文件结构如下:
$ tree
.
├── a.c
├── go.mod
└── main.go
main.go内容
package main
/*
int foo();
*/
import "C"
import "fmt"
//export add
func add(a, b C.int) C.int { //导出go函数
return a+b
}
func main() {
fmt.Println(C.foo())
}
a.c内容
#include "_cgo_export.h"
int foo() {
return add(1, 1); //使用go函数add
}
$ go build -o test
$ ./test
2
总结
本小节介绍了cgo的入门基础知识,介绍了如何开启cgo,介绍cgo和c的类型映射关系,cgo的编译参数如何编写,cgo中c函数2个返回值,以及go函数导出给c使用。
参考资料
cgo的使用场景
在本章的开头,我们建议大家非必要情况不要用cgo。本小节我们详细来看什么时候用cgo。
场景1——提升算法效率
本例中要求计算512维的向量的欧式距离。我们用go原生实现了算法,然后使用c/c++平台的avx(Advanced Vector Extensions 高级向量拓展集)实现同样的算法,同时比对下效率。
package main
/*
#cgo CFLAGS: -mavx -std=c99
#include <immintrin.h> //AVX: -mavx
float avx_euclidean_distance(const size_t n, float *x, float *y)
{
__m256 vsub,vsum={0},v1,v2;
for(size_t i=0; i < n; i=i+8) {
v1 = _mm256_loadu_ps(x+i);
v2 = _mm256_loadu_ps(y+i);
vsub = _mm256_sub_ps(v1, v2);
vsum = _mm256_add_ps(vsum, _mm256_mul_ps(vsub, vsub));
}
__attribute__((aligned(32))) float t[8] = {0};
_mm256_store_ps(t, vsum);
return t[0] + t[1] + t[2] + t[3] + t[4] + t[5] + t[6] + t[7];
}
*/
import "C"
import (
"fmt"
"time"
)
func euclideanDistance(size int,x, y []float32) float32 { //cgo实现欧式距离
dot := C.avx_euclidean_distance((C.size_t)(size), (*C.float)(&x[0]), (*C.float)(&y[0]))
return float32(dot)
}
func euclidean(infoA, infoB []float32) float32 { //go原生实现欧式距离
var distance float32
for i, number := range infoA {
a := number - infoB[i]
distance += a * a
}
return distance
}
func main() {
size := 512
x := make([]float32, size)
y := make([]float32, size)
for i := 0; i < size; i++ {
x[i] = float32(i)
y[i] = float32(i + 1)
}
stime := time.Now()
times := 1000
for i:=0;i<times;i++ {
euclidean(x,y)
}
fmt.Println(time.Now().Sub(stime))
stime = time.Now()
for i:=0;i<times;i++ {
euclideanDistance(size,x,y)
}
fmt.Println(time.Now().Sub(stime))
}
运行一下
$ go run main.go
447.729µs
143.182µs
cgo实现的比go原生的算法效率大概快了四倍。其实go实现欧式距离算法还可以更快,后续在go汇编会介绍绕过cgo直接使用汇编实现欧式距离计算的方式。
场景2——依赖第三方sdk
在实际开发过程中,我们经常会遇到一些第三方sdk,这些sdk很多为了保护源码会用c和c++编写,然后给你sdk头文件和一个动态或者静态库文件。这个时候只好使用cgo实现自己的业务。
还有就是在c/c++生态产生了很多优秀的项目,比如rocksdb,就是c++实现的本地LSM-Tree实现的内嵌型kv数据库。 很多NewSql的底层数据存储都用rocksdb。所以rocksdb被很多语言集成,有java,python,当然还有go。gorocksdb就是用cgo实现的go rocksdb集成。
总结
本小节介绍了两个使用cgo的场景,这两个场景通常比较常见,淡然除了这两个场景还有一些不常见的场景比如go访问系统驱动,这时候通常也会用cgo实现。总的来说使用cgo需要谨慎些。
指针和内存互访
指针是c语言的灵魂,同样指针在go语言中也有很重要的位置。在cgo中go的指针和c的指针可以互相传递,但大多时候这种传递是危险的。go语言是一种有GC的语言,你很难知道指针指向的内容是否已经被回收。而c语言的指针通常情况下是稳定的(除非手动释放,或者返回局部变量指针)。本小节我们来探讨下cgo中指针的运用,以及cgo中go和c内存互相访问。
指针
在本节中,术语Go指针表示指向Go分配的内存的指针(例如通过使用&运算符或调用go内置函数new),
术语C指针表示指向C分配的内存的指针(例如通过调用C.malloc)。
指针是指向内存的起始地址,以指针类型是无关的。在c语言中我们使用void*类型无关的指针,而在go是unsafe.Pointer。这两者指针在cgo中是可以互相传递的。
| c | go |
|---|---|
| void* | unsafe.Pointer |
go访问c的内存
go的由于内存策略的原因,很多时候向系统申请的内存在使用完之后,不会立即返回给系统,而是留着给下次使用。如果有场景想立即返回给出给系统,可以用cgo实现。
package main
/*
#include <stdlib.h>
void* m_malloc(int typeSize ,size_t length) {
return malloc(typeSize * length);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
c := (*[3]int32)(C.m_malloc(C.int(4),3))
defer C.free(unsafe.Pointer(c))
c[0],c[1],c[2] = 0,1,2
fmt.Println(c,len(c))
}
$ go run main.go
&[0 1 2] 3
c访问go内存
我们cgo入门介绍了cgo字符串和字节数组的转换,用了C.CString的方法将 go string转成 * C.char。我们同时强调了在使用完* C.char后记得调用C.free 方法。我们来看下C.CString的定义
const cStringDef = `
func _Cfunc_CString(s string) *_Ctype_char {
p := _cgo_cmalloc(uint64(len(s)+1))
pp := (*[1<<30]byte)(p)
copy(pp[:], s)
pp[len(s)] = 0
return (*_Ctype_char)(p)
}
`
可以看出C.CString是使用cgo函数_cgo_cmalloc申请了内存,然后把go string数据拷贝到这块内存上。所以这块内存在c函数使用是安全的。但是很明显,耗性能,浪费内存空间。
cgo在调用c函数时,能保证作为参数传入c函数的go内存不会发生移动。所以我们可以使用如下方法让c函数临时访问go内存。
package main
/*
#include <stdio.h>
#include <stdlib.h>
int mconcat(const char * a,const char *b,char *c){
return sprintf(c,"%s%s",a,b);
}
*/
import "C"
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
a := C.CString("hello")
b := C.CString("world")
defer func() {
C.free(unsafe.Pointer(a)) //需要手动释放
C.free(unsafe.Pointer(b)) //需要手动释放
}()
ret := make([]byte,20)
p := (*reflect.SliceHeader)(unsafe.Pointer(&ret))
len := C.mconcat(a,b,(*C.char)(unsafe.Pointer(p.Data)))
fmt.Println(len,string(ret[:len]))
}
$ go run main.go
10 helloworld
上面的例子中我们使用了go语言的[]byte去接收c函数字符串拼接,这样子省去很多额外的内存分配。
参考资料
动态链接和静态链接
cgo项目一般会使用到c/c++源码文件,动态链接库,静态链接库这三种资源文件。 c/c++源码一般放在go的源码目录下,在go代码文件include相应的头文件,go编译的时候会扫描目录下c/c++源码文件进行编译。用c/c++源码编译是最好的情况,但很多情况是没有c/c++源码的。
我们接下来通过编译一个使用了gorocksdb的go程序来了解动态链接库编译和使用静态链接库编译。
新建一个项目rocksdbtest,目录文件如下:
$ tree
.
├── go.mod
├── go.sum
└── main.go
main.go内容:
package main
import "C"
import (
"fmt"
rockdb "github.com/tecbot/gorocksdb"
"log"
)
const (
FORMAT = "key%08d"
)
var (
wo = rockdb.NewDefaultWriteOptions()
ro = rockdb.NewDefaultReadOptions()
)
func main() {
dir := "/tmp/gorocksdb-TestDBMultiGet"
opts := rockdb.NewDefaultOptions()
opts.SetCreateIfMissing(true)
db, err := rockdb.OpenDb(opts, dir)
if err != nil {
log.Fatal(err)
}
defer db.Close()
db.Put(wo, []byte(fmt.Sprintf(FORMAT, 1)), []byte("test data"))
a, err := db.Get(ro, []byte(fmt.Sprintf(FORMAT, 1)))
defer a.Free()
if err != nil {
fmt.Println(err)
}
fmt.Println(string(a.Data()))
}
要使用gorocksdb首先需要编译rocksdb,我们参照rocksdb INSTALL中的描述的安装方式安装。我们以ubuntu安装为例:
先安装依赖
- gcc/g++至少要4.8以上以支持c++11
- 安装gflags
sudo apt-get install libgflags-dev - 安装snappy
sudo apt-get install libsnappy-dev - 安装zlib
sudo apt-get install zlib1g-dev - 安装bzip2
sudo apt-get install libbz2-dev - 安装lz4
sudo apt-get install liblz4-dev - 安装lz4
sudo apt-get install libzstd-dev
编译rocksdb
$ git clone https://github.com/facebook/rocksdb.git
$ cd rocksdb
$ git checkout v5.18.3 #切换到稳定分支版本
$ make static_lib #编译的静态链接库
$ make shared_lib #编译的动态链接库
$ ll librocksdb*
-rw-r--r-- 1 wida wida 418296002 11月 21 14:31 librocksdb.a #这是编译后的静态链接库
lrwxrwxrwx 1 wida wida 20 7月 29 09:35 librocksdb.so -> librocksdb.so.5.18.3
lrwxrwxrwx 1 wida wida 20 7月 29 09:35 librocksdb.so.5 -> librocksdb.so.5.18.3
lrwxrwxrwx 1 wida wida 20 7月 29 09:35 librocksdb.so.5.18 -> librocksdb.so.5.18.3
-rwxr-xr-x 1 wida wida 121896448 7月 29 09:35 librocksdb.so.5.18.3 #这是编译后的动态链接库
使用动态链接库
我们先编译使用动态链接库的版本。
$ cd rocksdbtest
$ CGO_CFLAGS="-I/home/wida/cppworkspace/rocksdb/include" CGO_LDFLAGS="-L/home/wida/cppworkspace/rocksdb -lrocksdb -lstdc++ -lm -lz -lbz2 -lsnappy -llz4 -lzstd" go build
$ ll -h rocksdbtest #看下编译后的程序大小
-rwxr-xr-x 1 wida wida 2.3M 11月 21 14:34 rocksdbtest
$ ./rocksdbtest
test data
$ ldd rocksdbtest #看依赖的动态库
linux-vdso.so.1 (0x00007ffcef59b000)
librocksdb.so.5.18 => /usr/local/lib/librocksdb.so.5.18 (0x00007f006c187000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f006be06000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f006ba73000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f006b855000)
libbz2.so.1.0 => /lib/x86_64-linux-gnu/libbz2.so.1.0 (0x00007f006b645000)
libsnappy.so.1 => /usr/lib/x86_64-linux-gnu/libsnappy.so.1 (0x00007f006b43d000)
liblz4.so.1 => /usr/lib/x86_64-linux-gnu/liblz4.so.1 (0x00007f006b220000)
libzstd.so.1 => /usr/lib/x86_64-linux-gnu/libzstd.so.1 (0x00007f006af9c000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f006ad7e000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f006ab7a000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f006a7c0000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007f006a5b8000)
libgflags.so.2.2 => /usr/lib/x86_64-linux-gnu/libgflags.so.2.2 (0x00007f006a393000)
libnuma.so.1 => /usr/lib/x86_64-linux-gnu/libnuma.so.1 (0x00007f006a188000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f0069f70000)
/lib64/ld-linux-x86-64.so.2 (0x00007f006c925000)
从上面的编译结果来看,使用动态链接库编译出来的可执行文件比较小,但是依赖的动态库比较多,这样子带发布程序的时候你需要同时发布依赖的动态库。而且动态库还要保证版本兼容性,碰到不兼容的情况处理起来就相当棘手。
使用静态链接库
使用静态链接库编译也是比较理想的cgo编译选项。编译后的可执行文件也只有一个,不会依赖其他动态链接库,这样对程序部署或者容器化非常有帮助。
使用全静态编译:
$ cd rocksdbtest
$ CGO_CFLAGS="-I/home/wida/cppworkspace/rocksdb/include" CGO_LDFLAGS="-L/home/wida/cppworkspace/rocksdb -lrocksdb -lstdc++ -lm -lz -lbz2 -lsnappy -llz4 -lzstd -linkmode "external" -extldflags "-static"" go build
$ ll -h rocksdbtest
-rwxr-xr-x 1 wida wida 42M 11月 21 14:44 rocksdbtest #这个演示的程序比较小,有时候编译出来可能有上百M
$ ./rocksdbtest
test data
$ ldd rocksdbtest #看依赖的动态库
不是动态可执行文件
编译后的可执行文件只有一个rocksdbtest,ldd命令看它的依赖发现不是动态可执行文件也就是说没有依赖动态链接库。
总结
本小节介绍了cgo程序编译使用动态链接库和静态链接库的使用。最优先的情况是使用源码编译,静态链接库次之,最后是使用动态链接库。
参考资料
go汇编简介
为什么要学习go汇编
go 虽然刚过了10周年的生日,但是go的编译器编译的汇编指令优化程度不是很高,无法和c/c++生态相比。在一些高频使用的算法和函数,go原生有时候显得比较无力。go标准库里头特别是算法库和runtime都大量使用go汇编。 我们在写向量计算的相关代码时,如果利用cpu的sse和avx的指令集会带来可观的性能提升。 我们在排查问题或者了解go底层代码是如何运行的,那么go汇编回事一个利器。汇编代码面前一切了无秘密。
go汇编
go汇编和不同于inter汇编和AT&T汇编,go汇编源于plan9汇编,plan9汇编的相关知识感兴趣的可以去了解下,这里不多做介绍。go汇编是go语言的一部分,只能和go语言源码文件一起编译使用,不像inter汇编和AT&T汇编可以单独编译运行。
CPU 通用寄存器
通用寄存器的名字在 X64 和 plan9 中的对应关系:
| X64 | rax | rbx | rcx | rdx | rdi | rsi | rbp | rsp | r8 | r9 | r10 | r11 | r12 | r13 | r14 | rip |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
一个程序的内存布局
- 代码段:存储程序指令,位于内存最低端
- 数据段(初始化数据段):全局变量或者静态变量,数据段分只读区和读写区。
- BSS段(未初始化数据段):未初始化全局变量
- 栈:一种LIFO结构,从高地址向低地址增长。
- 堆:动态分布内存区,从低向高增长。
参考资料
go 汇编笔记
JLS 指令
CMPQ CX,$3
JLS 48
JLS(通JBE一个意思)转移条件:CMPQ CX,$3 ;JLS 48 当CX的值小于或等于3的时候转跳到48。
编译器优化的例子
go标准库binary.BigEndian中的bigEndian.PutUint32
func PutUint32(b []byte, v uint32) {
_ = b[3] // early bounds check to guarantee safety of writes below
b[0] = byte(v >> 24)
b[1] = byte(v >> 16)
b[2] = byte(v >> 8)
b[3] = byte(v)
}
这个例子 _ = b[3] 这个语句对于的汇编是
$ go tool compile -S main.go |grep main.go:10
0x000e 00014 (main.go:10) PCDATA $0, $0
0x000e 00014 (main.go:10) PCDATA $1, $0
0x000e 00014 (main.go:10) MOVQ "".b+40(SP), CX
0x0013 00019 (main.go:10) CMPQ CX, $3
0x0017 00023 (main.go:10) JLS 48
0x0030 00048 (main.go:10) MOVL $3, AX
0x0035 00053 (main.go:10) CALL runtime.panicIndex(SB)
0x003a 00058 (main.go:10) XCHGL AX, AX
意思很明显是提前判断一下是不是slice 下标越界。
但是这个 为什么不直接写成如下的样子,不是也会检查 panic,而不需要额外的 _ = b[3]
func PutUint32(b []byte, v uint32) {
b[3] = byte(v)
b[2] = byte(v >> 8)
b[1] = byte(v >> 16)
b[0] = byte(v >> 24)
}
其实这边就是涉及编译器优化的问题,我们看下原先 PutUint32的汇编去掉gc的代码
"".PutUint32 STEXT nosplit size=59 args=0x20 locals=0x18
0x0000 00000 (main.go:9) TEXT "".PutUint32(SB), NOSPLIT|ABIInternal, $24-32
0x0000 00000 (main.go:9) SUBQ $24, SP
0x0004 00004 (main.go:9) MOVQ BP, 16(SP)
0x0009 00009 (main.go:9) LEAQ 16(SP), BP
0x000e 00014 (main.go:10) MOVQ "".b+40(SP), CX //这边是回去slice len的值
0x0013 00019 (main.go:10) CMPQ CX, $3
0x0017 00023 (main.go:10) JLS 48
0x0019 00025 (main.go:11) MOVL "".v+56(SP), AX
0x001d 00029 (main.go:11) BSWAPL AX
0x001f 00031 (main.go:14) MOVQ "".b+32(SP), CX
0x0024 00036 (main.go:14) MOVL AX, (CX)
0x0026 00038 (main.go:15) MOVQ 16(SP), BP
0x002b 00043 (main.go:15) ADDQ $24, SP
0x002f 00047 (main.go:15) RET
0x0030 00048 (main.go:10) MOVL $3, AX
0x0035 00053 (main.go:10) CALL runtime.panicIndex(SB)
0x003a 00058 (main.go:10) XCHGL AX, AX
从这段汇编来看,你会看到
b[3] = byte(v)
b[2] = byte(v >> 8)
b[1] = byte(v >> 16)
b[0] = byte(v >> 24)
这个已经直接被优化掉
MOVL "".v+56(SP), AX
BSWAPL AX //指令作用是:32位寄存器内的字节次序变反。比如:(EAX)=9668 8368H,执行指令:BSWAP EAX ,则(EAX)=6883 6896H。
BSWAPL 指令做的工作就和上4个做的工作一样。
我们再看看乱序后的汇编代码
"".PutUint32 STEXT nosplit size=79 args=0x20 locals=0x18
0x0000 00000 (main.go:9) TEXT "".PutUint32(SB), NOSPLIT|ABIInternal, $24-32
0x0000 00000 (main.go:9) SUBQ $24, SP
0x0004 00004 (main.go:9) MOVQ BP, 16(SP)
0x0009 00009 (main.go:9) LEAQ 16(SP), BP
0x000e 00014 (main.go:10) MOVQ "".b+40(SP), CX
0x0013 00019 (main.go:10) CMPQ CX, $3
0x0017 00023 (main.go:10) JLS 68
0x0019 00025 (main.go:11) MOVL "".v+56(SP), AX
0x001d 00029 (main.go:11) MOVQ "".b+32(SP), CX
0x0022 00034 (main.go:11) MOVB AL, 3(CX)
0x0025 00037 (main.go:12) MOVL AX, DX
0x0027 00039 (main.go:12) SHRL $8, AX
0x002a 00042 (main.go:12) MOVB AL, 2(CX)
0x002d 00045 (main.go:13) MOVL DX, AX
0x002f 00047 (main.go:13) SHRL $16, DX
0x0032 00050 (main.go:13) MOVB DL, 1(CX)
0x0035 00053 (main.go:14) SHRL $24, AX
0x0038 00056 (main.go:14) MOVB AL, (CX)
0x003a 00058 (main.go:15) MOVQ 16(SP), BP
0x003f 00063 (main.go:15) ADDQ $24, SP
0x0043 00067 (main.go:15) RET
0x0044 00068 (main.go:10) MOVL $3, AX
0x0049 00073 (main.go:10) CALL runtime.panicIndex(SB)
0x004e 00078 (main.go:10) XCHGL AX, AX
明显看出来,乱序后没有编译器指令优化。
从这里我们就可以知道为什么要先写_ = b[3]这样语句判断下下标边界,而后续的四行代码被编译器优化后 只有对 v 参数做BSWAPL也就没有检查边界的地方。
分布式系统简介
什么是分布式系统
计算机系统有两大基础任务——存储和计算,分布式系统编程是用多台计算机解决像单台计算机一样处理存储和计算问题。而这些问题是不适合用单台计算机去解决。不适合不是说不行,如果你有无限资源而且不考成本,你可以购买或者找人那设计那种单体计算机。但是很少有人拥有无限的资源。因此我们必须在某些实际成本收益曲线上找到适合自己的位置。在较小规模上,升级硬件是不错选择,但是随着问题规模的增加,你将通过靠升级单个节点硬件来解决问题,或者成本变得过高,分布式系统将会是最好的选择。
分布式系统(distributed system)的目标可以归纳为可拓展性,可拓展性包含
- 大小可伸缩性:添加更多节点将使系统线性更快;扩大数据集不应增加延迟
- 地理可伸缩性:应该可以使用多个数据中心,以减少响应用户查询所花费的时间,同时以合理的方式处理跨数据中心的延迟。
- 管理可伸缩性:添加更多节点不会增加系统的管理成本(例如,管理员与机器的比例)。
衡量可拓展性有四个关键的指标性能、延时、可用性和容错
- 性能:它的特点是与时间和资源相比,计算机系统完成的有用工作量。
- 延时:是事物开始和发生之间的时间。
- 可用性:系统处于运行状态的时间比例。如果用户无法访问系统,则称该系统不可用。
- 容错:以归结为,预估可能遇到的故障,然后设计可以容忍的系统或算法。
分布式系统受两个物理因素的约束:
- 节点数(随所需的存储和计算能力而增加)
- 节点之间的距离
由这两个物理因素带入如下三个问题
- 独立节点数量的增加会增加系统发生故障的可能性(降低可用性并增加管理成本)
- 独立节点数量的增加可能会增加节点之间通信的需求(随着规模的增加而降低性能)
- 地理距离的增加会增加远端节点之间通信的延迟(延迟会带来一致性问题)
这三个问题是非常难完全解决的,CAP定理告诉我们完美的分布式系统是不存在的。
CAP定理
CAP定理最初是由计算机科学家Eric Brewer提出的一个猜想。它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):所有节点同时看到相同的数据(每次请求都能拿到最新的数据)。
- 可用性(Availability):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(每次请求都能得到响应,但是数据可能不是最新的)。
- 分区容错性(Partition tolerance):尽管由于网络或者节点故障,但是整个服务仍能对外提供服务(是否允许有节点故障)。
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。
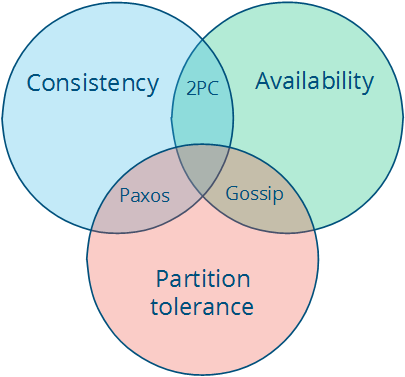
如上图显示,具有所有三个属性的交叉部分是无法实现的。然后我们得到这三种两两结合的不同的系统类型:
CA(一致性+可用性)。示例包括完全严格的仲裁协议,例如2PC(两阶段提交)。 CP(一致性+分区容错性)。示例包括多数派仲裁协议,其中少数派分区不可用,例如Paxos,Raft算法。 AP(可用性+分区容错性)。示例包括使用冲突解决方案的协议,例如Gossip协议。
CA和CP系统设计均提供相同的一致性模型:高度一致性。唯一的区别是CA系统不能容忍任何节点故障。在CP系统中2n+1个节点中可以容忍n个节点故障。CA系统不支持分区,它们通常使用两阶段提交算法,并且在传统的分布式关系数据库中很常见。
总结
本小节简要介绍了分布式系统的概念,以及分布式系统的挑战。我们还介绍了分布式系统中非常出名的CAP定理,我们知道了AP,CA,CP系统的设计侧重点。本章节后续会介绍这三个系统的代表协议(算法)Gossip,2PC,Raft(Paxos可能更有名,但是产业界实现很少,Raft目前用得更多)。
参考资料
分布式一致性算法——2PC(二阶段提交)
二阶段提交算法(Two-phase Commit,即2PC)
二阶段提交参与者有两种角色:协调者(coordinator)和参与者(participants)
二阶段提交顾名思义有两个阶段:
-
第一个阶段称为准备阶段,调者(coordinator)向所有参与者(participants)发送提议(propose)并分别收咨询他们的意见,并且收集它们的反馈(vote)。
-
第二个阶段称为提交阶段,协调者(coordinator)根据反馈情况决定是提交(commit)或者中止(abort)事务。
阶段2收集到的已经只要有一个是abort的话,整个事务就中止,当所有的参与者都给的反馈是commit的时候事务才提交。
二阶段提交的问题
如我们上一个小节介绍的二阶段提交属于CA(一致性+可用性)系统,当有节点宕机的时候,二阶段提交加故障处理就会变得复杂。
二阶段提交的主要问题:
- 同步阻塞问题,二阶段提交的vote过程是同步阻塞的。
- 协调者单点问题
- 在协调者和参与者都宕机的情况下,可能出现严重的阻塞问题。在第二阶段协调者和一个参与者同时宕机,而且这个参与者在宕机前已经做了操作(commit/abort),这个时候协调者恢复,由于不知道宕机参与者的状态,协调者没办法判断是提交还是中止,这个时候只能等宕机的参与者恢复。
- 脑裂问题,如果在第二点只有部分参与者收到执行命令,那么将导致数据不一致。
三阶段提交算法(three-phase Commit,即3PC)
三阶段提交算法(Three-Phase Commit, 3PC)最关键要解决的就是 coordinator和参与者同时挂掉导致数据不一致的问题,所以3PC在 2PC 中又添加一个阶段,这样三阶段提交就有:CanCommit、PreCommit 和DoCommit三个阶段。
3PC虽然能解决部分2PC的问题,但是同样过多的交互会导致其他的问题,3PC在实际项目中很少使用。感兴趣的同学可以去了解下,这边不再赘述。
分布式一致性算法——Raft算法
上个小节我们介绍了2PC算法,属于CA算法。本小节我们介绍一个属于CP的算法——raft。
一致性算法允许一组机器像一个整体一样工作,即使其中一些机器出现故障也能够继续工作下去,这个特性使得一致性算法一直是产业界研究的热门,在产业界机器故障是需要纳入架构设计中的。
在介绍raft之前需要引入两个概念 —— 状态机和状态机复制。对于我们程序员来说这两个概念在工作中其实非常常见,我们需要明白常见到东西经常会被抽象成模型,因为只有做了这个抽象化的模型后才更好的进行研究。
状态机(FSM)
状态机又称有限状态机(finite-state machine 简称FSM),是表示有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型。
状态机被定义为下面这些值元组:
- 一组状态
- 一组输入
- 一组输出
- 一个转换函数(输入 x 状态 → 状态)
- 一个输出函数(输入 x 状态 → 输出)
- 被称为“初始”的一个独特状态
一个状态机从“初始”状态开始,每一个输入都被传入转换函数和输出函数,以生成一个新的状态和输出。在新的输入被接收到前,状态保持不变。
看到这个模型的定义内容我们很容易联想到数据库其实就是一个经典的状态机模型。刚创建的数据库就是一个初始状态,然后接收不同的输入(增,删,改)后根据本身状态计算出新的状态,查询可以理解成输出状态,查询的时候带的函数根据当前的状态计算出新的结果输出。
状态机复制
上边介绍了状态机,状态机必须具备确定性:多个相同状态机的拷贝,从同样的“初始”状态开始,经历了相同的输入序列后,会达到同样的状态,并且输出同样的结果,这个过程我们称为状态机复制。
 上图中展示了通过日志方式实现的状态机的复制,client通过调用
上图中展示了通过日志方式实现的状态机的复制,client通过调用 Consensus Module(一致性模块),一致性模块产生相同的日志,然后发给多个状态机,这几个状态机接收相同的日志后,执行得到的状态是一样的。
这个模型我们也应该很快联想到数据库的主从复制,主数据库接收各种输入,然后把这种输入复制一份给从数据库,从数据库就能生成和主数据库一模一样的数据。
在计算机领域,状态机复制是实现容错服务的常见方式。但是在这边我们更关注这个 Consensus Module,这个一致性模块就是一致性算法的工作核心——保证复制日志相同。在一台服务器上,一致性模块接收客户端发送来的指令然后增加到自己的日志中。它和其他服务器上的一致性模块进行通信来保证每一个服务器上的日志最终都以相同的顺序包含相同的请求,尽管有些服务器会宕机。一旦指令被正确的复制,每一个服务器的状态机按照日志顺序处理他们,然后输出结果被返回给客户端。因此,服务器集群看起来形成一个高可靠的状态机。
实际系统中使用的一致性算法通常含有以下特性:
- 安全性保证(绝对不会返回一个错误的结果):在非拜占庭错误情况下,包括网络延迟、分区、丢包、冗余和乱序等错误都可以保证正确。
- 可用性:集群中只要有大多数的机器可运行并且能够相互通信、和客户端通信,就可以保证可用。因此,一个典型的包含 5 个节点的集群可以容忍两个节点的失败。服务器被停止就认为是失败。他们当有稳定的存储的时候可以从状态中恢复回来并重新加入集群。
- 不依赖时序来保证一致性:物理时钟错误或者极端的消息延迟只有在最坏情况下才会导致可用性问题。
- 通常情况下,一条指令可以尽可能快的在集群中大多数节点响应一轮远程过程调用时完成。小部分比较慢的节点不会影响系统整体的性能。
Raft算法
Raft是一种用来实现Consensus Module功能的一种算法。raft通过选举选出一个Leader,然后这个leader复制日志到其他服务器上,在保证安全的时候通知其他服务器将日志应用到状态机上。Leader自己可能宕机,Leader宕机后会新的一轮选举会产生新的Leader。
raft通过Leader的方式可以将一致性问题分解为如下三个问题:
- Leader选举:当现存的Leader宕机的时候,一个新的Leader很快被选举出来。
- 日志复制:Leader必须从客户端接收日志然后复制到集群中的其他节点,并且强制要求其他节点的日志保持和自己相同。
- 安全性:如果有任何的服务器节点已经应用了一个确定的日志条目到它的状态机中,那么其他服务器节点不能在同一个日志索引位置应用一个不同的指令。
Leader选举
在接收Leader选举前需要看下,raft的节点状态迁移和任期。
节点状态
raft节点有三个状态:
- Leader(领导者)
- Follwer(跟随者)
- Candidate(候选人)
在任何时刻,每一个服务器节点都处于这三个状态之一:Leader、 Follwer或者Candidate
每个节点一开始都是Follwer,在一定时间内没有收到Leader发过来的心跳包后,会触发一个timeout,这个时候节点会让自己变成候选者,给集群里头的机器发信息,发起投票。
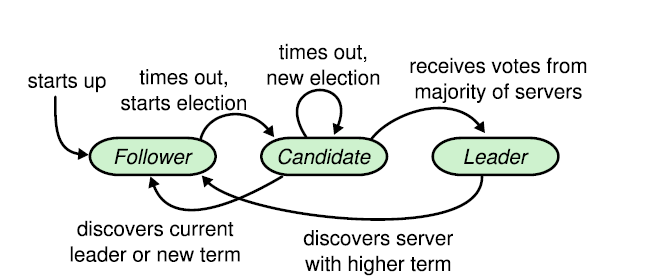
任期
raft把时间被划分成一个个的任期,每个任期开始都是一次选举。在选举成功后,Leader会管理整个集群直到任期结束。有时候选举会失败,那么这个任期就会没有Leader而结束。任期之间的切换可以在不同的时间不同的服务器上观察到。
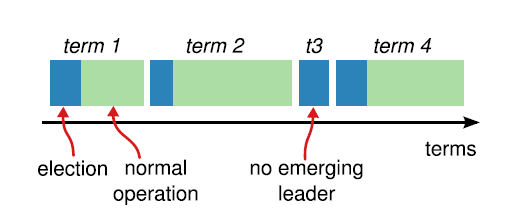
Leader选举过程
- 每个节点初始化的时候都是跟随者。
- 领导人维护地方是通过给所有的跟随者发心跳检查实现。
- 跟随者在一定时间内没有收到心跳检测会把自己变成候选者,要求集群里头的节点投票
如上图动画显示,在trem 0时集群没有Leader,在节点B在超时时间内没有接收到心跳包后会发动选举,它的角色由Follwer变成Candidate,这个时候进入trem1,它先给自己投了一票,然后让节点 A和节点 C投票,投票通过后节点 B作为Leader会一直和节点 A和节点 C 维持心跳。
接下来我们看下节点 B节点做为Leader后宕机的情况。
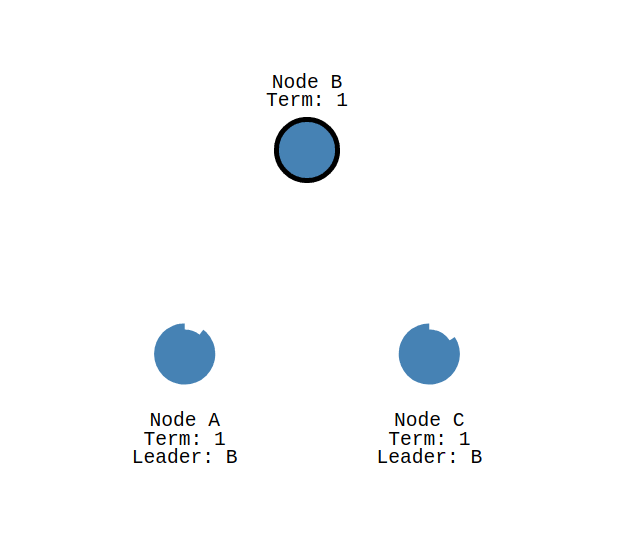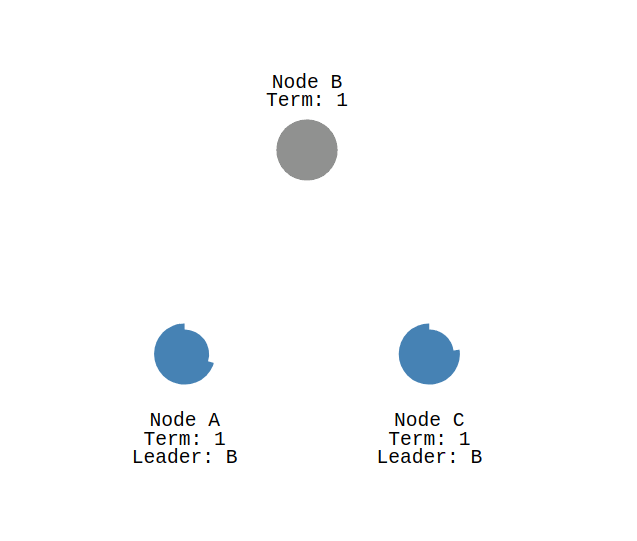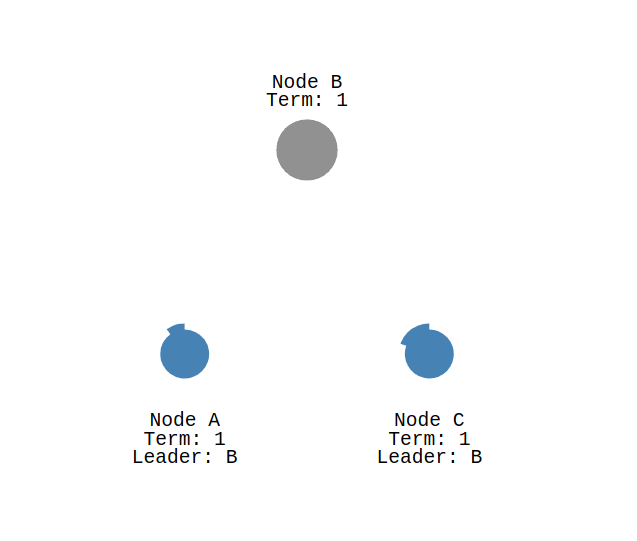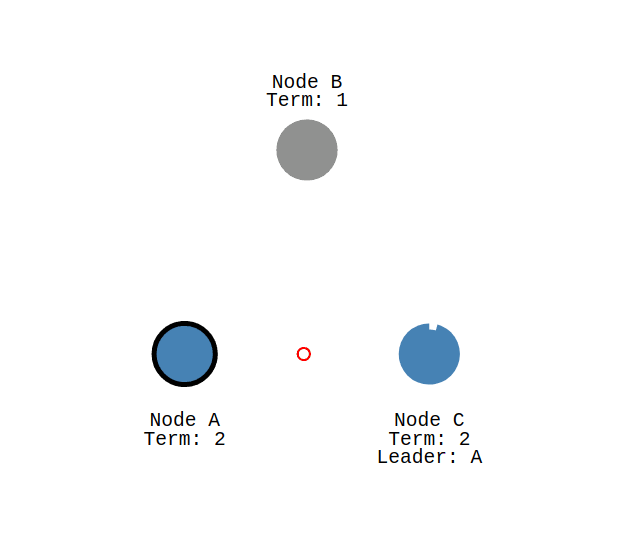
如上图动画显示,节点B宕机后,在一个心跳周期内没有收到心跳包,节点A变成Candidate,然后任期进入trem 2,节点A给自己投票,然后让节点C投票,A变成了Leader。
日志复制
当Leader被选举后会作为唯一和client交互的节点(raft的设计是为了保持数据一致性和高可用,性能不是最重要的点,但是在产业界性能会被考虑,很可能Flower也会做成一个和用户交互的节点,甚至提供数据读取功能,尽管这个数据可能和Leader的数据可能不一致)。客户端的每一个请求都包含一条被复制状态机执行的指令(一般在数据库场景时,查询不会改变状态,所以不复制日志)。Leader将日志通过rpc发送给Follwer,然后收集集群一半以上(包括他自己)收到日志的反馈后,执行日志中的的指令。 领导执行指令成功后,通过rpc通知集群跟随者执行日志指令。 如果跟随者崩溃或者运行缓慢,再或者网络丢包,领导人会不断的重复尝试附加日志条目RPC直到所有的跟随者都最终存储了所有的日志条目。
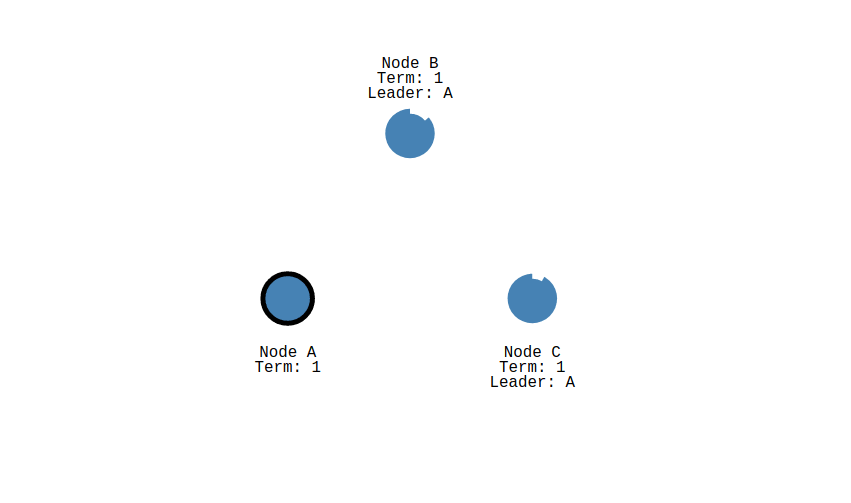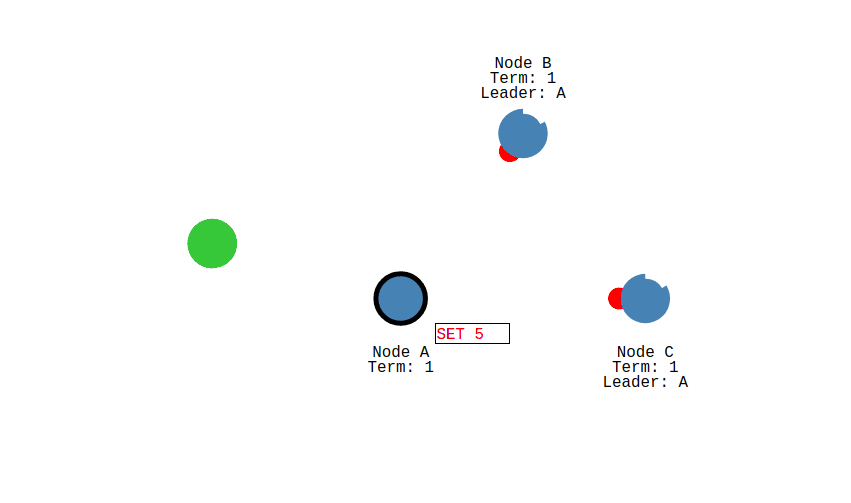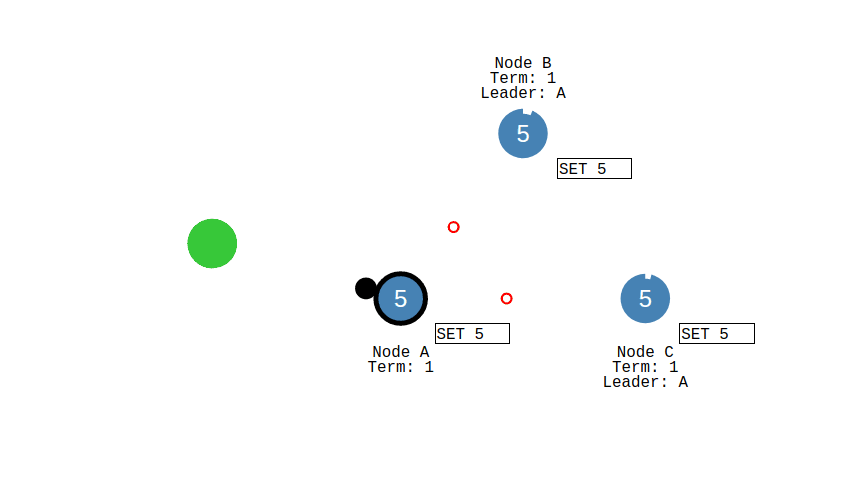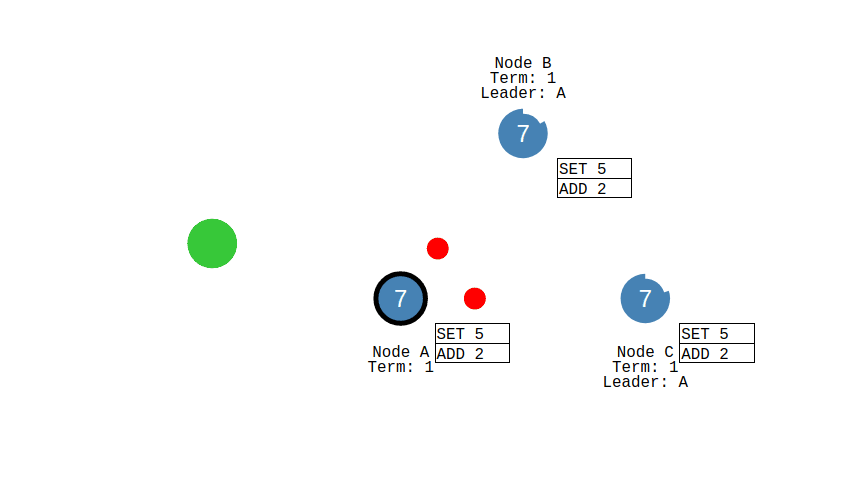
如上图动画所示 Leader节点A收到客户端SET 5的请求,然后经日志复制给节点B和C,主要这个时候日志的状态为uncommit,等收到B和C的反馈后,节点A将日志commit,这个时候节点A的状态机的值变成5,然后再通知节点B和C将日志commit。上图演示的是理想情况下,网络不出现分区的情况。
网络分区将原先的 Leader节点和 Follower节点分隔开,Follower收不到Leader的心跳将发起选举产生新的 Leader,这时就产生了双 Leader我们称之为“脑裂”。原先的 Leader 独自在一个区,向它提交数据不可能复制到多数节点所以永远提交不成功。向新的 Leader 提交数据可以提交成功,网络恢复后旧的 Leader 发现集群中有更新任期(Term)的新 Leader 则自动降级为 Follower 并从新 Leader 处同步数据达成集群数据一致。
安全性
我上面讨论的raft中Leader的选举和日志的复制,但是并没有讨论到如何保证所有状态机是按相同的顺序正确执行日志的。接下来介绍raft如何做到这一点的。
raft做了选举限制,Leader需要有全部的日志,在投票的时候没有包含全部日志的节点不会被选举。Raft通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。这一限制保证了任何的领导人对于给定的任期号,都拥有了之前任期的所有被提交的日志条目。
总结
本小节讨论了raft算法的一些主要原理,raft原始论文中还有本文没有提及的一些内容,比如集群成员变化和日志压缩的讨论,感兴趣的可以参照参考文档中原始论文了解下。
在go语言生态里,raft算法已经有很好的实现比如etcd的raft,还有consul的raft实现。
还有一点需要说明下,raft中所有的节点数据应该是一模一样的,但是对外服务的应该是只有Leader节点。很多初学者不理解,为什么增加了那么多的机器只是做了隐形备份机?严格意义上说raft算法会让整个集群的性能甚至比不上一个Leader单机的性能(因为没有日志复制和状态收集)。备份的机器是为了在Leader宕机后有后续的Leader能产生,不是为了提高数据吞吐能力。当然在产业界raft的这种机器冗余基本上比较难接受,很多运用都对Follower功能做了一定改造,有兴趣的可以去了解写Tidb多raft的一些改造。
参考文档
分布式一致性算法——Gossip算法
前两节我们介绍了CA算法的典型——2PC,CP算法的典型——Raft,本小节要介绍AP算法的典型——Gossip算法。
Gossip算法有很多别名,流言算法,流行病算法等,Gossip最早是在 1987 年发表在 ACM 上的论文 《Epidemic Algorithms for Replicated Database Maintenance》中被提出。后来因为Cassandra中运用名声大噪。近几年区块链盛行,比特币(Bitcoin)和超级记账本( Fabric)同样使用了Gossip。
我们看下Gossip的算法模型:
和Raft算法不同,Gossip算法中的节点没有Leader和Follower之分,它们都是对等的。 假定在一个有边界的网络中,每个状态机节点随机和其他状态机节点通讯,经过一段时间后在这个网络中的所有状态机节点的状态会达成一致。每个状态机节点都可能知道其他状态机节点或者只知道他邻近的节点,通信后他们的最终状态是一致的。从这个算法模型上看确实很想流言和流行病的传播模型。
我在举个实际例子来理解这个模型:
我们的每个状态机节点带有三元祖数据(key,value,version),我们能保证version是单向递增的。假设我们节点中有A,B,C,E,F五个节点构成环形结构,然后每个节点和相邻的节点每隔1秒通讯一次,把自己的数据(key,value,version)推个两个相邻节点,这两个相邻节点拿到数据后和自己的数据做比对,如果数据比自己新则更新自己的数据。这个模型最多2秒就能让整个集群数据收敛成一致。
上面的例子还有很多需要讨论的,第一每次同步的数据是全量还是增量,第二每次更新是节点主动推还是节点主动去拉,还会既有推也有拉。这两个问题会衍生初Gossip的类型和通讯方式。
Gossip 类型
Gossip 有两种类型:
- Anti-Entropy(反熵):以固定的概率传播所有的数据,可以理解为全量比对。
- Rumor-Mongering(谣言传播):仅传播新到达的数据,可以理解为增量比对。
Anti-Entropy模式会让节点物理资源(网络和cpu)负担很重,Rumor-Mongering模式对节点资源负担相对较小,但是如何界定新数据变得比较困难,而且很难容错,无法保证一致性,所以反而Anti-Entropy有更大的价值,对于Anti-Entropy模式的优化研究更多。Anti-Entropy模式并不是真正的传送所有数据,而是变成如何追踪整个数据的变动,然后快速的找到数据的差异将差异数据传送。默克尔树(Merkle Tree)就是非常不错的一差异定位算法,有兴趣的可以去了解下。
Gossip算法的通讯方式
gossip Node A 和 Node B有三种通信方式:
push: A节点将数据和版本号(key,value,version)推送给B节点,B节点更新A中比自己新的数据 pull:A仅将(key,version)推送给B,B将本地比A新的数据(Key,value,version)推送给A,A更新本地 push/pull:A仅将(key,version)推送给B,B将本地比A新的数据(Key,value,version)推送给A,A更新本地,A再将本地比B新的数据推送给B,B更新本地。
从上面的描述上看,push/pull的方式虽然通讯次数最多但是仅需要一个时间周期就能让A,B节点完全同步,Cassandra就是采用这个方式。
Gossip算法的优点:
- 扩展性:网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
- 容错性:网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 算法具有天然的分布式系统容错特性。
- 去中心化:Gossip 算法不要求任何中心节点,所有节点都是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
Gossip算法的缺点:
- Gossip算法无法确定某个时刻所有状态机的状态是否一致。
- Gossip算法由于要经常和自己的相关节点通讯,因此可能造成大量冗余的网络流量,甚至可能造成流量风暴。
总结
Gossip算法从他的特性来说应该是一种非常妙的算法,在非强一致性要求的领域非常实用,去中心话,同时又有天然的拓展性,顺带天然的故障检测属性。 在go生态在gossip的实现比较多,比较出门的有hashicorp实现的memberlist。
参考资料
全局时间戳
在分布式系统中,由于各个机器的时间可能存在差异,那么很多场景需要一个全局时间戳。比如分布式事务系统,每一个事务号需要全局唯一且能体现时间序。另外全局时间戳还能作为分布式id使用。本小节将参照tidb Pd的tso的实现介绍如何实现全局时间戳。
Tso全称是timestamp oracle,作为全局时间戳系统他需要有如下两个特性
- 要满足快速大量分配
- 分配的时间一定是单调递增的,不能出现回退的情况
Tso结构
Tso由两个部分组成,物理时间和逻辑时间组成,物理时间由当前unix时间戳到毫秒数,逻辑时间是一个最大值为262144(1 << 18)的计数器,所以说1ms可以分配262144个全局时间戳,这个量在大多数场景都是可以满足的。
type Tso struct {
physical time.Time
logical int64
}
量可以满足了,性能如何保证的?我们看下分配函数
func (s *Server) GetTs(count int32) proto.Timestamp {
ts := s.ts.Load().(*Tso)
resp := proto.Timestamp{}
resp.Logical = atomic.AddInt64(&ts.logical, int64(count))
resp.Physical = ts.physical.UnixNano() / 1e6
return resp
}
上面的代码所示,获取Tso的计算都在内存中,用了原子操作给逻辑时间增加,性能能得到保障。
如何保证单调递增的,不能出现回退的情况
Tso服务器工作的时候是单点的,只有这样才能保证物理时间是递增的。单点带来的风险就是如果机器故障了那么这服务如何做到高可用? Tso服务会每隔一段时间把自己的加了3秒后的时间戳(纳秒)存到etcd中,etcd会保证这个数据的安全,当tso宕机之后,备用tso服务器会立即启动,从etcd中读取数值然后和自己的时间比对, 如果发现自己的时间比etcd中的值小则会等待。
last, err := s.loadTimestamp()
if err != nil {
return errors.Trace(err)
}
var now time.Time
for {
now = time.Now()
if wait := last.Sub(now) + updateTimestampGuard; wait > 0 {
log.Warnf("wait %v to guarantee valid generated timestamp", wait)
time.Sleep(wait)
continue
}
break
}
经过如上的处理后,分配的时间一定是单调递增的,不能出现回退的情况要求就可以完美解决。但是引入一个两个新的问题
-
tso宕机后另一个备用服务器怎么知道,如何快速接管服务
假设tso有两台机器A和B,A和B启动的时候会发送Leader选举,选举的机制利用etcd的租约(lease)和事务,代码如下
// CampaignLeader is used to campaign the leader. func (m *Member) CampaignLeader(lease *LeaderLease, leaseTimeout int64) error { err := lease.Grant(leaseTimeout) if err != nil { return err } leaderKey := m.GetLeaderPath() // The leader key must not exist, so the CreateRevision is 0. resp, err := NewSlowLogTxn(m.client). If(clientv3.Compare(clientv3.CreateRevision(leaderKey), "=", 0)). Then(clientv3.OpPut(leaderKey, m.MemberInfo(), clientv3.WithLease(lease.ID))). Commit() if err != nil { return errors.WithStack(err) } if !resp.Succeeded { return errors.New("failed to campaign leader, other server may campaign ok") } return nil }所以A和B只有一台能成为leader。假定A成为了leader,那么ectd存{tso_leader:A},租约超时为1s,B和集群中其他client会watch这个key,那么A会每500毫秒会去续约,如果超过1秒A没有去续约,{tso_leader:A}这条数据会失效,这个时候会再次选举B就能顺利接管服务。
-
停3秒时间是否有办法优化
上面如果发生A和B tso服务发生了切换有可能会发生3s内没办法服务的情况,tidb官方老早就解决了这个问题, A在宕机前存在etcd的时间为A的时间加了3秒,这个时候A宕机,B被选成leader,B拿到etcd中值,发现这个比自己的大,B不会在等待(sleep)直接把这个值作为自己的物理时间,然后在下个时间更新周期可能不更新。
func (s *Server) SyncTime(lease *cluster.LeaderLease) error { //从etcd last, err := s.loadTs() if err != nil { return errors.WithStack(err) } next := time.Now() if tSub(next, last) < updateTimestampGuard { next = last.Add(updateTimestampGuard) } save := next.Add(saveInterval) if err := s.SaveTime(save); err != nil { return err } s.lease = lease tso := Tso{physical: next} s.ts.Store(&tso) return nil } func (s *Server) UpdateTime() error { prev := s.ts.Load().(*Tso) now := time.Now() since := tSub(now, prev.physical) if since > 3*UpdateTimestampStep { log.Log.Warn("clock offset: %v, prev: %v, now %v", since, prev.physical, now) } if since < 0 { // 这里轮空 return nil } var next time.Time prevLogical := atomic.LoadInt64(&prev.logical) if since > updateTimestampGuard { next = now } else if prevLogical > maxLogical/2 { log.Log.Warn("the logical time may be not enough prev-logical :%d", prevLogical) next = prev.physical.Add(time.Millisecond) } else { return nil } if tSub(s.lastSavedTime, next) <= updateTimestampGuard { save := next.Add(saveInterval) if err := s.SaveTime(save); err != nil { return err } } current := &Tso{ physical: next, logical: 0, } s.ts.Store(current) return nil }
总结
本小节参照tidb Pd的tso的实现介绍如何实现全局时间戳,以及如何保证全局递增和如何保证高效分配。还顺带介绍了如何利用etcd选主。在分布式系统系统中全局时间戳系统的运用场景非常广,实现稳定可靠的全局时间戳系统非常有价值。
参考资料
Etcd
在本章节我们不止一次提到etcd,因为etcd这个项目在go语言分布式生态里头非常的重要。etcd个高可用的分布式键值(key-value)数据库,采用raft协议作为一致性算法,基于Go语言实现。etcd在go分布式系统生态里头的位置相当于zookeeper在java分布式系统生态的位置。tidb的raft系统是基于etcd的实现然后用rust实现的,tidb的pd系统还直接内嵌了etcd。在微服务生态里头etcd可以做服务发现组件使用,kubernetes也用etcd保存集群所有的网络配置和对象的状态信息。
etcd的特点
- 简单:提供定义明确的面向用户的API(有http和grpc实现,注意http和grpc分别用了两套存储,数据不同)
- 安全:支持client端证书的TLS
- 快速:基准测试支持10,000次write/s
- 可靠:使用raft协议保证数据一致性
对于想研究分布式系统的gopher来说,etcd是一个非常值得好好阅读源码的项目。它的raft实现,mvcc,wal实现都非常典型。
etcd使用
etcd项目有两个go client,一个基于http restful对于源码目录里头的client,另外一个基于grpc对于源码目录的clientv3,需要注意是这两个api操作的数据是不一样的。client支持的功能较小,而且性能也比较有问题,在go生态里头都会用基于grpc的clientv3。
连接etcd
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/etcd-io/etcd/clientv3"
)
var client *clientv3.Client
func init() {
var err error
client, err = clientv3.New(clientv3.Config{
Endpoints: []string{"127.0.0.1:2379"}, //集群有多个需要写多台
DialTimeout: 5 * time.Second,
})
if err != nil {
log.Fatal(err)
}
}
kv操作
etcd 支持来时nosql数据库一样的 kv操作。
//kv操作
func kv() {
_, err := client.Put(context.Background(), "sample_key", "sample_value")
if err != nil {
log.Fatal(err)
}
resp, err := clientv3.NewKV(client).Get(context.Background(), "sample_key")
if n := len(resp.Kvs); n == 0 {
fmt.Println("not found")
return
}
fmt.Println(string(resp.Kvs[0].Value))
client.Delete(context.Background(), "sample_key")
resp, err = clientv3.NewKV(client).Get(context.Background(), "sample_key")
if n := len(resp.Kvs); n == 0 {
fmt.Println("not found")
return
}
fmt.Println(string(resp.Kvs[0].Value))
}
运行一下
$ go run main.go
sample_value
not foun
watch(监听)
监听是指etcd可以对单个key或者摸个前缀的key进行监听,如果这些key的信息有变化则会通知监听的client。利用这个功能etcd可以做配置中心,或者做服务发现。
//监听 watch
func watch() {
go func() {
for {
ch := client.Watch(context.Background(), "sample_key") //监听sample_key
for wresp := range ch {
for _, ev := range wresp.Events { //打印事件
fmt.Println(ev)
}
}
}
}()
_, err := client.Put(context.Background(), "sample_key", "sample_value1")
if err != nil {
log.Fatal(err)
}
client.Delete(context.Background(), "sample_key")
}
运行一下
$ go run main.go
&{PUT key:"sample_key" create_revision:18157 mod_revision:18157 version:1 value:"sample_value1" <nil> {} [] 0} #PUT事件
&{DELETE key:"sample_key" mod_revision:18158 <nil> {} [] 0}#DELETE事件
我看到通过Watch 我们监控到了PUT和DELETE事件,在实际项目中可以根据业务需求针对相关的事件做成处理。
Lease(租约)
我们在上个小节介绍了 全局时间戳的实现,里头用到了etcd Lease来做选主服务,etcd的Lease可以用来做服务状态监控,再配合watch就能做到故障恢复。上个小节的选主服务本质上是我们常见的主备切换过程。接下来我们看下etcd Lease是怎么使用的。
//租约
func lease() {
lease := clientv3.NewLease(client)
//设置10秒租约 (过期时间为10秒)
leaseResp, err := lease.Grant(context.TODO(), 10)
if err != nil {
log.Fatal(err)
}
leaseID := leaseResp.ID
fmt.Printf("ttl %d \n", leaseResp.TTL)
keepRespChan, err := lease.KeepAlive(context.TODO(), leaseID) //启动自动续租服务
if err != nil {
fmt.Println(err)
return
}
go func() { //新开一个协程监控 keepalive结果
outer:
for {
select {
case keepResp := <-keepRespChan:
if keepResp == nil {
fmt.Println("租约失效了")
break outer
} else {
fmt.Printf("续租成功 time:%d id:%d,ttl:%d \n", time.Now().Unix(), keepResp.ID, keepResp.TTL)
}
}
}
}()
kv := clientv3.NewKV(client)
putResp, err := kv.Put(context.TODO(), "sample_key_lease", "", clientv3.WithLease(leaseID))
if err != nil {
fmt.Println(err)
return
} else {
fmt.Println("写入成功", putResp.Header.Revision)
}
}
运行一下
$ go run main.go
ttl 10
续租成功 time:1577158783 id:7587839846421449960,ttl:10
写入成功 18159
续租成功 time:1577158786 id:7587839846421449960,ttl:10
续租成功 time:1577158790 id:7587839846421449960,ttl:10
续租成功 time:1577158793 id:7587839846421449960,ttl:10
续租成功 time:1577158797 id:7587839846421449960,ttl:10
续租成功 time:1577158800 id:7587839846421449960,ttl:10
我们看到超时时间为10秒,续租程序会在租约失效前大概(1/3 TTL)
nextKeepAlive := time.Now().Add((time.Duration(karesp.TTL) * time.Second) / 3.0)
自动续租(修改TTL),从而实现key一直有效。在服务宕机或者异常的时候没有执行续租,那么这个key将会在10秒后失效,如果其他client watch这个key的话就能监听的这个key被删除了。
总结
本小节简要介绍了etcd的一些特性,以及go语言etcd v3版本的api是如何使用的。最后还是推荐想了解分布式系统的gopher去阅读etcd源码。
go 调试器
go 没有官方的调式器,有个第三方调试工具delve在社区非常受欢迎。
安装delve
安装到GOBIN目录
$ go get -u github.com/go-delve/delve/cmd/dlv
将GOBIN目录添加到PATH环境变量中。
$ dlv version
Delve Debugger
Version: 1.3.0
Build: $Id: 2f59bfc686d60989dcef9de40b480d0a34aa2fa5
ok,安装成功。
delve使用
我先写一下要被调试的程序。
package main
import (
"fmt"
"time"
)
func test(a int) int {
d :=3
a = d+3
return a
}
func main() {
a ,b:=1,3
for i:=0;i<5;i++ {
a++
}
test(a)
go func() {
a +=1
b -=1
time.Sleep(10e9)
b +=1
}()
fmt.Println(a,b)
time.Sleep(100e9)
}
dlv debug 调试源码
用到main package目录下运行
$ dlv debug
Type 'help' for list of commands.
(dlv) h
The following commands are available:
args ------------------------ Print function arguments.
... //这边省略
Type help followed by a command for full documentation.
我们看了下使用帮助
args ------------------------ Print function arguments.
break (alias: b) ------------ Sets a breakpoint.
breakpoints (alias: bp) ----- Print out info for active breakpoints.
call ------------------------ Resumes process, injecting a function call (EXPERIMENTAL!!!)
clear ----------------------- Deletes breakpoint.
clearall -------------------- Deletes multiple breakpoints.
condition (alias: cond) ----- Set breakpoint condition.
config ---------------------- Changes configuration parameters.
continue (alias: c) --------- Run until breakpoint or program termination.
deferred -------------------- Executes command in the context of a deferred call.
disassemble (alias: disass) - Disassembler.
down ------------------------ Move the current frame down.
edit (alias: ed) ------------ Open where you are in $DELVE_EDITOR or $EDITOR
exit (alias: quit | q) ------ Exit the debugger.
frame ----------------------- Set the current frame, or execute command on a different frame.
funcs ----------------------- Print list of functions.
goroutine (alias: gr) ------- Shows or changes current goroutine
goroutines (alias: grs) ----- List program goroutines.
help (alias: h) ------------- Prints the help message.
libraries ------------------- List loaded dynamic libraries
list (alias: ls | l) -------- Show source code.
locals ---------------------- Print local variables.
next (alias: n) ------------- Step over to next source line.
on -------------------------- Executes a command when a breakpoint is hit.
print (alias: p) ------------ Evaluate an expression.
regs ------------------------ Print contents of CPU registers.
restart (alias: r) ---------- Restart process.
set ------------------------- Changes the value of a variable.
source ---------------------- Executes a file containing a list of delve commands
sources --------------------- Print list of source files.
stack (alias: bt) ----------- Print stack trace.
step (alias: s) ------------- Single step through program.
step-instruction (alias: si) Single step a single cpu instruction.
stepout (alias: so) --------- Step out of the current function.
thread (alias: tr) ---------- Switch to the specified thread.
threads --------------------- Print out info for every traced thread.
trace (alias: t) ------------ Set tracepoint.
types ----------------------- Print list of types
up -------------------------- Move the current frame up.
vars ------------------------ Print package variables.
whatis ---------------------- Prints type of an expression.
这个使用帮助的文档英文都不需要翻译,相信大家都能看懂。
你不需要死级记得上面的命令,进入dlv调试模式后,敲你命令搜字母 tab 一下就可以自动补全。实在忘记了,你再 help 一下就会显示帮助文档。
打断点
delve 打断点的命令是break 简写b,打断点有两种方式
- 我们知道某个包的某个函数比如
main.main我们使用break main.main就可以设置断点 - 我们知道某个源码文件第几行,我们可以用
break 文件名:行号的方式设置断点,例如break main.go:7
使用breakpoints可以查看所用设置的断点
$ dlv debug
Type 'help' for list of commands.
(dlv) break main.main
Breakpoint 1 set at 0x4aa148 for main.main() ./main.go:5
(dlv) b main.go:7
Breakpoint 2 set at 0x4aa1ab for main.main() ./main.go:7
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4aa148 for main.main() ./main.go:5 (0)
Breakpoint 2 at 0x4aa1ab for main.main() ./main.go:7 (0)
(dlv)
设置好断点后我们可以使用 continue 让程序运行到断点。多个断点的话,再按continue就能到下一个断点。
(dlv) c
> main.main() ./main.go:12 (hits goroutine(1):1 total:1) (PC: 0x4aa3f8)
7: func test(a int) int {
8: d :=3
9: a = d+3
10: return a
11: }
=> 12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
17: test(a)
(dlv) c
> main.main() ./main.go:15 (hits goroutine(1):1 total:1) (PC: 0x4aa476)
10: return a
11: }
12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
=> 15: a++
16: }
17: test(a)
18: go func() {
19: a +=1
20: b -=1
(dlv)
删除断点
clear 和 clearall 删除断点,clear命令后面有个参数 breakId
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4aa3f8 for main.main() ./main.go:12 (1)
Breakpoint 2 at 0x4aa476 for main.main() ./main.go:15 (1)
cond i == 3
(dlv) clear 1
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
Breakpoint 2 at 0x4aa476 for main.main() ./main.go:15 (1)
cond i == 3
(dlv) clearall
Breakpoint 2 cleared at 0x4aa476 for main.main() ./main.go:15
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
断点上附加条件
condition 命令可以已有的断点上加上命令,有连个参数 condition breakId condition 第一个参数是已有断点的id(用breakpoints 可以知道),第二个是附加条件。
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4aa3f8 for main.main() ./main.go:12 (0)
Breakpoint 2 at 0x4aa476 for main.main() ./main.go:15 (0)
(dlv) condition 2 i==3
(dlv) c
> main.main() ./main.go:12 (hits goroutine(1):1 total:1) (PC: 0x4aa3f8)
7: func test(a int) int {
8: d :=3
9: a = d+3
10: return a
11: }
=> 12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
17: test(a)
(dlv) c
> main.main() ./main.go:15 (hits goroutine(1):1 total:1) (PC: 0x4aa476)
10: return a
11: }
12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
=> 15: a++
16: }
17: test(a)
18: go func() {
19: a +=1
20: b -=1
(dlv) locals
b = 3
a = 4
i = 3 //condition 命令已经生效
打印变量
locals打印局部变量vars打印所有包变量vars 包名打印包变量print打印变量值
(dlv) c
> main.main() ./main.go:17 (hits goroutine(1):1 total:1) (PC: 0x4aa4a0)
12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
=> 17: test(a)
18: go func() {
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
(dlv) locals
b = 3
a = 6
(dlv) print a
6
(dlv) print &a
(*int)(0xc0000ac010)
(dlv) print b
3
(dlv)
单步执行
next单步执行(遇到子函数不进入,只执行本文件下一行代码)step单步进入执行(遇到子函数会进入子函数)。stepout退出(执行完)当前函数到该函数被调用的下一行代码。
这边需要注意 next和step的区别
(dlv) b main.go:17
Breakpoint 1 set at 0x4aa4a0 for main.main() ./main.go:17
(dlv) c
> main.main() ./main.go:17 (hits goroutine(1):1 total:1) (PC: 0x4aa4a0)
12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
=> 17: test(a)
18: go func() {
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
(dlv) n
> main.main() ./main.go:18 (PC: 0x4aa4b9)
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
17: test(a)
=> 18: go func() {
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
23: }()
(dlv) r
Process restarted with PID 706
(dlv) c
> main.main() ./main.go:17 (hits goroutine(1):1 total:1) (PC: 0x4aa4a0)
12: func main() {
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
=> 17: test(a)
18: go func() {
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
(dlv) s
> main.test() ./main.go:7 (PC: 0x4aa3a0)
2:
3: import (
4: "fmt"
5: "time"
6: )
=> 7: func test(a int) int {
8: d :=3
9: a = d+3
10: return a
11: }
12: func main() {
(dlv) n
> main.test() ./main.go:8 (PC: 0x4aa3b7)
3: import (
4: "fmt"
5: "time"
6: )
7: func test(a int) int {
=> 8: d :=3
9: a = d+3
10: return a
11: }
12: func main() {
13: a ,b:=1,3
(dlv) so
> main.main() ./main.go:18 (PC: 0x4aa4b9)
Values returned:
~r1: 6
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
17: test(a)
=> 18: go func() {
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
23: }()
(dlv)
goroutine 切换
我们在调试的时候不能同事看到所有goroutine的情况,默认我们追踪的代码是在main goroutine中,我们有时候想看看非main goroutine的情况,就需要goroutine 切换的命令。
goroutines打印所有的goroutinegoroutine切换指定id的goroutine执行
Breakpoint 1 cleared at 0x4aa4a0 for main.main() ./main.go:17
(dlv) b main.go:18
(dlv) c
> main.main() ./main.go:18 (hits goroutine(1):1 total:1) (PC: 0x4aa4b9)
13: a ,b:=1,3
14: for i:=0;i<5;i++ {
15: a++
16: }
17: test(a)
=> 18: go func() {
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
23: }()
(dlv) n
> main.main() ./main.go:24 (PC: 0x4aa4f7)
19: a +=1
20: b -=1
21: time.Sleep(10e9)
22: b +=1
23: }()
=> 24: fmt.Println(a,b)
25: time.Sleep(100e9)
26: }
(dlv) goroutines
* Goroutine 1 - User: ./main.go:24 main.main (0x4aa4f7) (thread 1903)
Goroutine 2 - User: /home/wida/go/src/runtime/proc.go:305 runtime.gopark (0x42faab)
Goroutine 3 - User: /home/wida/go/src/runtime/proc.go:305 runtime.gopark (0x42faab)
Goroutine 4 - User: /home/wida/go/src/runtime/proc.go:305 runtime.gopark (0x42faab)
Goroutine 5 - User: /home/wida/go/src/runtime/lock_futex.go:228 runtime.notetsleepg (0x40ab14)
Goroutine 17 - User: /home/wida/go/src/runtime/proc.go:305 runtime.gopark (0x42faab)
Goroutine 18 - User: /home/wida/go/src/runtime/time.go:105 time.Sleep (0x44aa51)
[7 goroutines]
(dlv) goroutine 18
Switched from 1 to 18 (thread 1903)
重启和退出
restart重新执行程序,设置的断点还会在。exit退出调试程序。
(dlv) b main.main
Breakpoint 1 set at 0x4aa3f8 for main.main() ./main.go:12
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4aa3f8 for main.main() ./main.go:12 (0)
(dlv) restart
Process restarted with PID 2622
(dlv) breakpoints
Breakpoint runtime-fatal-throw at 0x42ddc0 for runtime.fatalthrow() /home/wida/go/src/runtime/panic.go:820 (0)
Breakpoint unrecovered-panic at 0x42de30 for runtime.fatalpanic() /home/wida/go/src/runtime/panic.go:847 (0)
print runtime.curg._panic.arg
Breakpoint 1 at 0x4aa3f8 for main.main() ./main.go:12 (0)
(dlv) exit
调试汇编代码
regs [-a]查看cpu通用寄存器值,加上-a的话查看所有的寄存器的值。disassemble查看汇编代码(inter 风格的汇编)
我们在原先代码目录添加一个汇编代码文件 test.s
#include "textflag.h"
TEXT ·add(SB), NOSPLIT, $0-8
MOVQ a+0(FP), AX
MOVQ b+8(FP), BX
ADDQ AX, BX
MOVQ BX, ret+16(FP)
RET
修改下main.go的代码
package main
import (
"fmt"
"time"
)
func add(a ,b int) int
func test(a int) int {
d :=3
a = d+3
return a
}
func main() {
a ,b:=1,3
for i:=0;i<5;i++ {
a++
}
test(a)
add(a,b)
go func() {
a +=1
b -=1
time.Sleep(10e9)
b +=1
}()
fmt.Println(a,b)
time.Sleep(100e9)
}
(dlv) c
> main.main() ./main.go:20 (hits goroutine(1):1 total:1) (PC: 0x4aa4bf)
15: a ,b:=1,3
16: for i:=0;i<5;i++ {
17: a++
18: }
19: test(a)
=> 20: add(a,b)
21: go func() {
22: a +=1
23: b -=1
24: time.Sleep(10e9)
25: b +=1
(dlv) s
> main.add() ./test.s:4 (PC: 0x4aa6d0)
1: #include "textflag.h"
2:
3: TEXT ·add(SB), NOSPLIT, $0-8
=> 4: MOVQ a+0(FP), AX
5: MOVQ b+8(FP), BX
6: ADDQ AX, BX
7: MOVQ BX, ret+16(FP)
8: RET
(dlv) regs
Rip = 0x00000000004aa6d0
Rsp = 0x000000c000075e78
Rax = 0x0000000000000003
...
(dlv) n
> main.add() ./test.s:5 (PC: 0x4aa6d5)
1: #include "textflag.h"
2:
3: TEXT ·add(SB), NOSPLIT, $0-8
4: MOVQ a+0(FP), AX
=> 5: MOVQ b+8(FP), BX
6: ADDQ AX, BX
7: MOVQ BX, ret+16(FP)
8: RET
(dlv) regs
Rip = 0x00000000004aa6d5
Rsp = 0x000000c000075e78
Rax = 0x0000000000000006 //rax 寄存器的值已经发送变化
...
(dlv) regs -a
Rip = 0x00000000004aa6d5
Rsp = 0x000000c000075e78
Rax = 0x0000000000000006
...
XMM0 = 0x00000000000000000000000000000000 v2_int={ 0000000000000000 0000000000000000 } v4_int={ 00000000 00000000 00000000 00000000 } v8_int={ 0000 0000 0000 0000 0000 0000 0000 0000 } v16_int={ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 } v2_float={ 0 0 } v4_float={ 0 0 0 0 }
...
(dlv)
(dlv) c
> main.main() ./main.go:20 (hits goroutine(1):1 total:1) (PC: 0x4aa4bf)
15: a ,b:=1,3
16: for i:=0;i<5;i++ {
17: a++
18: }
19: test(a)
=> 20: add(a,b)
21: go func() {
22: a +=1
23: b -=1
24: time.Sleep(10e9)
25: b +=1
(dlv) disassemble
TEXT main.main(SB) /home/wida/gocode/debugger-demo/main.go
main.go:14 0x4aa3e0 64488b0c25f8ffffff mov rcx, qword ptr fs:[0xfffffff8]
main.go:14 0x4aa3e9 488d4424a8 lea rax, ptr [rsp-0x58]
main.go:14 0x4aa3ee 483b4110 cmp rax, qword ptr [rcx+0x10]
...
dlv exec 调试可执行文件
我们先编译我们的项目
$ go build
$ ll
drwxr-xr-x 3 wida wida 4096 10月 22 11:01 .
drwxr-xr-x 44 wida wida 4096 10月 21 18:25 ..
-rwxr-xr-x 1 wida wida 2013047 10月 22 11:01 debugger-demo
-rw-r--r-- 1 wida wida 30 10月 21 18:38 go.mod
-rw-r--r-- 1 wida wida 288 10月 22 10:40 main.go
-rw-r--r-- 1 wida wida 143 10月 22 10:41 test.s
$ dlv exec ./debugger-demo
(dlv) b main.main
Breakpoint 1 set at 0x48cef3 for main.main() ./main.go:14
(dlv) c
> main.main() ./main.go:14 (hits goroutine(1):1 total:1) (PC: 0x48cef3)
Warning: debugging optimized function
9: func test(a int) int {
10: d :=3
11: a = d+3
12: return a
13: }
=> 14: func main() {
15: a ,b:=1,3
16: for i:=0;i<5;i++ {
17: a++
18: }
19: test(a)
(dlv) q
后面的调试方式和dlv exec类似。
参考文档
GODEBUG追踪调度器
go可执行程序本身能产生一些profiling和debug信息(默认情况下不会产生)。设置环境变量GODEBUG能让go的可执行程序运行时打印调试信息(标准错误输出),你可以通过改变环境变量GODEBUG的值收集go调度器和垃圾回收器的概要或者详细信息。只需要设置环境变量GODEBUG就可以,不需要你在go build的时候设置任何编译选项开关。
本小节我们翻译下scheduler-tracing-in-go博文来介绍下利用环境变量GODEBUG追踪go的调度器。
我们设计一个程序来验证下。
package main
import (
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go work(&wg)
}
wg.Wait()
// Wait to see the global run queue deplete.
time.Sleep(3 * time.Second)
}
func work(wg *sync.WaitGroup) {
time.Sleep(time.Second)
var counter int
for i := 0; i < 1e10; i++ {
counter++
}
wg.Done()
}
我们先编译go程序
$ go build -o test
查看摘要信息
我们设置下GOMAXPROCS和GODEBUG 运行test程序,我们的程序本身没有任何输出,你会发现终端打印如下内容
$ GOMAXPROCS=1 GODEBUG=schedtrace=1000 ./test
SCHED 0ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=0 runqueue=0 [2]
SCHED 1000ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=1 runqueue=0 [9]
SCHED 2007ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=1 runqueue=0 [9]
SCHED 3013ms: gomaxprocs=1 idleprocs=0 threads=3 spinningthreads=0 idlethreads=1 runqueue=0 [9]
我们GOMAXPROCS=1代表设置go processors为1, GODEBUG=schedtrace=1000跟踪调度器信息,每秒钟打印一次。
我们来解释下日志字段的含义
1000ms : 代表程序运行开始到现在运行的毫秒数,我们每秒钟打印一次,所以这个数组大概都是1000的整数倍
gomaxprocs=1 : 我们设置的gomaxprocs=1
idleprocs=0 : processors空闲数,0空闲(1个正在忙).
threads=3 : go runtime 管理的系统线程数,1个为processor专用,另外2个为go runtime使用
idlethreads=1 : 空闲线程数量 1个空闲(2个忙).
runqueue=0 : 全局goroutine等待运行队列数,0代表全局队列为空,全部到local的等待运行queue.
[9] : 本地goroutines等待运行队列数(这边processors为1,所以只有一个数值,多个processors时就有多个数值).9 个goroutines 在本地队列等待运行.
我们在程序运行时我们收集了很多有用的摘要信息,我们看下在运行后1秒的那个tracing信息,我们可以看到1个goroutine正在运行,其他9个在本地等待运行队列中等待。
上图中processors用P表示,threads(系统线程)用M表示,goroutine用G表示,图中展示全局等待运行队列为空,processors正在运行一个goroutine(G4),其他9个在本地等待运行队列中。
接下来我们看下多个processors下运行的情况。
$ GOMAXPROCS=2 GODEBUG=schedtrace=1000 ./test
SCHED 0ms: gomaxprocs=2 idleprocs=1 threads=2 spinningthreads=0 idlethreads=0 runqueue=0 [0 0]
SCHED 1002ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=1 idlethreads=1 runqueue=0 [0 4]
SCHED 2006ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=0 [4 4]
…
SCHED 6024ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=2 [3 3]
…
SCHED 10049ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=4 [2 2]
…
SCHED 13067ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=6 [1 1]
…
SCHED 17084ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=8 [0 0]
…
SCHED 21100ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
我们看下第2秒的情况
SCHED 2002ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=0 [4 4]
2002ms : 程序运行了2秒.
gomaxprocs=2 : 配置了2个`processors`.
threads=4 : 4个系统线程 2个给processors,剩下2个go runtime使用.
idlethreads=1 : 1个空闲系统线程 (3个系统线程忙).
idleprocs=0 : 0个processors空闲(2个都在忙).
runqueue=0 : 所以的 goroutine都分配到本地运行等待队列中,全局等待队列为空.
[4 4] : 每一个本地等待运行队列都分配了4个goroutine。

上图展示了第二秒的时候goroutine是如何被processors运行,同样能看到每个goroutine在本地等待运行队列的情况。8个goroutine在本地等待运行队列等待,每个本地等待运行队列包含4个goroutine。
再看下第6秒的情况
SCHED 6024ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=2 [3 3]
idleprocs=0 : 0 个`processors`空闲 (2 processors busy).
runqueue=2 : 2 个goroutines 到全局等待运行队列中(等待被回收)
[3 3] : 每个本地等待运行队列中有3个goroutines在等待.
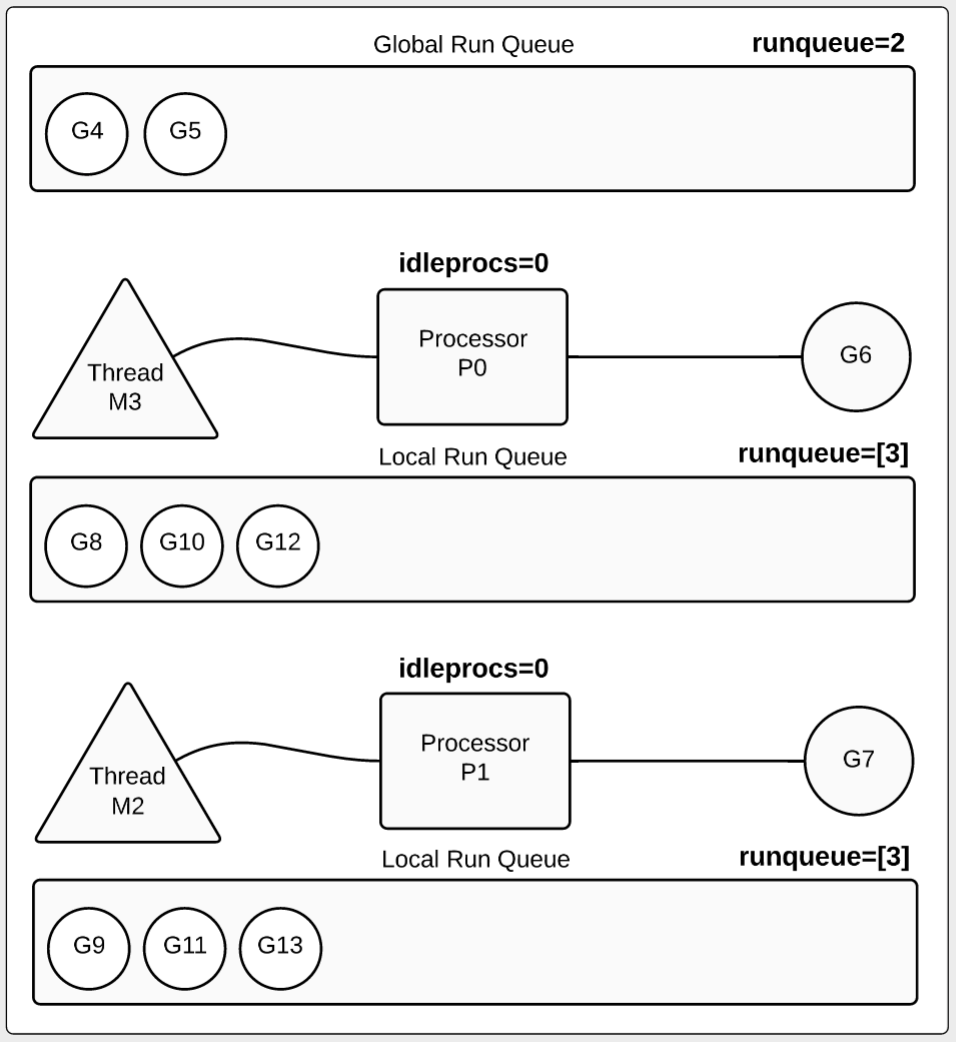
上图展示了第6秒时的一些变化,有2个goroutine执行完成后被移动回到全局等待运行队列。有两个goruntine在运行正在运行,每个P各运行一个。每个本地等待运行队列中各有有3个goroutine。
注意:
大多数情况下,`goroutine`在即将被销毁前不会被移动到全局等待运行队列。本文中的例子比较特殊。`goroutine`中是一个for循环,没有调用其他函数,并且运行总时长超过10毫秒。10毫秒是go调度器的一个调度指标,超过10毫秒的执行时长的`goroutine`,go调度器就会尝试抢占(preempt,其实就是要暂时挂起`goroutine`,让其他`goroutine`执行的意思)这个`goroutine`。本例子中的`goroutine`由于没有调用其他函数(go编译器一般会在函数中加入汇编指令用来挂起`goroutine`来配合调度器调度),所以不能被抢占。当程序运行到`wg.Done`的时候被抢占了,所以这个`goroutine`被移动到全局等待运行队列中,随后会被销毁。
时间来到第17秒
SCHED 17084ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=8 [0 0]
idleprocs=0 : 0个processors空闲(2个processors忙).
runqueue=8 : 8个goroutines都在全局等待队列中.
[0 0] : 本地等待运行队列都为空
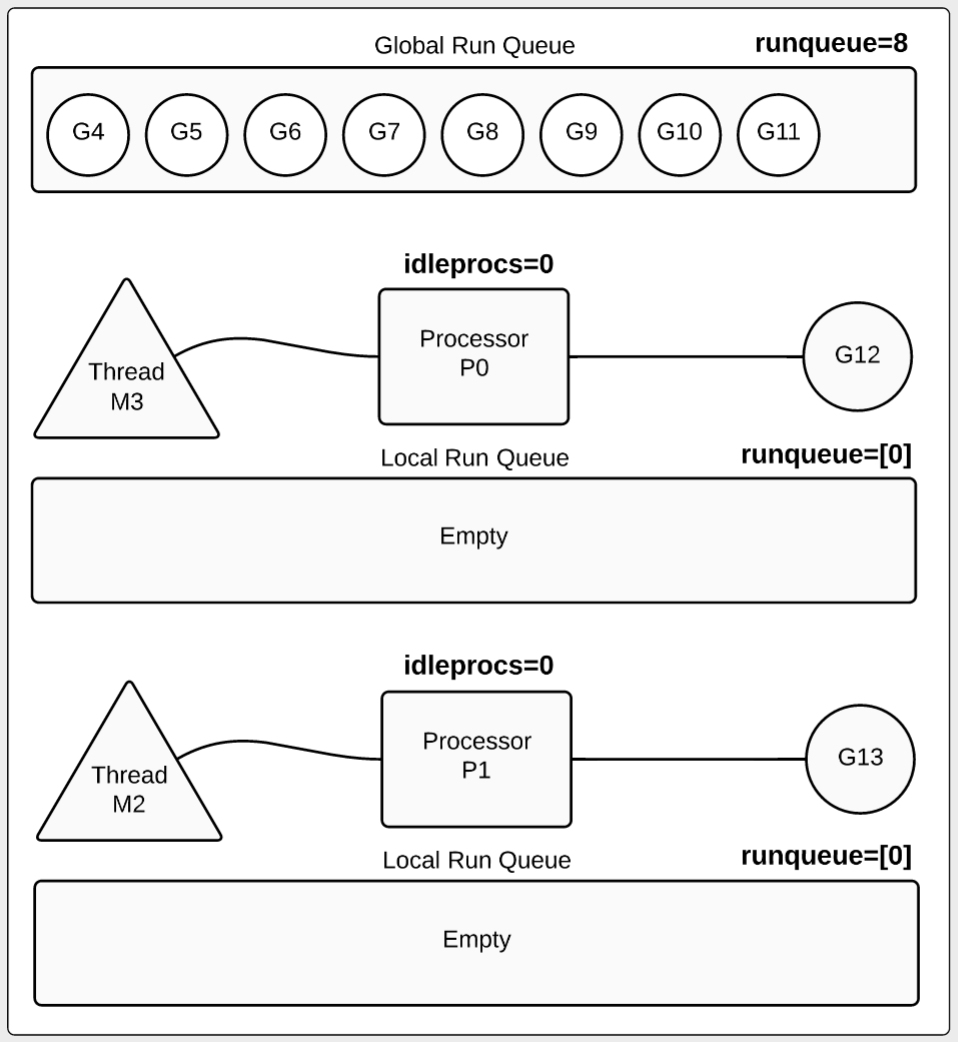
上图中我们看到本地运行队列都为空,还有2个goroutine正在运行,其余8个goroutine都在全局等待运行队列中。
时间来到第21秒
SCHED 21100ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
idleprocs=2 : 2个processors空闲(0个processors忙).
runqueue=0 : 全局运行队列为空(10个goroutine全部被销毁)
[0 0] : 本地等待运行队列都为空
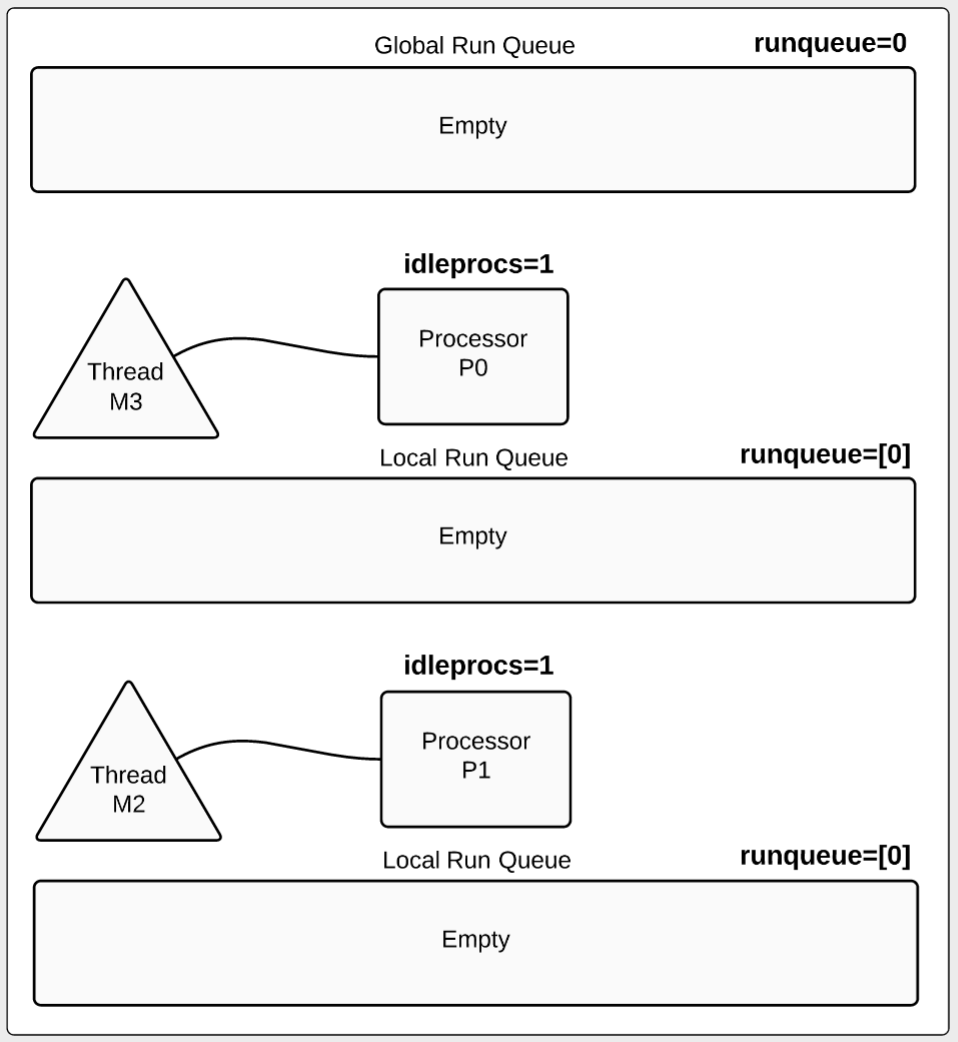
如上图所示,所有的goroutine都已经被销毁。
查看详细信息
调度器的摘要信息通常很有用,但是某些时候你想更深入了解细节,这个时候我们可以加上scheddetail选项,然后程序运行是会打印出每个processor,线程,goroutine的详细调度细节。
我们再用下面的命令运行下程序
$ GOMAXPROCS=2 GODEBUG=schedtrace=1000,scheddetail=1 ./test
这边我们看下第4秒的信息
SCHED 4028ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=0 idlethreads=1 runqueue=2 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0
P0: status=1 schedtick=10 syscalltick=0 m=3 runqsize=3 gfreecnt=0
P1: status=1 schedtick=10 syscalltick=1 m=2 runqsize=3 gfreecnt=0
M3: p=0 curg=4 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M2: p=1 curg=10 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M1: p=-1 curg=-1 mallocing=0 throwing=0 gcing=0 locks=1 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M0: p=-1 curg=-1 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
G1: status=4(semacquire) m=-1 lockedm=-1
G2: status=4(force gc (idle)) m=-1 lockedm=-1
G3: status=4(GC sweep wait) m=-1 lockedm=-1
G4: status=2(sleep) m=3 lockedm=-1
G5: status=1(sleep) m=-1 lockedm=-1
G6: status=1(stack growth) m=-1 lockedm=-1
G7: status=1(sleep) m=-1 lockedm=-1
G8: status=1(sleep) m=-1 lockedm=-1
G9: status=1(stack growth) m=-1 lockedm=-1
G10: status=2(sleep) m=2 lockedm=-1
G11: status=1(sleep) m=-1 lockedm=-1
G12: status=1(sleep) m=-1 lockedm=-1
G13: status=1(sleep) m=-1 lockedm=-1
G17: status=4(timer goroutine (idle)) m=-1 lockedm=-1
从上面的信息来看,摘要信息没什么变化,但是详细信息多了每个processor,线程,和goroutine的信息行。我们先看下processor的信息
P0: status=1 schedtick=10 syscalltick=0 m=3 runqsize=3 gfreecnt=0
P1: status=1 schedtick=10 syscalltick=1 m=2 runqsize=3 gfreecnt=0
我们设置了GOMAXPROCS=2所以processor的信息只有2行。
再看下线程的信息
M3: p=0 curg=4 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M2: p=1 curg=10 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M1: p=-1 curg=-1 mallocing=0 throwing=0 gcing=0 locks=1 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M0: p=-1 curg=-1 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1
M代表一个系统线程,我们在摘要信息中thread=4,所以会有4条线程信息。详细信息还显示了线程是属于那个processor。
P0: status=1 schedtick=10 syscalltick=0 `m=3` runqsize=3 gfreecnt=0 //m=3
M3: `p=0` curg=4 mallocing=0 throwing=0 gcing=0 locks=0 dying=0 helpgc=0 spinning=0 blocked=0 lockedg=-1 //p=0
我们看到M3绑定到P0,这个绑定关系在两者的详细信息中都有体现。
G代表goroutine,第4秒我们看到目前有14个goroutine, 但是从程序启动开始到打印日志的时候已经创建了17个线程。怎么知道创建了17个线程呢?这是从最后的goroutine的标志G17得来。
G17: status=4(timer goroutine (idle)) m=-1 lockedm=-1
如果该程序继续创建goroutine,我们将看到该数字呈线性增加。如果此程序正在处理Web请求,则可以使用该数字来大致判断已经处理的请求数(仅当程序在处理请求期间不会创建其他goroutine时)。
接下来我们看下main运行的goroutine
G1: status=4(semacquire) m=-1 lockedm=-1
我们可以看到main函数所在goroutine状态是4(status=4(semacquire)),并且被waitgroup.Wait阻塞住。
为了更好地理解goroutine追踪信息,了解每个goroutine状态编号代表什么是很有帮助的,下面是状态代码列表:
status: http://golang.org/src/runtime/
Gidle, // 0
Grunnable, // 1 runnable and on a run queue
Grunning, // 2 running
Gsyscall, // 3 performing a syscall
Gwaiting, // 4 waiting for the runtime
Gmoribund_unused, // 5 currently unused, but hardcoded in gdb scripts
Gdead, // 6 goroutine is dead
Genqueue, // 7 only the Gscanenqueue is used
Gcopystack, // 8 in this state when newstack is moving the stack
对照如上的表格,我们整理下我们创建的10个goroutine,现在我们可以更好的了解它们。
// Goroutines running in a processor. (idleprocs=0)
G4: status=2(sleep) m=3 lockedm=-1 – Thread M3 / Processor P0
G10: status=2(sleep) m=2 lockedm=-1 – Thread M2 / Processor P1
// Goroutines waiting to be run on a particular processor. (runqsize=3)
G5: status=1(sleep) m=-1 lockedm=-1
G7: status=1(sleep) m=-1 lockedm=-1
G8: status=1(sleep) m=-1 lockedm=-1
// Goroutines waiting to be run on a particular processor. (runqsize=3)
G11: status=1(sleep) m=-1 lockedm=-1
G12: status=1(sleep) m=-1 lockedm=-1
G13: status=1(sleep) m=-1 lockedm=-1
// Goroutines waiting on the global run queue. (runqueue=2)
G6: status=1(stack growth) m=-1 lockedm=-1
G9: status=1(stack growth) m=-1 lockedm=-1
对go调度器调度有基本的了解,能帮助我们更好的了解go程序中processor(P),线程(M),goroutine(G)的调度过程以及他们的运行状态。
总结
本小节我们通过翻译scheduler-tracing-in-go了解通过环境变量GODEBUG追踪go调度器。
GODEBUG环境变量是go程序运行时追踪go调度器利器。它可以告诉你很多有关go程序运行方式的信息。go调度器的追踪对你优化go程序,甚至判断是否有goroutine泄露都很有帮助。
参考资料
GODEBUG追踪GC
上一小节我们介绍了通过设置环境变量GODEBUG追踪go调度器的信息的方法。其实GODEBUG还可以追踪goGC,本小节将介绍如何用GODEBUG追踪go的GC。
我们先写一个demo程序
package main
import (
"runtime/debug"
"time"
)
func main() {
num := 500000
var bigmap = make(map[int]*[512]float32)
for i := 0;i < num;i++ {
bigmap[i] = &[512]float32{float32(i)}
}
println(len(bigmap))
time.Sleep(15e9)
for i := 0;i < num;i++ {
delete(bigmap,i)
}
debug.FreeOSMemory()
time.Sleep(1000e9)
}
我先编译下
$ go build -o test
追踪go GC
运行GODEBUG=gctrace=1
$ GODEBUG=gctrace=1 ./test
会显示如下信息
...
500000
gc 10 @16.335s 0%: 0.004+1.0+0.004 ms clock, 0.016+0/1.0/2.9+0.016 ms cpu, 1006->1006->0 MB, 1784 MB goal, 4 P (forced)
scvg: 1 MB released
scvg: inuse: 835, idle: 188, sys: 1023, released: 17, consumed: 1005 (MB)
forced scvg: 1005 MB released
forced scvg: inuse: 0, idle: 1023, sys: 1023, released: 1023, consumed: 0 (MB)
我们可以在go runtime 看到gc日志的格式的相关信息
gc日志
格式如下:
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
gc 10 @16.335s 0%: 0.004+1.0+0.004 ms clock, 0.016+0/1.0/2.9+0.016 ms cpu, 1006->1006->0 MB, 1784 MB goal, 4 P (forced)
- gc 10: gc的流水号,从1开始自增
- @16.335s: 从程序开始到当前打印是的耗时
- 0%: 程序开始到当前CPU时间百分比
- 0.004+1.0+0.004 ms clock: 0.004表示STW时间;1.0表示并发标记用的时间;0.004表示markTermination阶段的STW时间
- 0.016+0/1.0/2.9+0.016 ms cpu: 0.016表示整个进程在mark阶段STW停顿时间;0/1.0/2.9有三块信息,0是mutator assists占用的时间,2.9是dedicated mark workers+fractional mark worker占用的时间,2.9+是idle mark workers占用的时间。0.016 ms表示整个进程在markTermination阶段STW停顿时间(0.050 * 8)。
- 1006->1006->0 MB: GC开始、GC结束、存活的heap大小
- 1784 MB goal:下一次触发GC的内存占用阈值
- 4 P: 处理器数量
- (forced): 可能没有,代表程序中runtime.GC() 被调用
scvg日志:
go语言把内存归还给操作系统的过程叫scavenging,scvg日志记录的就是这个过程的日志信息。 scvg 每次会打印两条日志 格式:
scvg#: # MB released printed only if non-zero
scvg#: inuse: # idle: # sys: # released: # consumed: # (MB)
scvg: 1 MB released
scvg: inuse: 835, idle: 188, sys: 1023, released: 17, consumed: 1005 (MB)
- 1 MB released: 返回给系统1m 内存
- inuse: 正在使用的
- idle :空闲的
- sys : 系统映射内存
- released:已经归还给系统的内存
- consumed:已经向操作系统申请的内存
我们看到debug.FreeOSMemory()运行后
forced scvg: 1005 MB released
forced scvg: inuse: 0, idle: 1023, sys: 1023, released: 1023, consumed: 0 (MB)
这个时候released内存是1023m,说明go语言已经正常把内存交给操作系统了了。可是RSS信息显示go仍然占用这这个内存。

这又是为什么?golang在把内存规划给类linux系统(linux-like)时发送的指令是建议回收指令,那么系统可以根据自己负载情况决定是否真的回收。
在go runtime中我们找到一段如下的文字。
madvdontneed: setting madvdontneed=1 will use MADV_DONTNEED
instead of MADV_FREE on Linux when returning memory to the
kernel. This is less efficient, but causes RSS numbers to drop
more quickly.
翻译一下:
madvdontneed:如果设置GODEBUG=madvdontneed=1,golang归还内存给操作系统的方式将使用MADV_DONTNEED,而不是Linux上的MADV_FREE的方式。虽然MADV_DONTNEED效率较低,但会程序RSS下降得更快速。
动手试一试
$ GODEBUG=madvdontneed=1 go run main.go
 这下RSS正常了。
这下RSS正常了。
MADV_FREE和MADV_DONTNEED
MADV 是linux kernel的内存回收的方式,有两种变体(MADV_FREE和MADV_DONTNEED,可以参考 MADV_FREE functionality文档。
总结
本小节介绍了用GODEBUG追踪go GC的方法,介绍了tracing日志的格式。GC的追踪在排查程序内存占用问题特别有用。
go 调优之火焰图
火焰图(flame graphs)是一种程序函数调用栈深度和耗时比例直观可交互展示的工具。
一图胜千言
如上图展示,火焰图展示程序中被频繁调用的函数和耗时占比。这边展示的是一章截图,原图是svg是可交互的,比如我们想具体看某个函数中子函数的情况你可以点击那个函数。结果如下

在go生态中,早期我们经常会用go-torch来生成这样的图。从go1.11后 go tool pprof 就已经集成了这个功能,非常方便我们使用。
演示代码
package main
import (
"encoding/json"
"fmt"
"net/http"
_ "net/http/pprof"
"time"
)
func fn1() {
b := fn2()
fmt.Println(fn3(b))
}
func fn2() (b []byte) {
b, _ = json.Marshal(map[string]int{
"a": 22,
"bb": 333,
})
return
}
func fn3(b []byte) int {
var m map[string]int
json.Unmarshal(b, &m)
if len(m) > 0 {
return m["a"]
}
return 0
}
func main() {
go func() {
for {
fn1()
time.Sleep(1e8)
}
}()
panic(http.ListenAndServe(":8080", nil))
}
如上面代码所示,需要在代码中引入_ "net/http/pprof" 然后需要起一个http服务 http.ListenAndServe(":8080", nil),就这样比较少的代码侵入。
运行
$ go run main.go
然后你可以在浏览器中访问,http://127.0.01:8080/debug/pprof/
看到如下的信息
/debug/pprof/
Types of profiles available:
Count Profile
1 allocs
0 block
0 cmdline
5 goroutine
1 heap
0 mutex
0 profile
7 threadcreate
0 trace
...
ok 测试程序没问题了
生成火焰图
step 1
运行如下的命令,下载profile文件
go tool pprof http://127.0.0.1:8080/debug/pprof/profile -seconds 5
step 2
运行如下命令生成火焰图
go tool pprof -http=:8081 ~/pprof/pprof.main.samples.cpu.001.pb.gz
注意:这个时候可能会提升缺少 graphviz ubuntu和debian 使用 apt-get install graphviz 安装
用浏览器访问 http://localhost:8081/ui/flamegraph这个时候就能看到火焰图了。
调优过程
我们生成火焰图的目录是为了直观的发现程序中最耗时的函数,然后想办法去优化它, 优化后继续生成火焰图看是否有效果,然后再去发现下一个最耗时的函数,重复上面的步骤直到整个程序达到你满意的性能。
go http2 开发
开发使用的https证书
https证书对开发人员不是很友好,安装开发环境的证书都相对麻烦了点。这边介绍一个小工具mkcert。
安装 mkcert
本文以Ubuntu和Debian系统为例:
- 安装依赖
sudo apt install libnss3-tools - 下载mkcert
- 生产证书
./mkcert -key-file key.pem -cert-file cert.pem example.com *.example.com localhost 127.0.0.1 ::1 - 添加本地信任
mkcert -install
golang http2
go 官方的http2包在拓展网络库中,使用起来标准库中的http没啥区别。需要主要的是http2的包同时支持http2和http1当发现client端不支持http2的时候会使用http1。
我们新建一个项目http2test,同时把上面生成的cert.pem和key.pem拷贝到目录下面
$ tree
.
├── cert.pem
├── go.mod
├── go.sum
├── key.pem
└── main.go
package main
import (
"log"
"net/http"
"time"
"golang.org/x/net/http2"
)
const idleTimeout = 5 * time.Minute
const activeTimeout = 10 * time.Minute
func main() {
var srv http.Server
//http2.VerboseLogs = true
srv.Addr = ":8972"
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hello http2"))
})
http2.ConfigureServer(&srv, &http2.Server{})
log.Fatal(srv.ListenAndServeTLS("cert.pem", "key.pem"))
}
运行程序
$ go run main.go
然后用chrome浏览器可以正常浏览 https://localhost:8972/
我们使用curl工具测试下http2和http1 client的情况:
$ curl --http2 https://localhost:8972/ -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8972 (#0)
...
> GET / HTTP/2
> Host: localhost:8972
> User-Agent: curl/7.60.0
> Accept: */*
>
* Connection state changed (MAX_CONCURRENT_STREAMS == 250)!
< HTTP/2 200
< content-type: text/plain; charset=utf-8
< content-length: 11
< date: Thu, 12 Dec 2019 11:13:26 GMT
<
* Connection #0 to host localhost left intact
hello http2
我们看到使用http2协议返回正常。
我们在看下使用http1的情况:
$curl --http1.1 https://localhost:8972/ -v
* Trying 127.0.0.1...
...
* SSL connection using TLSv1.2 / ECDHE-RSA-AES128-GCM-SHA256
* ALPN, server accepted to use http/1.1
* Server certificate:
* subject: O=mkcert development certificate; OU=wida@wida
* start date: Jun 1 00:00:00 2019 GMT
* expire date: Dec 12 10:47:26 2029 GMT
* subjectAltName: host "localhost" matched cert's "localhost"
* issuer: O=mkcert development CA; OU=wida@wida; CN=mkcert wida@wida
* SSL certificate verify ok.
> GET / HTTP/1.1
> Host: localhost:8972
> User-Agent: curl/7.60.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 12 Dec 2019 11:56:46 GMT
< Content-Length: 11
< Content-Type: text/plain; charset=utf-8
<
* Connection #0 to host localhost left intact
hello http2
正常返回内容hello http2但是我们看到的是走的http1.1的协议。
go 语言结构图优雅初始化的一种方式
该方式存于go-micro,go-grpc中
package main
import "fmt"
type Config struct {
A string
B int
}
type option func(c *Config)
func NewConig(o ...option) *Config{
c := Config{
A:"wida",
B:3,
}
for _,op:= range o {
op(&c)
}
return &c
}
func writeA(a string) option{
return func(c *Config) {
c.A=a
}
}
func writeB(b int) option{
return func(c *Config) {
c.B = b
}
}
func main() {
a := writeA("amy")
b := writeB(6)
c := NewConig(a,b)
fmt.Println(c)
}
运行:
# go run main.go
&{amy 6}
go程序物理内存占用高的问题
最近手头上的一个go项目,go版本是go1.13.1。项目上线后发现rss(Resident Set Size实际使用物理内存)很快就飚7g(服务器内存8g),而且很长时间内存都不下降。一开始还以为的内存泄露了。后来经过一番折腾才发现这个不是内存泄露。
GODEBUG
先写一个模拟程序
package main
import (
"runtime/debug"
"time"
)
func main() {
num := 500000
var bigmap = make(map[int]*[512]float32)
for i := 0;i < num;i++ {
bigmap[i] = &[512]float32{float32(i)}
}
println(len(bigmap))
time.Sleep(15e9)
for i := 0;i < num;i++ {
delete(bigmap,i)
}
debug.FreeOSMemory()
time.Sleep(1000e9)
}
$ go run main.go
然后打开终端
$ top -p pid

在系统负载比较低的时候,你会看到程序的Res 1G 左右,而且一直不变化。这个有点反直觉,我们向系统申请的50万个512维float32型的数组,后面实际上是已经删除了, 按理说golang的gc应该回收这个1g的内存,然后归还给系统才对,可是这样子的事情并没有发生。 到底发生了什么?我们去追踪下gc日志。
$ GODEBUG=gctrace=1 go run main.go
...
500000
gc 10 @16.335s 0%: 0.004+1.0+0.004 ms clock, 0.016+0/1.0/2.9+0.016 ms cpu, 1006->1006->0 MB, 1784 MB goal, 4 P (forced)
scvg: 1 MB released
scvg: inuse: 835, idle: 188, sys: 1023, released: 17, consumed: 1005 (MB)
forced scvg: 1005 MB released
forced scvg: inuse: 0, idle: 1023, sys: 1023, released: 1023, consumed: 0 (MB)
我们可以在go runtime 看到gc日志的格式的相关信息
gc日志
格式如下:
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
gc 10 @16.335s 0%: 0.004+1.0+0.004 ms clock, 0.016+0/1.0/2.9+0.016 ms cpu, 1006->1006->0 MB, 1784 MB goal, 4 P (forced)
- gc 10: gc的流水号,从1开始自增
- @16.335s: 从程序开始到当前打印是的耗时
- 0%: 程序开始到当前CPU时间百分比
- 0.004+1.0+0.004 ms clock: 0.004表示STW时间;1.0表示并发标记用的时间;0.004表示markTermination阶段的STW时间
- 0.016+0/1.0/2.9+0.016 ms cpu: 0.016表示整个进程在mark阶段STW停顿时间;0/1.0/2.9有三块信息,0是mutator assists占用的时间,2.9是dedicated mark workers+fractional mark worker占用的时间,2.9+是idle mark workers占用的时间。0.016 ms表示整个进程在markTermination阶段STW停顿时间(0.050 * 8)。
- 1006->1006->0 MB: GC开始、GC结束、存活的heap大小
- 1784 MB goal:下一次触发GC的内存占用阈值
- 4 P: 处理器数量
- (forced): 可能没有,代表程序中runtime.GC() 被调用
scvg日志:
go语言把内存归还给操作系统的过程叫scavenging,scvg日志记录的就是这个过程的日志信息。 scvg 每次会打印两条日志 格式:
scvg#: # MB released printed only if non-zero
scvg#: inuse: # idle: # sys: # released: # consumed: # (MB)
scvg: 1 MB released
scvg: inuse: 835, idle: 188, sys: 1023, released: 17, consumed: 1005 (MB)
- 1 MB released: 返回给系统1m 内存
- inuse: 正在使用的
- idle :空闲的
- sys : 系统映射内存
- released:已经归还给系统的内存
- consumed:已经向操作系统申请的内存
所以从上面的介绍来看,最后的归还日志
forced scvg: inuse: 0, idle: 1023, sys: 1023, released: 1023, consumed: 0 (MB)
说明go语言已经正常把内存交给操作系统了了。可是RSS信息显示go仍然占用这这个内存。 这又是为什么? 在go runtime中我们找到一段如下的文字。
madvdontneed: setting madvdontneed=1 will use MADV_DONTNEED
instead of MADV_FREE on Linux when returning memory to the
kernel. This is less efficient, but causes RSS numbers to drop
more quickly.
翻译一下:
madvdontneed:如果设置GODEBUG=madvdontneed=1,golang归还内存给操作系统的方式将使用MADV_DONTNEED,而不是Linux上的MADV_FREE的方式。虽然MADV_DONTNEED效率较低,但会程序RSS下降得更快速。
动手试一试
$ GODEBUG=madvdontneed=1 go run main.go
 这下RSS正常了。
这下RSS正常了。
MADV_FREE和MADV_DONTNEED
MADV 是linux kernel的内存回收的方式,有两种变体(MADV_FREE和MADV_DONTNEED,可以参考 MADV_FREE functionality文档。
简单来说
- MADV_FREE将内存页(page)延迟回收。当内核内存紧张时,这些内存页将会被优先回收,如果应用程序在页回收后又再次访问,内核将会返回一个新的并设置为0的页。而如果内核内存充裕时,标识为MADV_FREE的页会仍然存在,后续的访问会清掉延迟释放的标志位并正常读取原来的数据。
- MADV_DONTNEED告诉内核这段内存今后"很可能"用不到了,其映射的物理内存尽管拿去好了,因此物理内存可以回收以做它用,但虚拟空间还留着,下次访问时会产生缺页中断,这个缺页中断会触发重新申请物理内存的操作。
go1.12之后采用了MADV_FREE的方式,这样子个go程序和内核间的内存交互会更加高效,但是带来的一个副作用就是rss下降的比较慢(系统资源充裕时,甚至你感觉不到他是在下降)。在关注 top 信息的时候,别只关注RES和%MEM,还要关注下buff/cache。在系统资源紧张的时候MADV_FREE方式标记的内存也会很快回收,并不需要太担心。另外使用GODEBUG=madvdontneed=1会强制使用原先MADV_DONTNEED的方式。
补充
- golang的内存申请方式会比较激进,像map扩容的时候一次申请的比实际需要的多得多。然后在delete map的时候内存不会释放。
- 如果在程序中需要反复申请对象,然后销毁的话,应该使用
sync.pool来重复使用申请过的内存,这样子可以让程序申请的系统内存相对平稳。
参考资料
go 1.18泛型初体验
go.1.18beta版发布,众所周知这个go.1.18版本会默认启用go泛型。这个版本也号称go最大的版本改动。
初识golang的泛型
我们写一个demo来看看go的泛型是长啥样
package main
import (
"fmt"
)
type OrderTypes interface {
~int | ~float32 | ~string
}
func max[T OrderTypes](x, y T) T {
if x > y {
return x
}
return y
}
func main() {
fmt.Println(max(1, 11), max("abc", "eff"))
}
ok run 一下代码
$ go run main.go
11 eff
~int | ~float32 | ~string我们看到了新的语法,~是新的操作符,主要用来做类型约束使用, ~int代表类型约束为int类型,~int | ~float32 | ~string则代表约束为 int 或者 float32 或者 string。上面额例子中,这三个类型刚好是可以比较的能进行 ">" 操作的。
当然上面的代码是演示用的,在真正的项目中我们应该使用标准constraints提供的Ordered来做约束。
import (
"constraints"
)
func max[T constraints.Ordered](x, y T) T {
if x > y {
return x
}
return y
}
constraints标准库定义了一下常用的类型约束,如Ordered,Signed,Unsigned,Integer,Float。
提高生产力的泛型
我们通过下面的例子来看看泛型,如何提高我们的生产力。我们将为所有slice类型添加三件套map,reduce,filter
func Map[Elem1, Elem2 any](s []Elem1, f func(Elem1) Elem2) []Elem2 {
r := make([]Elem2, len(s))
for i, v := range s {
r[i] = f(v)
}
return r
}
func Reduce[Elem1, Elem2 any](s []Elem1, initializer Elem2, f func(Elem2, Elem1) Elem2) Elem2 {
r := initializer
for _, v := range s {
r = f(r, v)
}
return r
}
func Filter[Elem any](s []Elem, f func(Elem) bool) []Elem {
var r []Elem
for _, v := range s {
if f(v) {
r = append(r, v)
}
}
return r
}
func Silce() {
sliceA := []int{3, 99, 31, 63}
//通过sliceA 生成sliceB
sliceB := Map(sliceA, func(e int) float32 {
return float32(e) + 1.3
})
fmt.Println(sliceB)
//找最大值
max := Reduce(sliceB, 0.0, func(a, b float32) float32 {
if a > b {
return a
}
return b
})
fmt.Println(max)
//过滤sliceA中大于30的组成新的slice
sliceC := Filter(sliceA, func(e int) bool {
if e > 30 {
return true
}
return false
})
fmt.Println(sliceC)
}
func main() {
Silce()
}
$ go run main.go
[4.3 100.3 32.3 64.3]
100.3
[99 31 63]
带泛型的struct
接下来我们看一下带泛型的struct
//定义的时候需要加约束
type Student[T constraints.Unsigned] struct {
Age T
}
//后续struct方法编写的时候 约束就不能写了
func (s *Student[T]) GetAge() T {
return s.Age
}
我们初始化带泛型的结构体
age := uint(3)
s := &Student[uint]{Age: age}
fmt.Println(s.GetAge()) //3
s1 := &Student[uint16]{Age: uint16(age)}
fmt.Println(s1.GetAge()) //3
总结
go的泛型目前还没有官方推荐的最佳实践,标准库的代码也基本没改成泛型。但总归走出支持泛型这一步,后续丰富标准库应该是后面版本的事情了。再看go2代码的时候发现一个有意思的东西--orderedmap。感兴趣的同学可以去看看。
尝试用golang 1.18泛型实现orm
这几天golang社区对泛型的讨论非常多的,一片热火朝天的景象。对我们广大gopher来说总归是好事。
泛型很有可能会颠覆我们之前的很多设计,带着这种疑问和冲动,我准备尝试用golang泛型实现几个orm的常见功能。
本文并没完全实现通用的orm,只是探讨其实现的一种方式提供各位读者做借鉴。
创建Table
虽然golang有了泛型,但是目前在标准库sql底层还没有改造,目前还有很多地方需要用到reflect。
func CreateTable[T any](db *sql.DB) {
var a T
t := reflect.TypeOf(a)
tableName := strings.ToLower(t.Name())
var desc string
for i := 0; i < t.NumField(); i++ {
columnsName := strings.ToLower(t.Field(i).Name)
var columnType string
switch t.Field(i).Type.Kind() {
case reflect.Int:
columnType = "integer"
case reflect.String:
columnType = "text"
}
desc += columnsName + " " + columnType
if i < t.NumField()-1 {
desc += ","
}
}
sqlStmt := fmt.Sprintf(`create table if not exists %s (%s);`, tableName, desc)
_, err := db.Exec(sqlStmt)
if err != nil {
log.Printf("%q: %s\n", err, sqlStmt)
return
}
}
调用方式
type Person struct {
ID int
Name string
Age int
}
type Student struct {
ID int
Name string
No string
}
var db sql.DB
//init db
//...
CreateTable[Person](db)
CreateTable[Student](db)
这个部分跟传统的orm使用上没有太大区别,没办法不使用反射的情况下,泛型的方式可能变得有点繁琐。
写入数据
func Create[T any](db *sql.DB, a T) {
//没有办法这边还是得使用反射
t := reflect.TypeOf(a)
tableName := strings.ToLower(t.Name())
var columns []string
var spacehold []string
for i := 0; i < t.NumField(); i++ {
columns = append(columns, strings.ToLower(t.Field(i).Name))
spacehold = append(spacehold, "?")
}
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
stmt, err := tx.Prepare(
fmt.Sprintf("insert into %s(%s) values(%s)",
tableName,
strings.Join(columns, ","),
strings.Join(spacehold, ",")))
if err != nil {
log.Fatal(err)
}
defer stmt.Close()
v := reflect.ValueOf(a)
var values []any
for i := 0; i < t.NumField(); i++ {
if v.FieldByName(t.Field(i).Name).CanInt() {
values = append(values, v.FieldByName(t.Field(i).Name).Int())
} else {
values = append(values, v.FieldByName(t.Field(i).Name).String())
}
}
_, err = stmt.Exec(values...)
if err != nil {
panic(err)
}
tx.Commit()
}
调用方式
var p1 = Person{
ID: 1,
Name: "wida",
}
Create[Person](db, p1)
var s1 = Student{
ID: 1,
Name: "wida",
No: "1111",
}
Create[Person](db, p1)
Create[Student](db, s1)
和创建table类似,写入数据好像比没有之前的orm有优势。
读取数据
读取数据是非常高频的操作,所以我们稍作封装。
type Client struct {
db *sql.DB
}
type Query[T any] struct {
client *Client
}
func NewQuery[T any](c *Client) *Query[T] {
return &Query[T]{
client: c,
}
}
//反射到struct
func ToStruct[T any](rows *sql.Rows, to T) error {
v := reflect.ValueOf(to)
if v.Elem().Type().Kind() != reflect.Struct {
return errors.New("Expect a struct")
}
scanDest := []any{}
columnNames, _ := rows.Columns()
addrByColumnName := map[string]any{}
for i := 0; i < v.Elem().NumField(); i++ {
oneValue := v.Elem().Field(i)
columnName := strings.ToLower(v.Elem().Type().Field(i).Name)
addrByColumnName[columnName] = oneValue.Addr().Interface()
}
for _, columnName := range columnNames {
scanDest = append(scanDest, addrByColumnName[columnName])
}
return rows.Scan(scanDest...)
}
func (q *Query[T]) FetchAll(ctx context.Context) ([]T, error) {
var items []T
var a T
t := reflect.TypeOf(a)
tableName := strings.ToLower(t.Name())
rows, err := q.client.db.Query("SELECT * FROM " + tableName)
if err != nil {
return nil, err
}
for rows.Next() {
var c T
ToStruct(rows, &c)
items = append(items, c)
}
return items, nil
}
调用方式
var client = &Client{
db: db,
}
{
query := NewQuery[Person](client)
all, err := query.FetchAll(context.Background())
if err != nil {
log.Fatal(err)
}
for _, person := range all {
log.Println(person)
}
}
{
query := NewQuery[Student](client)
all, err := query.FetchAll(context.Background())
if err != nil {
log.Fatal(err)
}
for _, person := range all {
log.Println(person)
}
}
稍微比原先的orm方式有了多一点想象空间,比如 在[T any]做更明确的约束,比如要求实现Filter定制方法。
总结
鉴于本人能力还认证有限,目前还没有发现泛型对orm剧烈的改进和突破的可能。未来如果go对底层sql做出改动,或者实现诸如Rust那种Enum方式,可能会带来更多的惊喜。
go 1.18 workspace使用
go语言对于模块化代码组织方式说实话,不是很理想。从最早被人诟病的go path方式,包括后来稍微有点现代语言模块化方式的go modules也槽点满满。
虽然不尽人意,但是go官方都是没有放弃继续改进模块化代码组织方式。这次go1.18又有了新的一个功能叫做 go workspace,中文翻译为go工作区。
初识 go workspace
什么需要 go workspace?
我看了下工作区的提案,说了go workspace设计的初衷
在一个大项目中依赖多个go mod项目,而我们需要同时修改go mod项目代码,在原先go mod设计中,依赖的项目是只读的。
workspace方式是对现有go mod方式的补充而非替换,workspace会非常方便的在go语言项目组加入本地依赖库。
使用 go workspace
go 命令行增加了 go work来支持go workspace操作。
$ go help work
Go workspace provides access to operations on workspaces.
...
Usage:
go work <command> [arguments]
The commands are:
edit edit go.work from tools or scripts
init initialize workspace file
sync sync workspace build list to modules
use add modules to workspace file
...
我们看到 go work 有四个子命令.
接下来我们创建几个子项目:
$ go work init a b c
go: creating workspace file: no go.mod file exists in directory a
额,报错了。a,b,c 一定是go mod项目才能使用.我们创建a,b,c目录,同时添加go mod
$ tree .
.
├── a
│ └── go.mod
├── b
│ └── go.mod
├── c
└── go.mod
$ go work init a b c
$ tree .
.
├── a
│ └── go.mod
├── b
│ └── go.mod
├── c
│ └── go.mod
└── go.work
ok,工作区创建好了。我们规划下,a目录项目编译可执行文件,b,c为lib库。在工作区目录下a,b,c 三个模块互相可见。
$ tree
.
├── a
│ ├── a.go
│ └── go.mod
├── b
│ ├── b.go
│ └── go.mod
├── c
│ ├── c.go
│ └── go.mod
└── go.work
b.go
import "fmt"
func B() {
fmt.Println("I'm mod b")
}
c.go
package c
import (
"b"
"fmt"
)
func C() {
b.B()
fmt.Println("I'm mod c")
}
a.go
package main
import (
"b"
"c"
)
func main() {
b.B()
c.C()
}
正如你所看到的,a 依赖 b,c依赖b。好了,我们run一下程序
$ go run a/a.go
I'm mod b
I'm mod b
I'm mod c
$ cd a/ #切换到 a目录下看是不是可以
$ go run a.go # a目录下 b,c也对a可见
I'm mod b
I'm mod b
I'm mod c
关于是否提交go.work文件
我们看到很多文章说不建议提交go.work文件,说实话我看到这个建议很奇怪,rust项目管理工具cargo也有类似的工作区概念,cargo的项目肯定会提交工作区文件,因为这个文件本身是项目的一部分。很多文章说go.work这个文件主要用于本地开发,我倒觉得未必有啊,一个多模块,大团队项目不是也可以以工作区项目开发吗?工作区可以非常清楚的划分功能模块,在一个代码仓库里头没啥问题吧。可能这一块会有很多争议,目前用的人少,等大规模运用了在看看情况。